
🔥🔥 The VideoCrafter2 Large improvements over VideoCrafter1 with limited data. Better Motion, Better Concept Combination!!!
Please Join us and create your own film on Discord/Floor33.

🤗🤗🤗 VideoCrafter is an open-source video generation and editing toolbox for crafting video content.
It currently includes the Text2Video and Image2Video models:
Click the GIF to access the high-resolution video.
 |
 |
 |
| "Tom Cruise's face reflects focus, his eyes filled with purpose and drive." | "A child excitedly swings on a rusty swing set, laughter filling the air." | "A young woman with glasses is jogging in the park wearing a pink headband." |
 |
 |
 |
| "With the style of van gogh, A young couple dances under the moonlight by the lake." | "A rabbit, low-poly game art style" | "Impressionist style, a yellow rubber duck floating on the wave on the sunset" |
 |
 |
 |
 |
 |
 |
 |
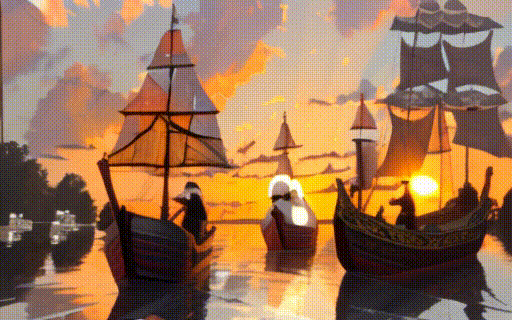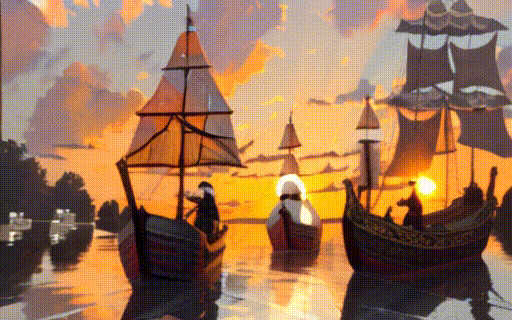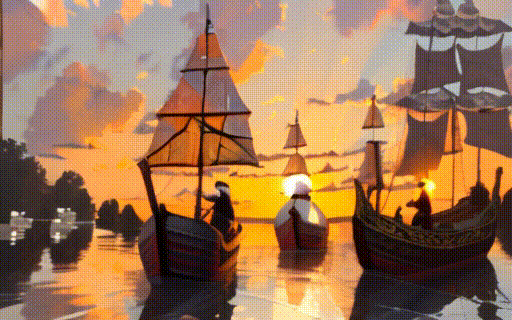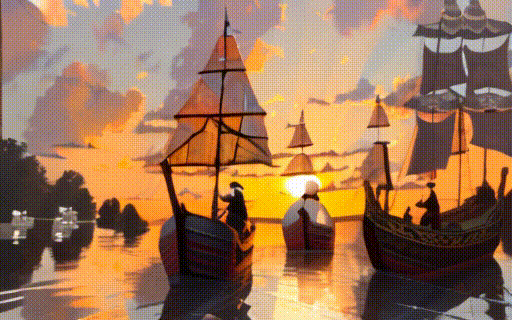 |
| "a black swan swims on the pond" | "a girl is riding a horse fast on grassland" | "a boy sits on a chair facing the sea" | "two galleons moving in the wind at sunset" |
-
[2024.01.26]: 🔥🔥 Release the 512x320 checkpoint of VideoCrafter2.
-
[2024.01.18]: 🔥🔥 Release the VideoCrafter2 and Tech Report!
-
[2023.10.30]: Release VideoCrafter1 Technical Report!
-
[2023.10.13]: 🔥🔥 Release the VideoCrafter1, High Quality Video Generation!
-
[2023.08.14]: Release a new version of VideoCrafter on Discord/Floor33. Please join us to create your own film!
-
[2023.04.18]: Release a VideoControl model with most of the watermarks removed!
-
[2023.04.05]: Release pretrained Text-to-Video models, VideoLora models, and inference code.
| T2V-Models | Resolution | Checkpoints |
|---|---|---|
| VideoCrafter2 | 320x512 | Hugging Face |
| VideoCrafter1 | 576x1024 | Hugging Face |
| VideoCrafter1 | 320x512 | Hugging Face |
| I2V-Models | Resolution | Checkpoints |
|---|---|---|
| VideoCrafter1 | 320x512 | Hugging Face |
conda create -n videocrafter python=3.8.5
conda activate videocrafter
pip install -r requirements.txt- Download pretrained T2V models via Hugging Face, and put the
model.ckptincheckpoints/base_512_v2/model.ckpt. - Input the following commands in terminal.
sh scripts/run_text2video.sh- Download pretrained I2V models via Hugging Face, and put the
model.ckptincheckpoints/i2v_512_v1/model.ckpt. - Input the following commands in terminal.
sh scripts/run_image2video.sh- Download the pretrained T2V and I2V models and put them in the corresponding directory according to the previous guidelines.
- Input the following commands in terminal.
python gradio_app.py😉 VideoCrafter2 Tech report: VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models
😉 VideoCrafter1 Tech report: VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
The technical report is currently unavailable as it is still in preparation. You can cite the paper of our image-to-video model and related base model.
@misc{chen2024videocrafter2,
title={VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models},
author={Haoxin Chen and Yong Zhang and Xiaodong Cun and Menghan Xia and Xintao Wang and Chao Weng and Ying Shan},
year={2024},
eprint={2401.09047},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2023videocrafter1,
title={VideoCrafter1: Open Diffusion Models for High-Quality Video Generation},
author={Haoxin Chen and Menghan Xia and Yingqing He and Yong Zhang and Xiaodong Cun and Shaoshu Yang and Jinbo Xing and Yaofang Liu and Qifeng Chen and Xintao Wang and Chao Weng and Ying Shan},
year={2023},
eprint={2310.19512},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{xing2023dynamicrafter,
title={DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors},
author={Jinbo Xing and Menghan Xia and Yong Zhang and Haoxin Chen and Xintao Wang and Tien-Tsin Wong and Ying Shan},
year={2023},
eprint={2310.12190},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{he2022lvdm,
title={Latent Video Diffusion Models for High-Fidelity Long Video Generation},
author={Yingqing He and Tianyu Yang and Yong Zhang and Ying Shan and Qifeng Chen},
year={2022},
eprint={2211.13221},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Our codebase builds on Stable Diffusion. Thanks the authors for sharing their awesome codebases!
We develop this repository for RESEARCH purposes, so it can only be used for personal/research/non-commercial purposes.