
-
- İki Listeyi Veri Olarak Birleştirmek
- Verileri Satır Bazında Birleştirmek
- Verileri Satır Bazında Gruplayarak Birleştirmek
- Verileri Sütun Bazında Birleştirmek
- Verileri Sütun Bazında Eksik Değerli Satırları Almadan Birleştirmek
- Verileri Sütun Bazında Eksik Değerleri Azaltacak Şekilde Birleştirmek
- DataFrame Tipteki Verilerin Sütun Değerlerini Birleştirmek
df.drop_duplicates()Bu işlevlerin hepsi birbirine eş değerdir. O yüzden birbirlerinin yerine kullanabilirsiniz.
float("nan")
math.nan
np.nan
>>> math.isnan(np.nan), np.isnan(math.nan)
(True, True)def missing_value_chart(df):
missing_value = df.isnull().sum()
missing_value_percent = 100 * df.isnull().sum()/len(df)
missing_value_chart = pd.concat([missing_value, missing_value_percent], axis=1)
missing_value_chart_end = missing_value_chart.rename(columns = {0: "Missing Value", 1: "% Value"})
return missing_value_chart_end
missing_value_chart(df)x.mean()
np.mean(x)
np.nanmean(x) # NaN değer varsa göz ardı edilir.
statistics.mean(x)
statistics.fmean(x)counter = 5
print(f"this is counter {counter}")
>>> this is counter 5
print(f"this is counter {0}".format(counter))
>>> this is counter 5def greet(name):
return "Hello, " + name
name = "Github"
print(f"{greet(name)}")
>>> Hello, Githubclass Sample:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"{self.name} is {self.age} years old."
john = Sample("John", 19)
print(f"{john}")
>>> John is 19 years old.def trlower(metin):
sonuç = ""
for harf in metin:
if harf == "I":
harf = "ı"
sonuç += harf
elif harf == "İ":
harf = "i"
sonuç += harf
else:
sonuç += harf
sonuç = sonuç.lower()
return sonuç
x = "KIRKLARELİ"
trlower(x)
>>> 'kırklareli'def trupper(metin):
sonuç = ""
for harf in metin:
if harf == "ı":
harf = "I"
sonuç += harf
elif harf == "i":
harf = "İ"
sonuç += harf
else:
sonuç += harf
sonuç = sonuç.upper()
return sonuç
x = "kırklareli"
trupper(x)
>>>'KIRKLARELİ'# DataFrame
df = pd.DataFrame({"col": ["foo", "foobar", "bar", "baz"]})
# "foo" ile başlayıp devamı olan kelimeler:
df[df["col"].str.contains(r"foo(?!$)")]
>>> foobar# Hem "foo" hem de "foo" ile başlayıp devamı olan kelimeler:
df[df["col"].str.contains("foo")]
>>> foo
>>> foobar# regex=False alarak tüm karakterleri alabiliriz:
df[df["col"].str.contains("foo", regex=False)]
>>> foo
>>> foobardf = pd.merge(liste1, liste2, on = "NEYE GÖRE BİRLEŞECEK (örn. liste1.index)")frames = [df1, df2, df3]
pd.concat(frames) 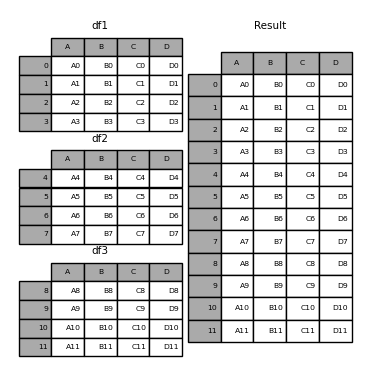
pd.concat(frames, keys=["x","y","z"]) 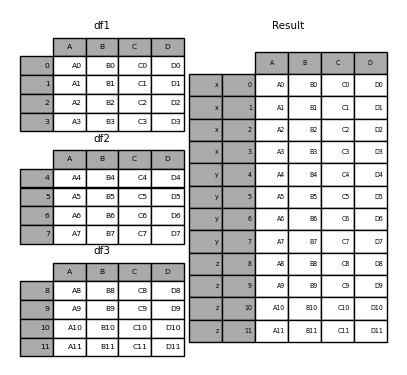
frames = [df1,df4]
pd.concat(frames, axis=1) 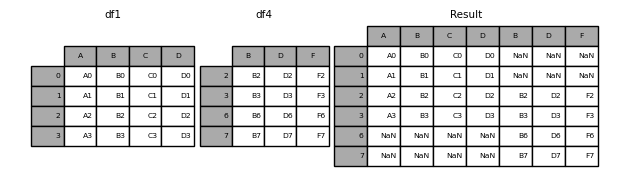
pd.concat(frames, axis=1, join="inner") 
pd.concat(frames, axis=1).reindex(df1.index) 
df["New Column Name"] = df["1st Column Name"] + df["2nd Column Name"]
df["New Column Name"] = df["1st Column Name"].map(str) + df["2nd Column Name"].map(str)
df["Full Date"] = df["Day"].map(str) + "-" + df["Month"].map(str) + "-" + df["Year"].map(str) 
Verinin tamamını görebilmek için uygulanır.
pd.set_option("display.max_rows", 1000)
pd.set_option("display.max_columns", 1000)
pd.set_option("display.width", 1000)df = pd.DataFrame({"A": [1, 2, 3, 4, 5],
"B": ["a", "b", "c", "d", "e"],
"C": [1.1, "1.0", "1.3", 2, 5]})
# Sözlük aracılığı ile değiştirilebilir.
convert_dict = {"A": int,
"C": float}
df = df.astype(convert_dict)
# Apply fonksiyonu ile değiştirilebilir.
df[["A","C"]] = df[["A","C"]].apply(pd.to_numeric)
# infer_objects() fonksiyonu ile değiştirilebilir.
# Sadece numerik tipe dönüştürülebilecekleri dönüştürüyor.
df = df.infer_objects()from datetime import datetime
start_time = datetime.now()
#Kodlarınız
time_elapsed = datetime.now() - start_time
print(f"Time elapsed: {time_elapsed}")