
👇 클릭 시 유튜브로 이동합니다.
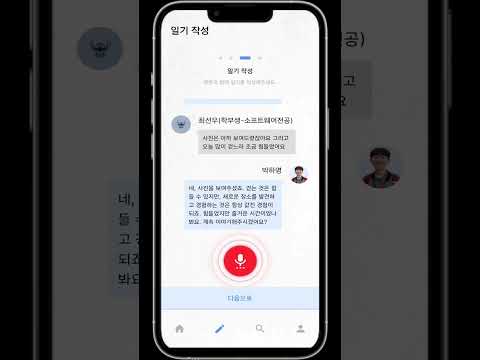
이 프로젝트는 사용자가 AI와 음성으로 대화하며 일기를 작성할 수 있는 서비스를 개발하는 것을 목표로 합니다. 현대인들은 글을 쓰는 것에 부담을 느끼거나 바쁜 일상 속에서 시간이 부족하여 일기 작성을 꾸준히 하지 못하는 경우가 많습니다. 이러한 문제를 해결하기 위해, 본 서비스는 기존 일기 작성 방식이 아닌 음성 인식과 자연어 처리 기술을 활용한 새로운 방식을 제공하여 사용자로 하여금 쉽고 재밌게 일기를 작성할 수 있도록 돕습니다.
본 프로젝트와 서비스는 다음과 같은 기대효과가 있습니다. STT와 TTS를 이용한 음성 대화 기반의 인터페이스를 제공하여 글을 작성하는 부담감을 완화시켜줍니다. 일기는 대규모 언어 모델이 생성해주는 질문에 대답하는 과정을 통해 작성되어 사용자가 일기를 작성할 때 오늘 무엇을 했는지, 어떤 일이 있었는지 생각해야하는 부담을 줄여줍니다. 사용자는 가상의 캐릭터와 대화하며 다른 누군가와 대화하는 것보다 오늘 있었던 일과 자신의 감정을 보다 진솔하게 이야기하고 정리할 수 있습니다.
This project aims to develop a service that allows users to keep a diary by voice communication with AI. Modern people often feel burdened with writing or are unable to consistently keep a diary due to lack of time in their busy daily lives. To solve this problem, this service provides a new method that utilizes speech recognition and natural language processing technology, rather than the traditional method of keeping a diary, to help users write their diary easily and in a fun way.
This project and service have the following expected effects. By providing a voice conversation-based interface using STT and TTS, it relieves the burden of writing. Diary is created by answering questions generated by large language models, reducing the burden of users having to think about what they did today and what happened when writing their diary. Users can talk and organize what happened today and their emotions more honestly than talking to someone else by talking to a virtual character.
- Download docker for your OS
- Docker version 25.0.3
- Docker Compose version v2.24.5-desktop.1
$ cp .env.sample .env
- Set your own value of environment variables in
.envfile - You have to protect your
.envfile from being exposed to the public
- You can change the contents of the Dockerfile to suit your needs.
- Check the volumes' path in the
docker-compose.ymlfile - The path will be mounted to the container
make (up): Run and build containers, networks, volumes and imagesmake down: Stop and remove containers, networks, volumes and imagesmake start: Start containersmake stop: Stop containers
- You can get the status of the containers with
docker ps - You can get the log of the containers with
docker logs <container_name>

보고서와 연구 결과들의 자세한 내용들은 아래의 각 항목 링크에서 확인하실 수 있습니다.
최근 몇 년 동안 웹 애플리케이션을 대상으로 한 사이버 보안 사건의 빈도와 심각성이 크게 증가했습니다.
본 서비스에서 Secure research의 주요 목적은 웹 애플리케이션을 사이버 공격으로부터 사전에 보호하여 허가되지 않은 접근, 사용, 공개, 손상, 변경, 파괴 등으로부터 보호함으로써 무결성, 기밀성, 가용성을 제공하는 것입니다.
현재까지 크게 모델링, 취약점 진단 그리고 보안 기법 적용, 3가지의 조사를 진행했습니다.
Offensive research에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
대규모 언어 모델의 발전으로 인공지능과의 자연스러운 대화가 가능해졌습니다. 이를 이용하여 원하는 유형의 챗봇과 대화하고, 대화를 일기로 작성하는 것이 가능해졌습니다. 본 프로젝트에서는 다양한 AI 기술이 사용되었습니다.
Mystic ML server는 STT, LLM, TTS 기술을 활용하여 챗봇과 대화 및 일기를 생성하는 API를 제공합니다.
ML server에 대한 자세한 내용은 여기에서 확인할 수 있습니다.
LLM에 사용자의 발화를 입력하기 위한 음성 인식 기술이 필요합니다. 이를 위해 Speech-to-Text 모델을 도입하였습니다.
Fast-speech model을 기반으로 한국어를 지원하기 위해 full fine-tuning을 진행했습니다. AI hub의 '한국어음성' 이라는 dataset을 사용하였습니다.
하지만, AI hub dataset 구축 시 사용한 환경과 현재 환경의 차이로 인해 학습이 완료된 후에도 기능적인 요구 사항을 충족하지 못했습니다.
따라서, 연구와 별개로 서비스에선 Open AI Whisper model을 사용하여 STT를 제공하게 됐습니다.
연구에 관한 자세한 내용은 여기에서 확인할 수 있습니다.
챗봇과의 자연스러운 대화 경험과 일기 생성 기능을 제공하기 위해 Large-Language-Model을 도입하였습니다.
Phi-2 모델을 기반으로 QLoRA fine-tuning을 진행했습니다. 하지만, 3B개의 parameter를 가진 SLLM은 성능의 한계가 존재했습니다.
자연스러운 대화 경험에 대한 요구 사항을 충족시키기 위해 Phi-2 모델 연구를 중단하고 GPT 모델을 기반으로하여 Prompt engineering을 진행했습니다.
일기 요약 기능을 제공하기 위해 10B개의 parameter를 가진 EEVE 모델을 기반으로 QLoRA fine-tuning을 진행했습니다.
연구에 관한 자세한 내용은 여기에서 확인할 수 있습니다.
LLM의 Output인 Text를 Speech 즉, 음성 데이터로 변환하는 기술이 필요합니다. 이를 위해 Text-to-Speech 모델을 도입하였습니다.
ⓍTTS 모델을 기반으로 Voice Clonning을 위한 fine-tuning을 진행했습니다.
현재 3명의 음성 데이터를 학습하였고, Streaming Inference latency는 200ms 미만입니다.
연구에 관한 자세한 내용은 여기에서 확인할 수 있습니다.
This project is licensed under the MIT License - see the LICENSE file for details.
장정안 (팀장) @jeongahn

Student ID: 20191658
Email: inetty@kookmin.ac.kr
Role: Offensive Security Researcher, Front-end Developer
• 코드 취약점 분석
• 버그 패턴 분석 및 버그 픽스
• 보안 컨설팅 (서비스 보안 요소 문서화)
• NextJS 프론트 개발
황영서 @younganswer

Student ID: 20191691
Email: younganswer@kookmin.ac.kr
Role: Cloud Engineer, Full Stack Developer
• AWS 서비스 구축
• 시스템 Dockerize
• NextJS, NestJS 풀스택 개발
윤현승 @yoon2000

Student ID: 20191634
Email: yoonhs02@kookmin.ac.kr
Role: Full stack Developer
• 데이터베이스 스키마 구조 설계
• API 문서 작성 및 백엔드 개발
• NextJS를 활용한 프론트엔드 개발
조현준 @hyunjoon0208

Student ID: 20191674
Email: juatis96@kookmin.ac.kr
Role: MLOps
• STT, TTS 모델 구현 및 학습
• AI API 개발 및 배포
최선우 @woonsango

Student ID: 20223149
Email: doldol9080@kookmin.ac.kr
Role: AI Developer
• LLM fine tuning
• Prompt Engineering
• Image Captioning