Parses CTC EcoZenith Heater CSV files for input to an influxdb database. I use Grafana for visualizing the heater data:

The script will find all csv files in a directory and parse the data, making it timezone aware and push it to an influxdb database before deleting the csv files. My initial setup (old display) created unlabeled csv files and I had to guess what the data was based on observations. After buying a new display in 2022 (to hook up Modbus) I discovered that the csv files now created is labeled, thus making this process much better.
It has only been tested with my own setup which consist of a CTC EcoZenith i250 immersion heater, CTC EcoAir 400 heat pump and one flow loop of underfloor heating.
All data are labeled in the second row of the csv file. One of my csv files has been uploaded for reference: 20221021.csv
The data has been identified based on observations:
- Tank upper temperature
- Tank lower temperature
- Primary flow 1 temperature
- Return flow temperature
- Heat pump flow temperature
- Heat pump return temperature
- Heater electric power
- L1, L2, L3 and compressor L1 electric current
- Charge pump speed
- Compressor on/off
There are currently 20 more columns in the csv files which are not identified, although unknown_19 resembles the outdoor temperature quite good. I have uploaded one of my csv files for reference: 20200101.CSV
- Carefully open the touch screen lid and add an empty USB flash drive (FAT32) into the USB slot as indicated:
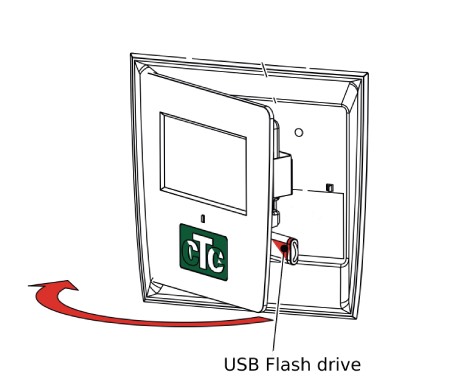
- Start logging by following setting on the touch screen: Installer settings --> Service --> Write log to USB

As far as I have seen the flash drive can be removed and added without having to restart logging from the touch screen.
Prerequisites:
- Python (with pandas, numpy and influxdb) installed
- Running Influxdb instance with a database (v1.x) or bucket (v2.x) called 'ctc'
Instructions for influxdb version 1.x:
- Download the ctc_v1.py file to a directory on your computer
- Change following parameters in the start of the ctc_v1.py file to accomodate your setup:
- Timezone, default is 'CET'
- Influxdb parameters (user/pass and optionally host/port/dbname)
- Copy some csv files from the flash drive to the directory where the ctc.py file is
- Run the script with following command from the directory:
python ctc_v1.py
Instructions for influxdb version 2.x:
- Create an API token with write access to the influxdb bucket
- Download the ctc_v2.py file to a directory on your computer
- Change following parameters in the start of the ctc_v2.py file to accomodate your setup:
- Timezone, default is 'CET'
- Influxdb parameters (url, token, org, optionally bucket)
- Copy some csv files from the flash drive to the directory where the ctc.py file is
- Run the script with one of the two following commands from the directory (based on your setup):
Alt.1: For the old type of display without named columns in the csv:
python ctc_v2.pyAlt.2: For the new type of display with labeled csv:python ctc_v2_new.py
Instructions for influxdb version 2.x and new type of display