In this research project, I tested and analyzed three future scenario generation methods, based on a GPT-3 finetuned davinci, GPT-3.5 prompt-tuned text-davinci-003 and a three-shot prompted GPT-4
Dedicated as my Master's Thesis at Freie University of Berlin, the >>Visionary Machine<< aims to produce human-like/authentic/plausible future scenarios, based on a dataset of scraped human-made scenarios from recognized public institutions concerning the years 2030, 2040, and 2050. The repository makes most sense in this order:
- requirements.txt
- code: contains all steps to gather and process the data and descriptions how to re-create the experiment
- data: contains the raw data sources
- semantic_analysis: contains the analysis of the scenarios/the respective results are in the folders sentiment & topic modeling
- fine-tune: contains description, the json file to fine-tune the model and interactive model evaluation.
- prompt-tune: contains a documentation of prompt-tuning parameters and output
- scenarios: contains the processed data sets
- survey: delphi data anaylsis from foresight expert survey
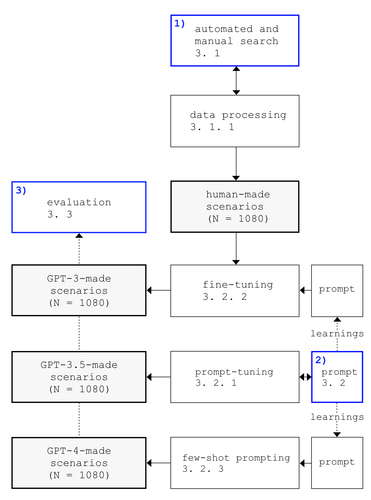
No future research methods represent discipline as much as scenario methods. The development of possible future worlds and the description of the way to them provide the basis for decision-making and at the same time space for speculation. The result is described in scenic texts and makes the future narrative, desirable or warns of it: the so-called scenarios. Not least because of the pandemic, possible futures have found their way into the reality of a critical mass - receiving forecasts every day, while economic, political and civil actors speculated about post-pandemic future scenarios was the prerequisite to harvest the data, since the creation and publication of future scenarios achieved a broad range: A resource of over 1000 human-written scenarios was scraped, parsed and translated into english, forming a data set to fine-tune GPT-3 on, and to promt-tune GPT-3.5 and GPT-4 with.
- +1.300 Human-made scenarios were scraped, cleaned, summarized and analyzed to use them for the fine-tuning of GPT-3.
- The fine-tuned model generated 1.080 scenarios.
- Then I prompt-tuned GPT-3.5 text-davinci-003 on the same keywords and examples deriving from the human-made scenarios and tested the most suitable parameter settings with a small panel of experts, to then generate another 1.080 scenarios with the settings concluded.
- Lastly, I used three-shot prompting with examples from the human-made scenarios for GPT-4 and generate a fourth dataset of 1.080 scenarios.
My research question aims to assess the possibility of automatically generating “authentic” and "human-like" scenarios with the help of Generative Pre-Trained Transformers.
In case authenticity and human-likeness in terms of output is possible: What would AI “imagine”? Is it even able to generate other content than the scenarios that humans have developed prior? And if so, what is the differences between machine-imaginaries and human-made futures?
"This study explores the potential of GPT-3, GPT-3.5, and GPT-4, in generating human-like future scenarios to investigate each model's ability to perceive time. The methodology combines a coding-based experiment and an expert survey. The investigation involves fine- and prompt-tuning GPT-3, prompt-tuning GPT-3.5, and few-shot prompting GPT-4 with human-made future scenarios. The models and output are quantitatively and qualitatively analyzed. The survey invited practitioners from fields of foresight and futurology, AI, and NLP to assess whether differences in output can be identified. This study's findings suggest that GPT-3 and GPT-4 generated scenarios are difficult to distinguish from human-made ones, while GPT-3.5 performed more poorly. Yet none of the models can differentiate time horizons and their respective effects on the future from each other. And while no one knows the shape of things to come, this lack of understanding of a core concept of life invites future investigations."