本工具主要用于快速制作语音数据集,可一键导出VITS等项目所需的训练数据集
注意:你正在查看项目的r1.0分支,本分支将停止更新新功能,仅做维护和留档,未来项目经过重构后会以r2.0分支为主
特色:
GUI界面!
中文文档
支持 音频+字幕/纯音频自动切割 两种方式导入数据(未来会更多)
自动优化了音频的切割效果,(尽量)避免出现断音
可直接导出符合VITS等项目要求的数据集格式,声道数/采样率均可设置
引入语音评测功能,通过为数据打分可以快速从海量数据中筛选出优质数据集
数据库:sqlite、peewee
界面:PySide6
音频处理:FFMPEG、pydub等
进入 github 的 Release 界面 或 gitee 的发行版界面 根据提示下载对应的压缩包双击即可启动程序
-
克隆本项目
gitee:
git clone https://gitee.com/kslizi/sound_dataset_tools2.gitgithub:
git clone https://github.com/kslz/sound_dataset_tools2.git -
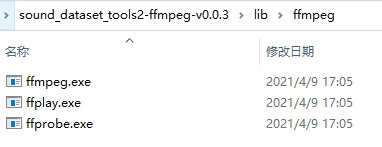
安装ffmpeg
你可以通过配置环境变量,也可以将下载得到的ffmpeg压缩包解压然后在exe根目录下新建lib文件夹,将解压得到的bin文件夹改名为ffmpeg,然后复制到lib目录下,最后的目录结构如图所示
-
安装其他库
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
python main.py
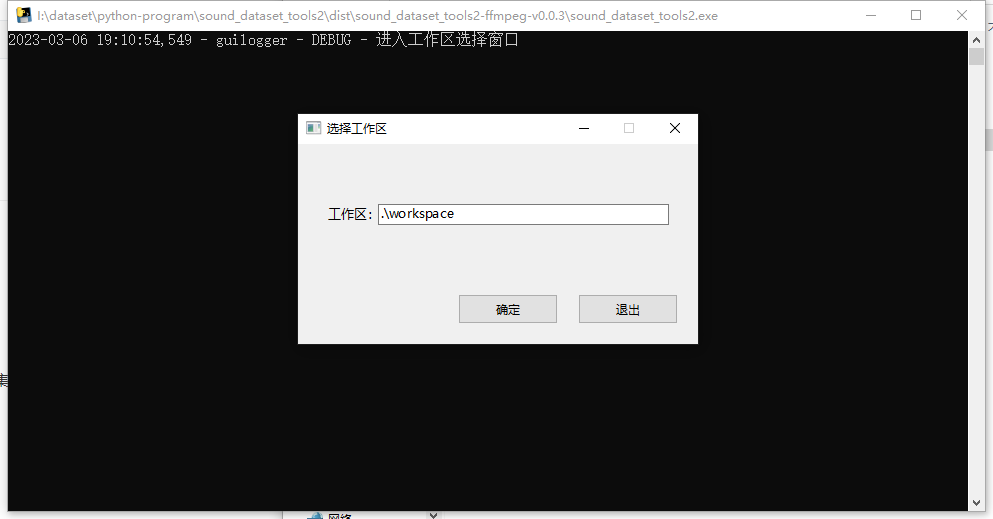
如果你当前的目录空间不足可以指定其他目录,导入的文件、数据库、生成的数据集都会存放在指定目录中
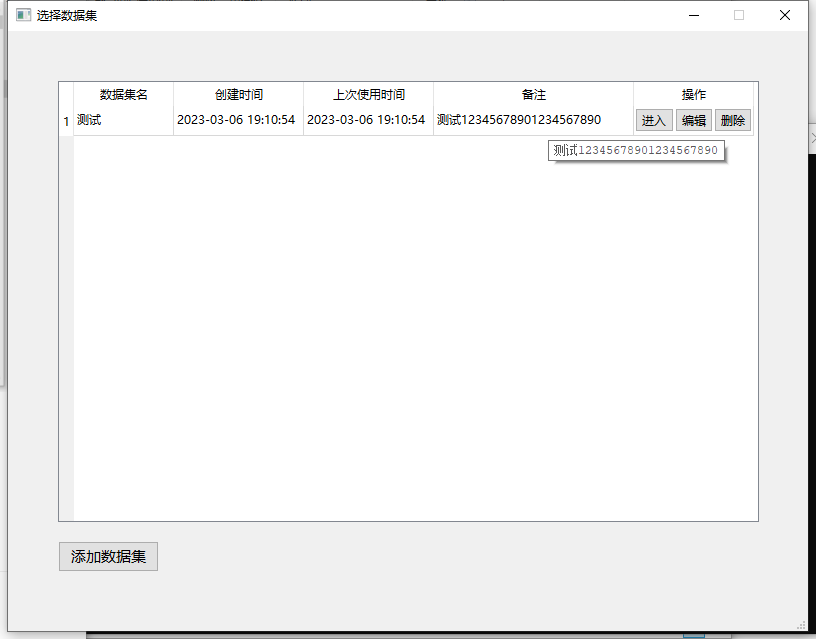
你可以在这里添加,修改,删除数据集。每个数据集之间互相独立。点击进入按钮,进入数据集。
在此你可以对数据进行导入、导出、处理等操作
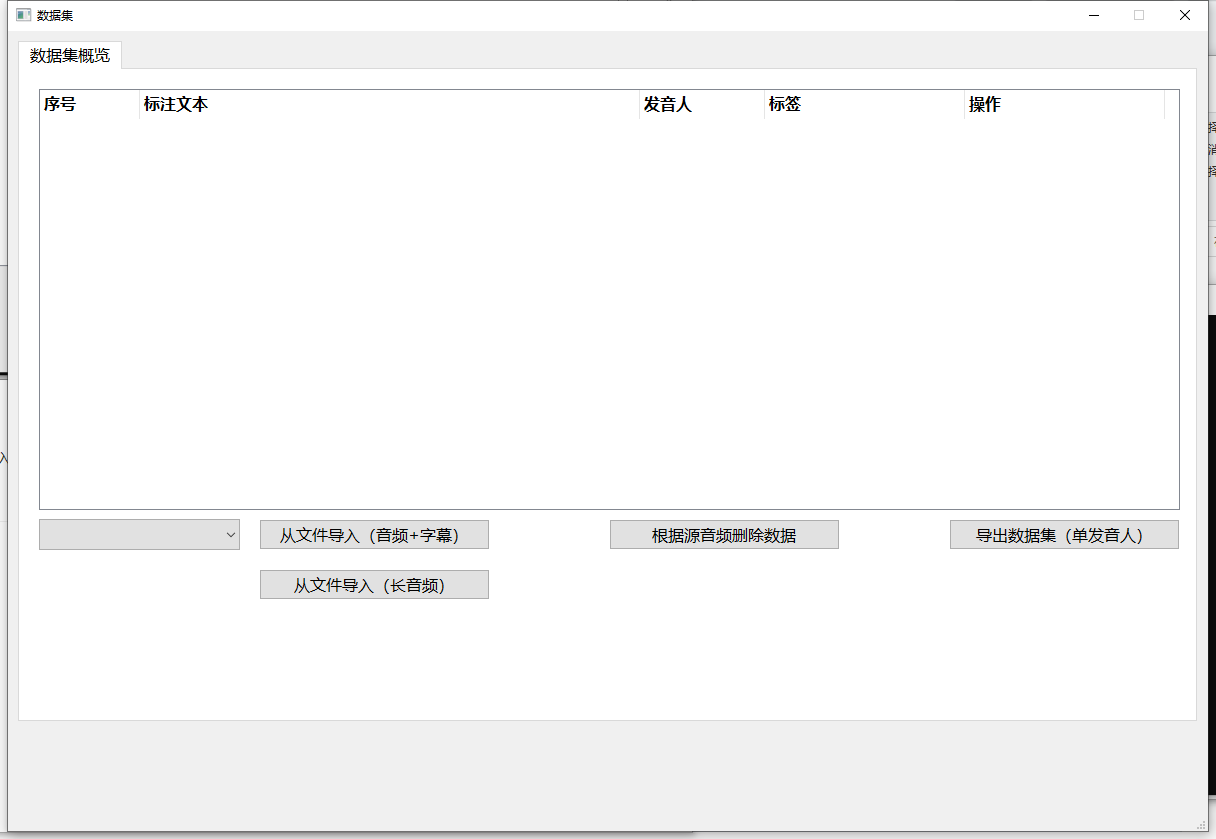
注意:所有导入数据的方式都经过了自动优化,关于自动优化的具体逻辑请见文末。
点击按钮,在弹窗中选择预先处理好的音频和字幕文件,支持视频文件和几乎所有(ffmpeg支持的)格式的音频文件导入,同时请输入发音人。关于字幕的获取请参见文末。
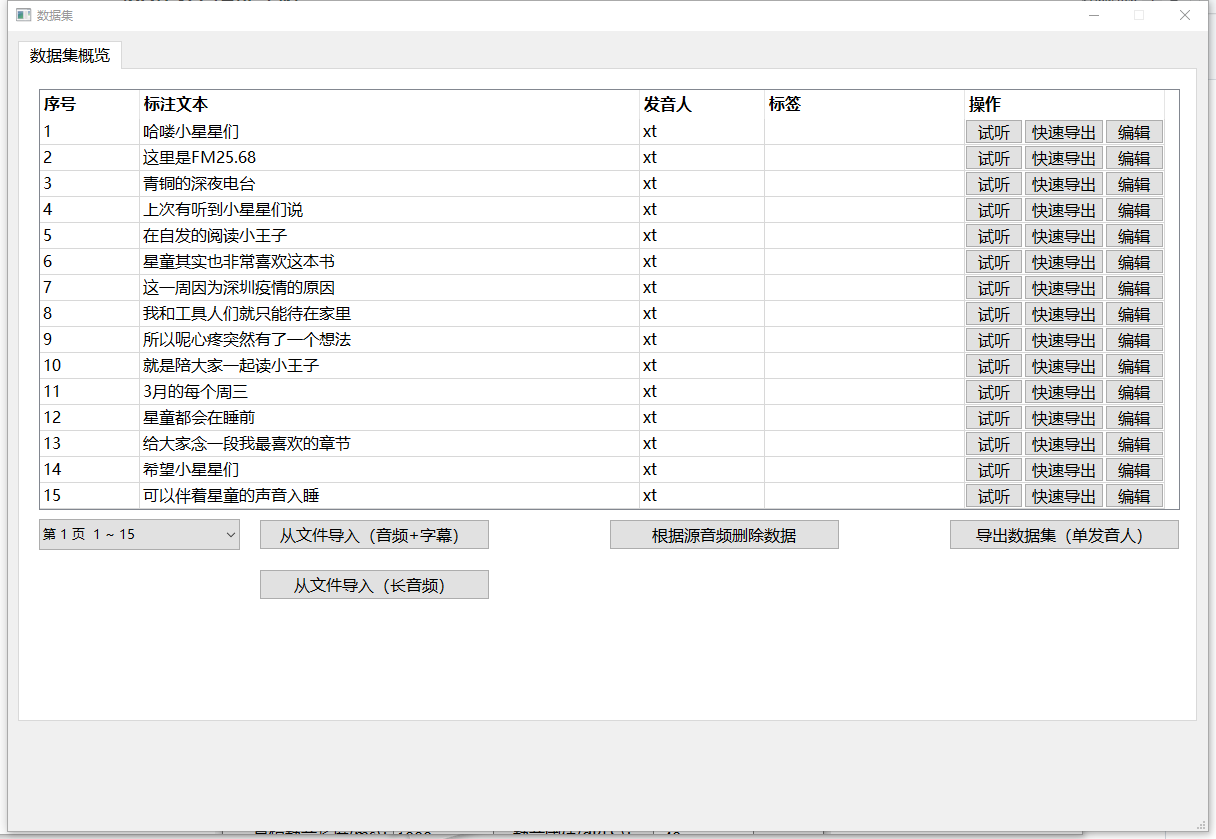
导入后的界面如图所示,你可以在左侧的下拉框中选择翻页,也可以点击试听音频段
点击快速导出后会将当前音频导出至 .\workspace\output\fastoutput\ 目录下
点击按钮,在弹窗中选择预先处理好的音频文件,支持视频文件和几乎所有(ffmpeg支持的)格式的音频文件导入,同时请输入合适的发音人、最短静音长度、静音阈值信息
最短静音长度:当静音长度达到这个数值时进行一次裁切
静音阈值:当音频响度低于这个数值时则视为静音,如果你的音频底噪很低,可以适当调低此值获得更好的结果,反之则提高。
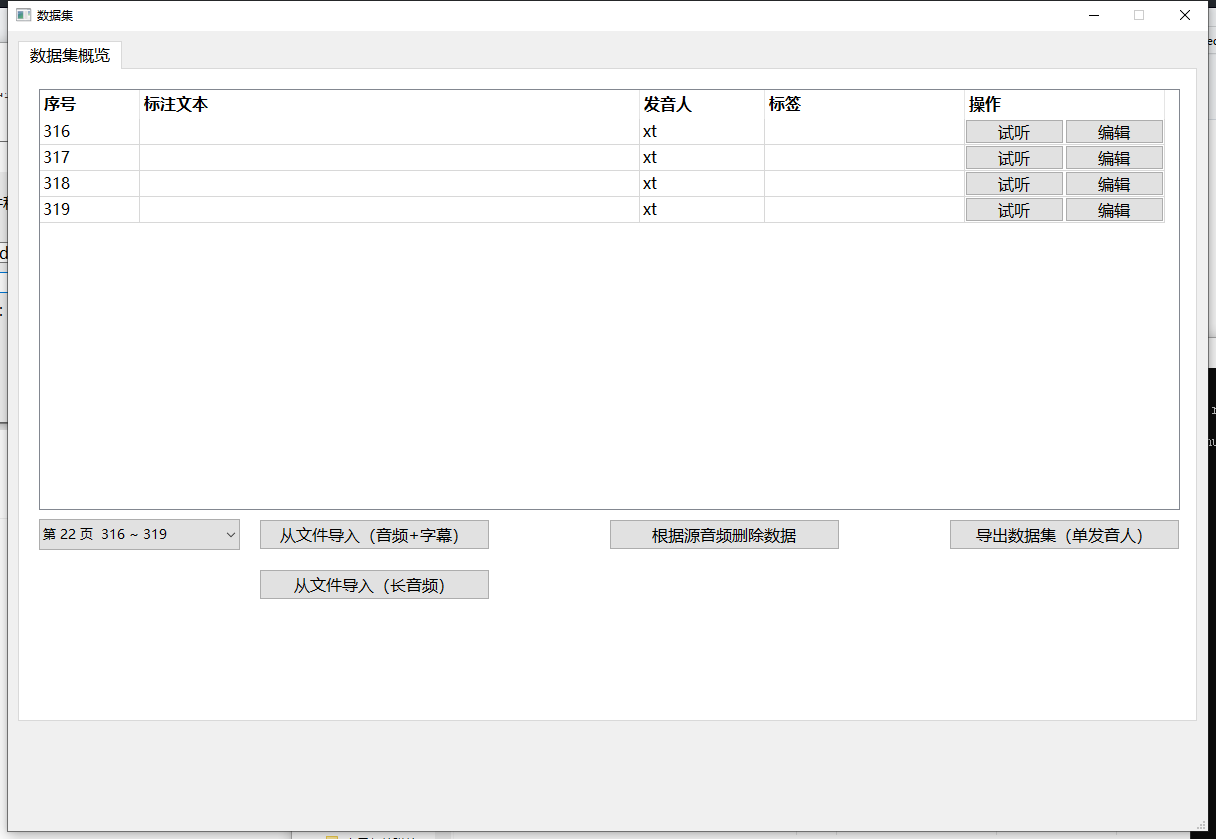
导入后的界面如图所示,需要注意的是因为只有短音频,所以裁切出的音频段没有标注文本,将在未来引入语音识别以进行自动标注。
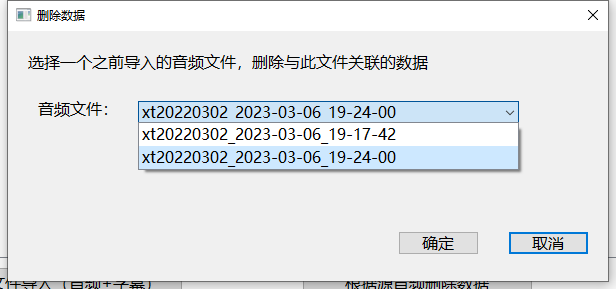
点击按钮后选择一个当前数据集中数据对应的音频,点击确定后音频本身和相关联的数据都会被删除
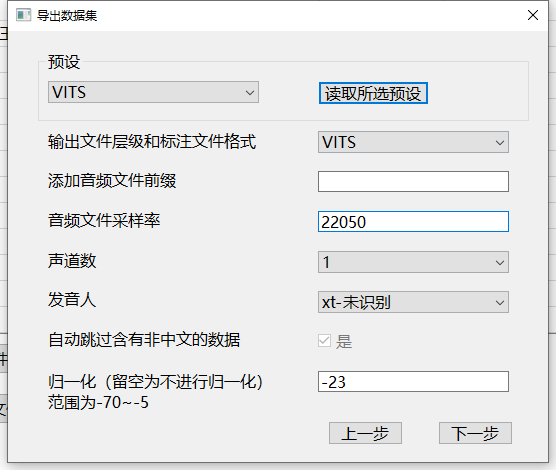
点击按钮后选择参数,你也可以选择对应预设然后点击应用按钮应用预设,如果你不了解这些值的含义使用默认即可。
注:
归一化:即响度匹配,会按照所输入的值进行音频音量进行自动缩放
目前的导出逻辑中将跳过标注文本中包含英文或数字的数据,不过如果有标注文本为空,仍会进行导出
点击下一步即可进行数据集导出,窗口可能会卡一下,请耐心等待。
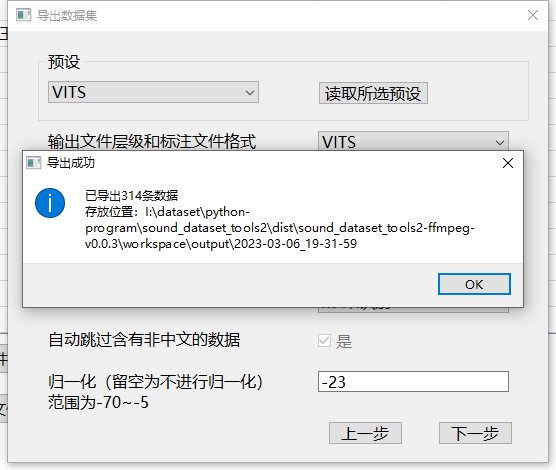
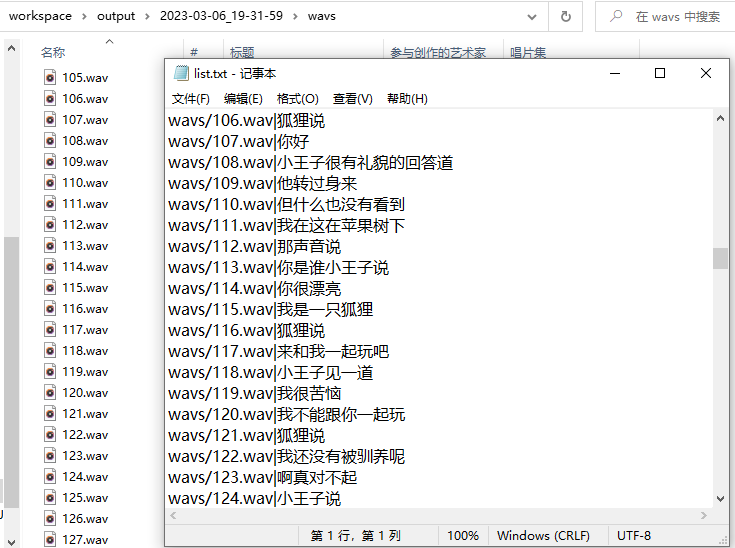
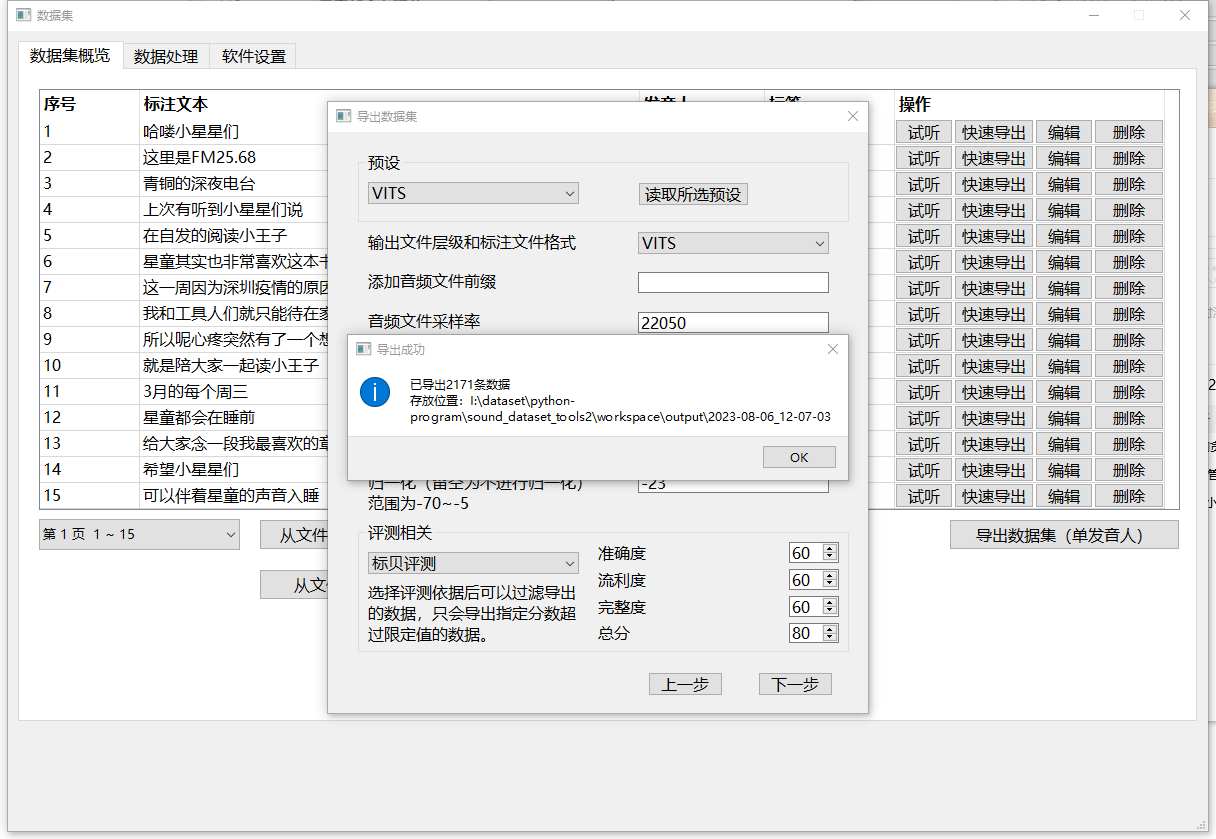
导出后的文件可在对应目录找到
语音评测功能可以通过商用评测接口为语句打分,以实现快速挑选优质数据的功能。
目前已接入标贝语音评测接口
首先进入软件设置-授权管理页面,点击添加按钮,输入名称等字段,应用类型选择语音评测。
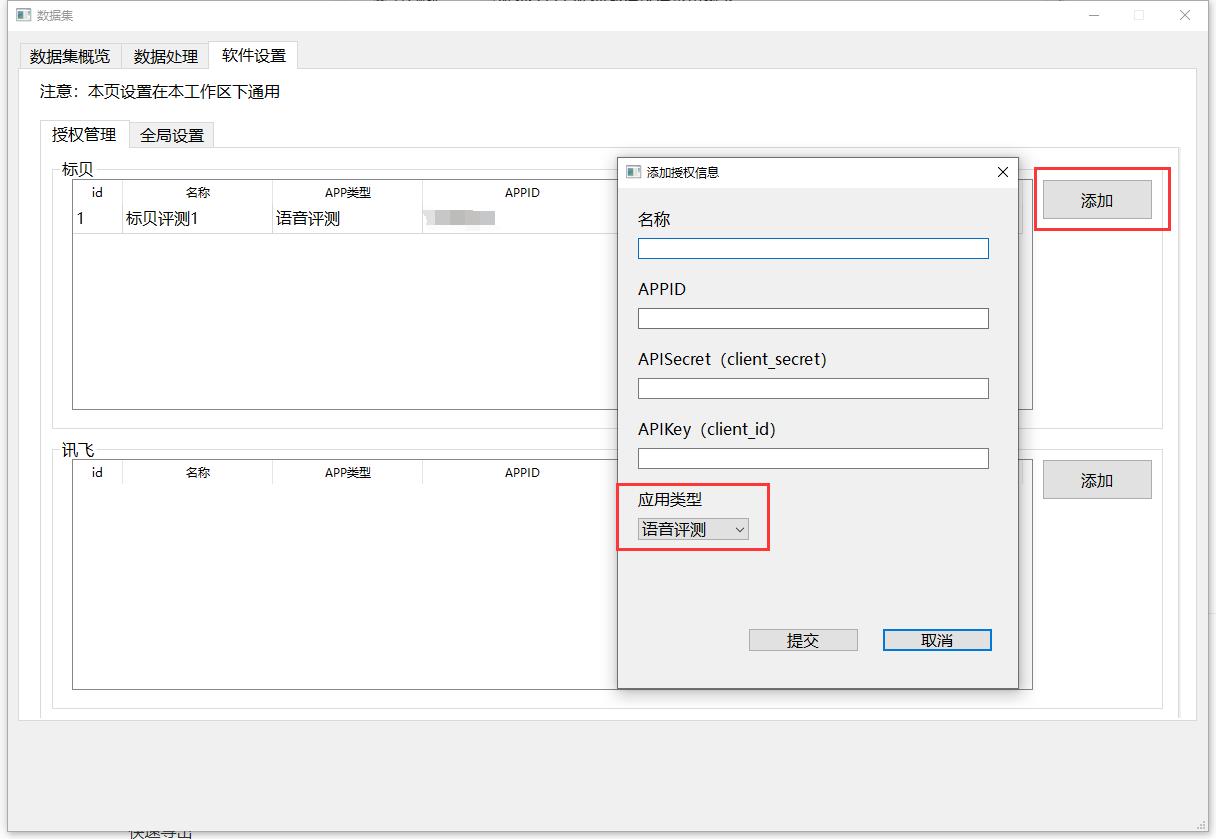
标贝相关字段请进入 标贝开放平台-语音评测页面 开通服务后查看(目前为免费试用期,想白嫖的尽快)
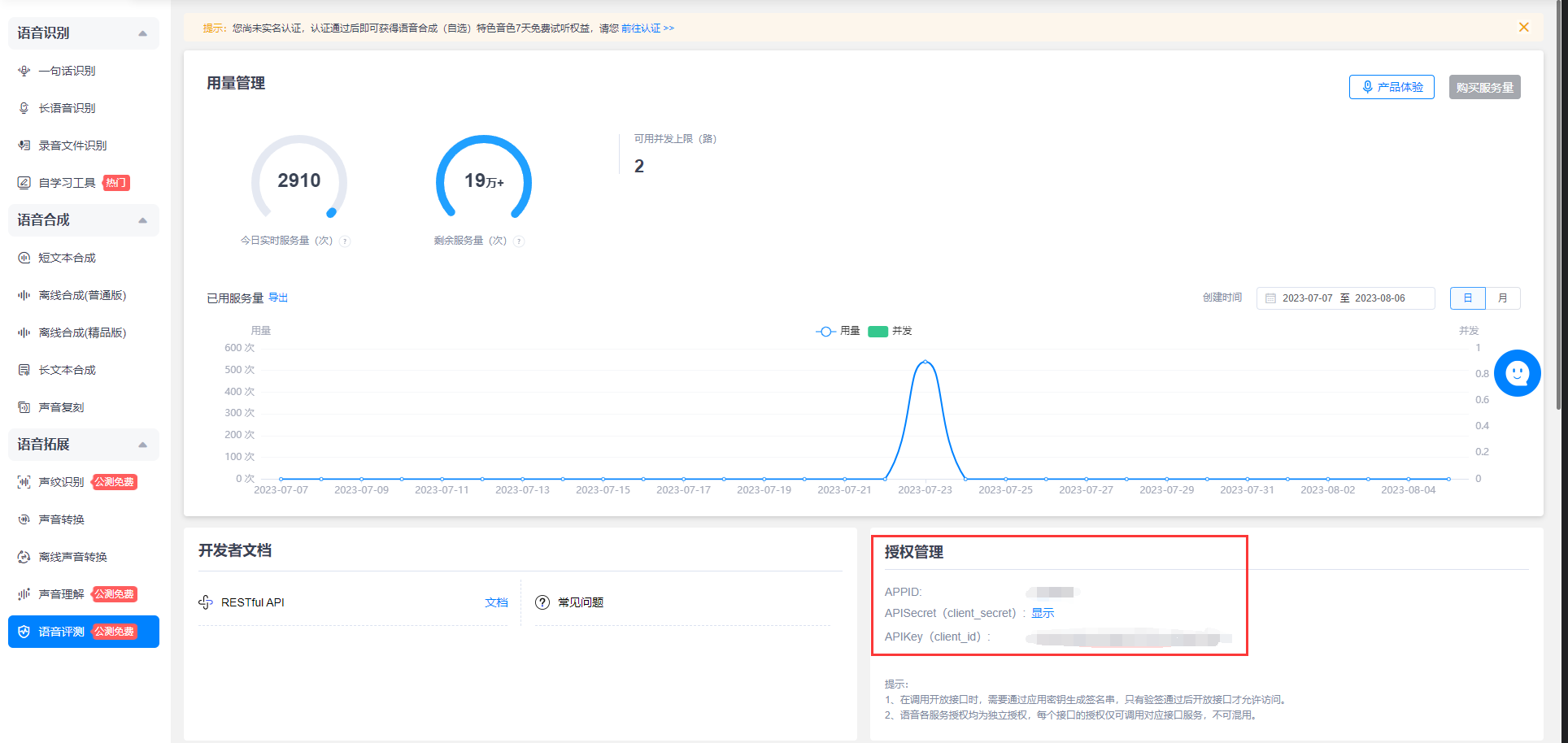
添加完毕后会自动进行校验,期间请关闭代理程序。
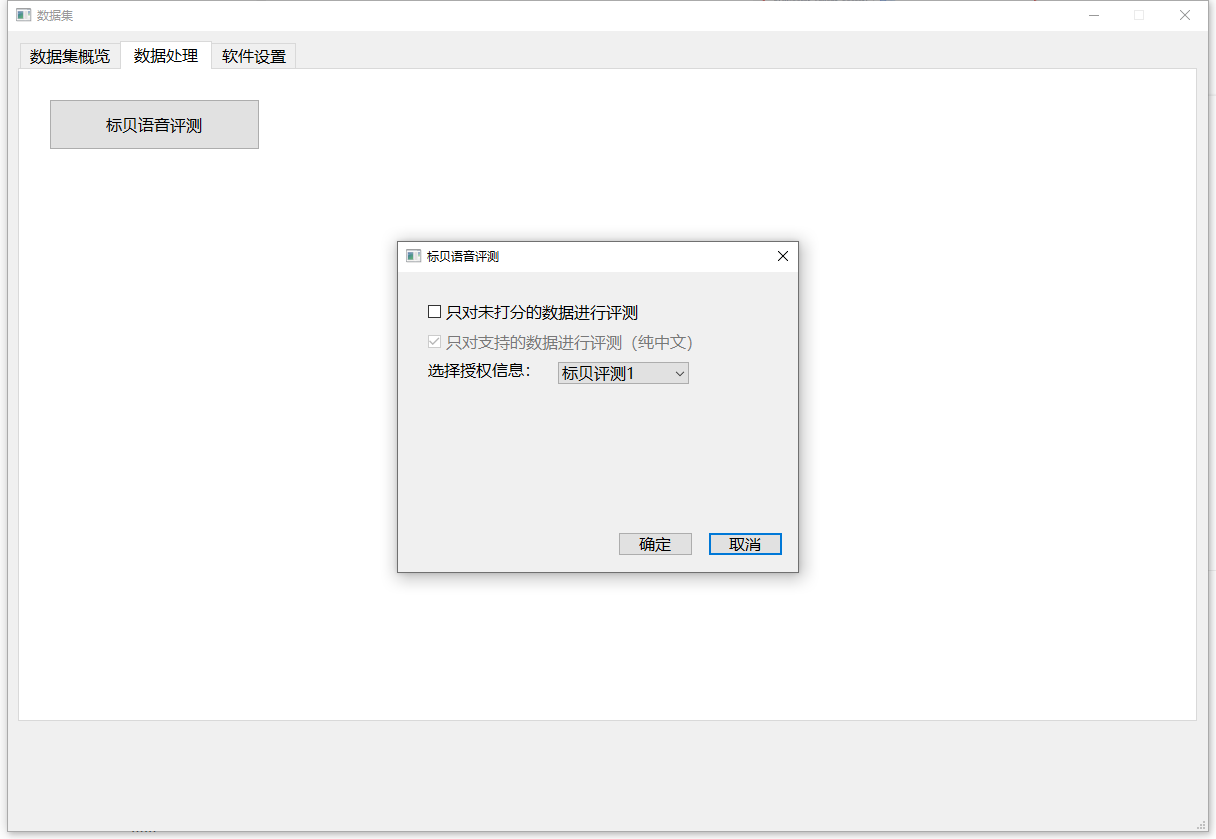
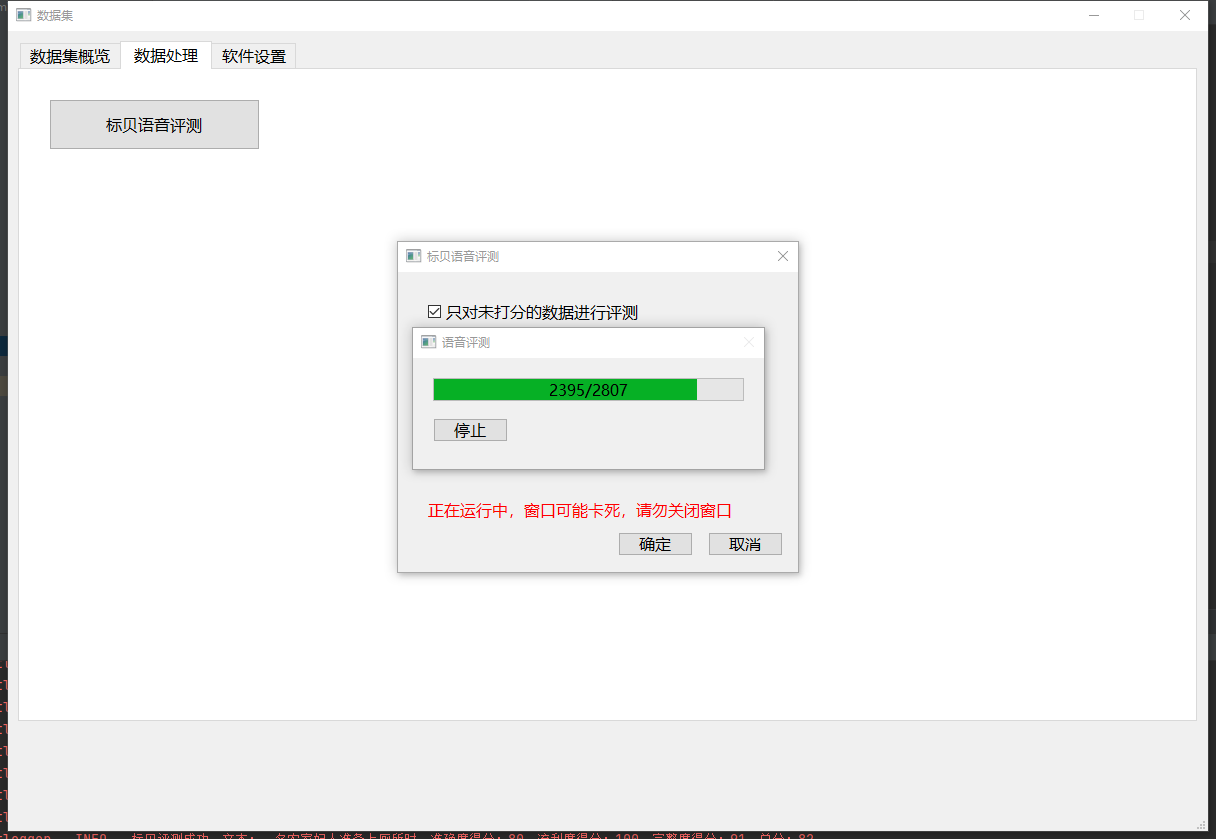
然后进入数据处理页面,点击标贝语音评测,选择相应授权信息后即可开始评测。
返回数据集概览页面,点击导出按钮,在评测相关的部分选择标贝评测,并填入对应分数要求
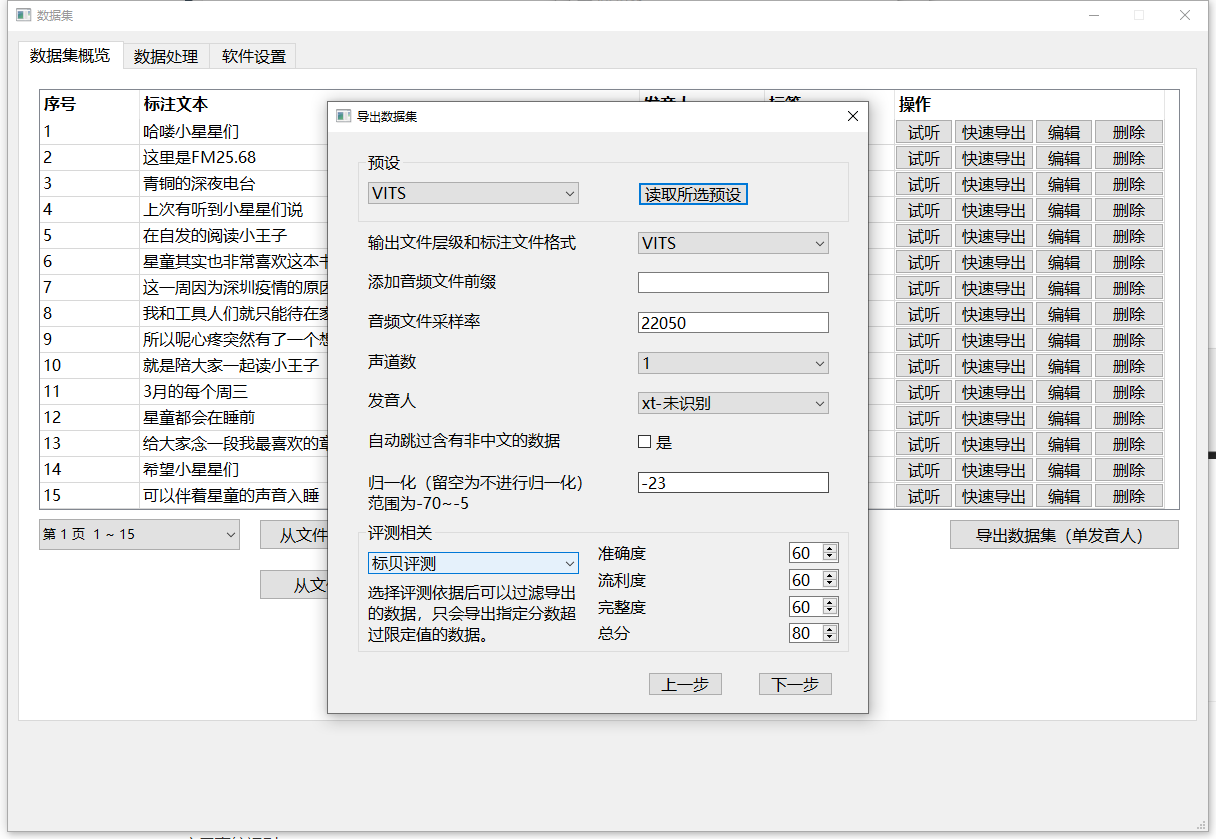
注意:选择评测的话,未进行评测的数据将不会被导出,同时因为标贝评测只支持中文,所以选择后所有英文数据也都不会被导出。
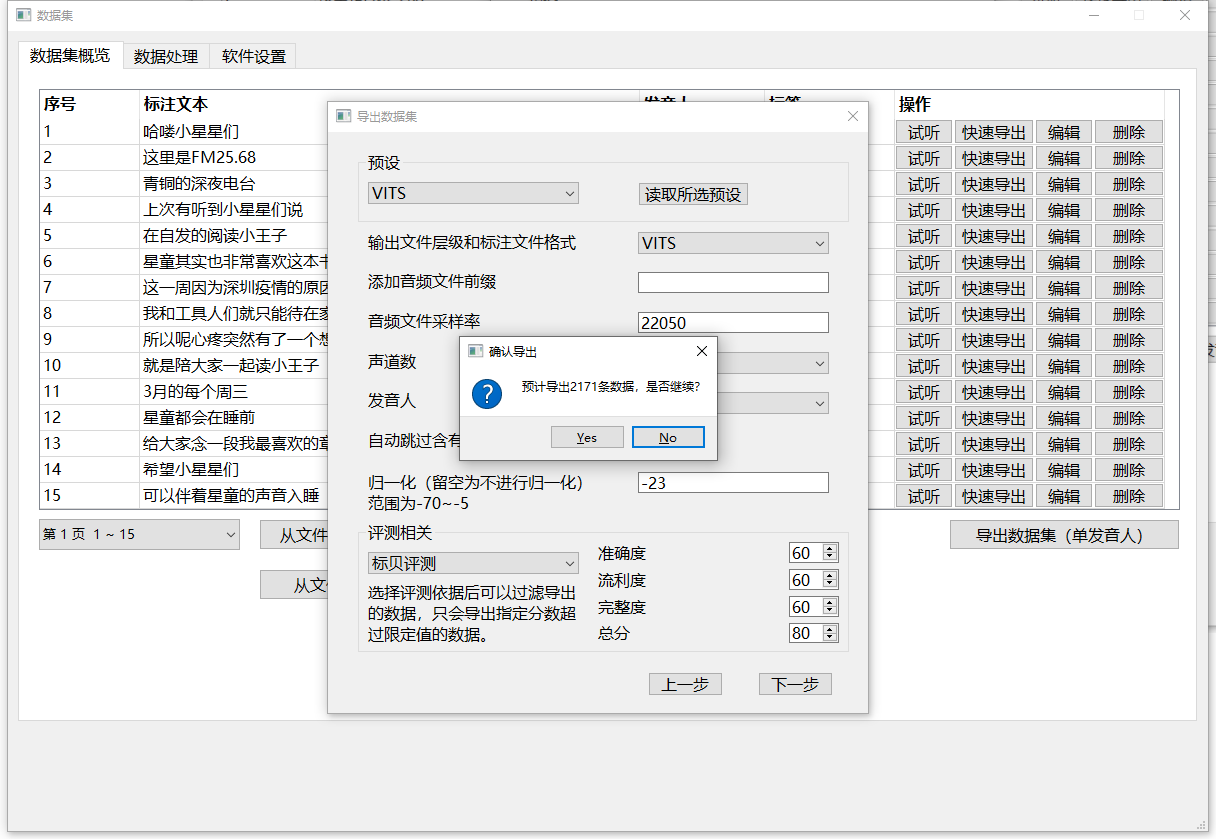
点击下一步,确认后即可开始导出
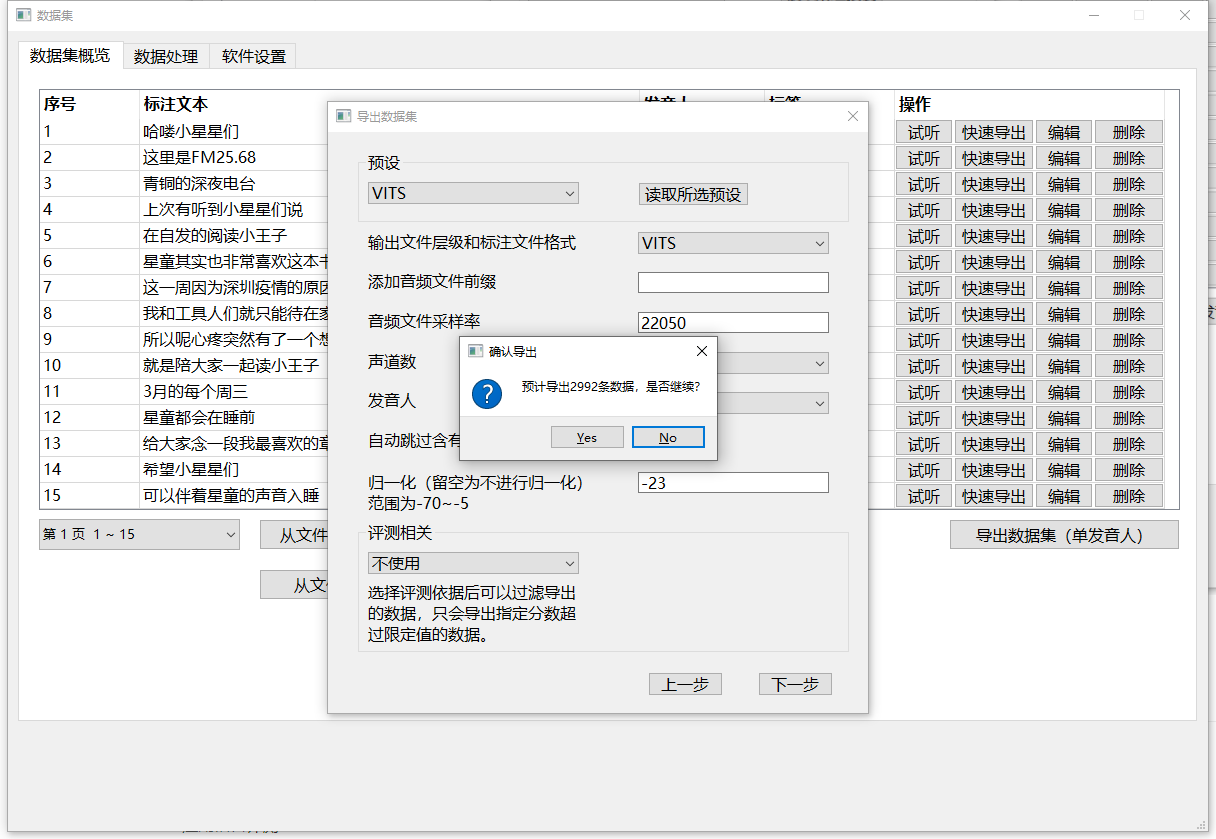
另附:不选择评测时的导出结果
编译exe版本
通过ASR标注
应用语音评测
应用声纹识别
导出多发音人数据集
快速导出
......
-
如何获取字幕?
使用剪映或videoSRT等工具获取SRT字幕文件,可以参考以下链接:
-
自动优化的逻辑?
优化逻辑是从起位置开始向前截取10ms 检查这10ms和start到start+10两段的响度比较,如果前面的响度小则把start向前挪,直到找到一个响度最小的位置,end也是类似的逻辑,这样能尽量避免音频被截断
另外剪映生成的字幕有时会讲一句话拆成多句,每句之间相隔33毫秒以内,遇到这种情况程序会将这些字幕合成一句。
-
如何升级exe版本
下载新的压缩包后将其中的exe文件替换到原来的旧版软件相同路径,覆盖原文件即可
-
待补充...