Kaggle의 U.S. Patent Phrase to Phrase Matching모델 코드입니다.
쉽게 하이퍼 파라미터와 모델을 바꿔가며 실험할 수 있도록 모듈화하였습니다. 실행 방법은 아래와 같습니다.
- CPC titles과 train 데이터셋을 결합시켰습니다.
- 아래와 같이 데이터셋을 재구성했습니다.
dataset['anchor'][i] + " [SEP] " + dataset['title'][i] - 실제 데이터셋의 모습은 아래와 같습니다.

- 여기서 dataset['target']과 dataset['text']를 각각 BERT 모델에 넣어 유사도를 학습시켰습니다.
- 일반화 성능 향상을 위해 k-fold를 사용하였습니다.
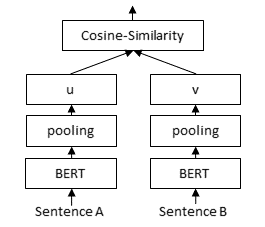
bi-encoder구조를 사용하여 설계했습니다.
default로 모두 미리 설정해놨으며, train_path, test_path의 데이터셋 경로만 설정해주면 됩니다.
$ python preprocessing.py \
--train_path =TRAIN_DATASET_PATH
--test_path =TEST_DATASET_PATH
--test_size =0.1
--max_len =MAX_TOKEN_LENGTH # 256$ python train.py \
--epochs =10$ python inference.py\
--loader_path =TEST_DATALOADER_PATH # test dataloader의 경로(data/test_dataloader.pkl)
--save_sub_path =SAVE_SUBMISSION_FILE_PATH # 저장할 submission.csv 파일 경로Public score: 0.6548
Private score: 0.6434