This repository contains the Jupyter notebook and dataset from Data School's introductory web scraping tutorial. All that is required to follow along is a basic understanding of the Python programming language.
By the end of the tutorial, you will be able to scrape data from a static web page using the requests and Beautiful Soup libraries, and export that data into a structured text file using the pandas library.
You can also watch the tutorial on YouTube.

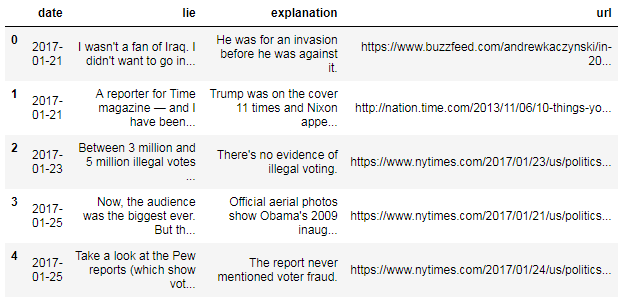
On July 21, 2017, the New York Times updated an opinion article called Trump's Lies, detailing every public lie the President has told since taking office. Because this is a newspaper, the information was (of course) published as a block of text:

This is a great format for human consumption, but it can't easily be understood by a computer. In this tutorial, we'll extract the President's lies from the New York Times article and store them in a structured dataset.
Outline of the tutorial
- What is web scraping?
- Examining the New York Times article
- Examining the HTML
- Fact 1: HTML consists of tags
- Fact 2: Tags can have attributes
- Fact 3: Tags can be nested
- Reading the web page into Python
- Parsing the HTML using Beautiful Soup
- Collecting all of the records
- Extracting the date
- Extracting the lie
- Extracting the explanation
- Extracting the URL
- Recap: Beautiful Soup methods and attributes
- Building the dataset
- Applying a tabular data structure
- Exporting the dataset to a CSV file
- Summary: 16 lines of Python code
- Appendix A: Web scraping advice
- Appendix B: Web scraping resources
- Appendix C: Alternative syntax for Beautiful Soup
Just want to see the code? Here it is:
import requests
r = requests.get('https://www.nytimes.com/interactive/2017/06/23/opinion/trumps-lies.html')
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
results = soup.find_all('span', attrs={'class':'short-desc'})
records = []
for result in results:
date = result.find('strong').text[0:-1] + ', 2017'
lie = result.contents[1][1:-2]
explanation = result.find('a').text[1:-1]
url = result.find('a')['href']
records.append((date, lie, explanation, url))
import pandas as pd
df = pd.DataFrame(records, columns=['date', 'lie', 'explanation', 'url'])
df['date'] = pd.to_datetime(df['date'])
df.to_csv('trump_lies.csv', index=False, encoding='utf-8') Want to understand the code? Read the tutorial!