The longest common extension (LCE) of two text positions in a text is the maximum size of a common substring starting at those positions, i.e., more formally
.
This repository contains different implementations to compute LCEs using different techniques:
- simply scanning the text naively
- simply scanning the text naively (but using 128 bit integers to pack characters)
- computing in-place fingerprints
- using string synchronizing sets
For easier comparison, we also provide the different implementations (based on in-place fingerprints and using data structures contained in the SDSL).
Using this code, we provide an extensive evaluation of different techniques to compute LCEs. We give a short excerpt below.
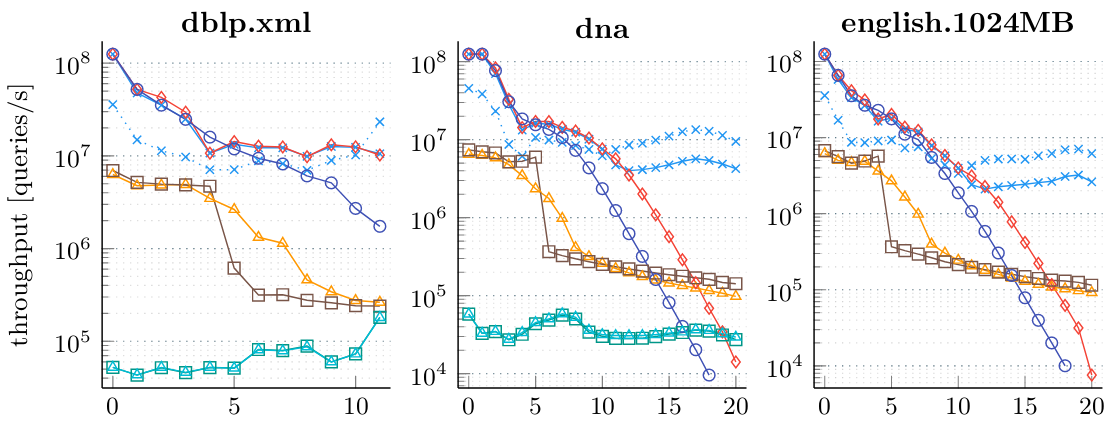
More experiments and a description of the legend can be found in our paper which has been accepted at ESA2020. Please cite the following paper if you are using our code.
@inproceedings{DinklageFHKK20,
author = {Patrick Dinklage and
Johannes Fischer and
Alexander Herlez and
Tomasz Kociumaka and
Florian Kurpicz},
title = {Practical Performance of Space Efficient Data Structures for Longest Common Extensions},
booktitle = {Accepted at European Symposium on Algorithms (ESA) 2020}}
}
First, we clone the code and submodules:
git clone https://github.com/herlez/lce-test.git
cd lce-test
git submodule update --init --recursive
Then we build the code:
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
If we want detailed information (timings and memory requirements) of the string synchronizing set LCE data structure, we have to use -DDETAILED_TIME=True.
Note that this options invalidates all other times and memory measurements for this data structure.## How to use the Benchmark Tool
Now, that we have built the code, we can use our benchmark tool to evaluate the data structures.
To this end, change to build/benchmark.
To get an overview about all possible benchmark parameters, we can use benchmark_time -help.
There are two different modes (-m or --modes) for our benchmarks:
- random, which asks random queries and
- sorted, which asks queries that have a specific size as result.
In the second case, we can control the size of the result using --from and --to, which translate to queries in the range .
These queries are precomputed and stored at
/tmp/res_lce.
We can change this directory using the -o or --output_path to specify another directory.
In the directory, we find a folder for each tested text (and each prefix size). The folder will contain a file for each length, e.g., for the dblp.xml file from the Pizza & Chili Corpus we obtain the following files:
[kurpicz dblp.xml]$ ls -al
drwxrwxr-x 2 kurpicz kurpicz 23 Dec 14 2019 .
drwxrwxr-x 19 kurpicz kurpicz 19 Dec 15 2019 ..
-rw-rw-r-- 1 kurpicz kurpicz 1812 Dec 14 2019 lce_0
-rw-rw-r-- 1 kurpicz kurpicz 135815 Dec 14 2019 lce_1
-rw-rw-r-- 1 kurpicz kurpicz 79030 Dec 14 2019 lce_10
-rw-rw-r-- 1 kurpicz kurpicz 1098 Dec 14 2019 lce_11
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_12
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_13
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_14
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_15
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_16
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_17
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_18
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_19
-rw-rw-r-- 1 kurpicz kurpicz 1923480 Dec 14 2019 lce_2
-rw-rw-r-- 1 kurpicz kurpicz 1924228 Dec 14 2019 lce_3
-rw-rw-r-- 1 kurpicz kurpicz 1934100 Dec 14 2019 lce_4
-rw-rw-r-- 1 kurpicz kurpicz 1930429 Dec 14 2019 lce_5
-rw-rw-r-- 1 kurpicz kurpicz 1798256 Dec 14 2019 lce_6
-rw-rw-r-- 1 kurpicz kurpicz 1863382 Dec 14 2019 lce_7
-rw-rw-r-- 1 kurpicz kurpicz 1973395 Dec 14 2019 lce_8
-rw-rw-r-- 1 kurpicz kurpicz 1047701 Dec 14 2019 lce_9
-rw-rw-r-- 1 kurpicz kurpicz 0 Dec 14 2019 lce_X
Here, the number i after at the end of the file name refers two queries of length . The X refers to queries that are longer than
. If a file is empty, there are no text positions that would result in a query of the requested length.
Otherwise, two lines 2i and 2i+1 for i=0,1,... are a pair of text positions that result in a query of the length indicated by the file name.
The output of the benchmark looks similar to this (depending on your specific parameter configuration):
RESULT algo=sss256 runs=5 sss_construct_time=42961 pred_construct_time=65 string_sort_time=145024 sa_construct_time=27162 lcp_construct_time=129389 rmq_construct_time=1768 sync_set_size=31630093 construction_min_time=339954 construction_max_time=352858 construction_avg_time=344512 input=/work/kurpicz/pizza_chili_repetitive/cere size=461286644 lce_mem=662279960 construction_mem_peak=2638599596
Above, we see the timings and memory usage for the construction of a string synchronizing set LCE data structure. All times are given in milliseconds. The total time the construction_[min|max|avg]_time, where min, max, and avg are the minimum, maximum, and average of the construction times of all runs (in this example 5). The final memory requirements are shown as lce_mem and the memory peak during construction is described as construction_mem_peak. Note that both measurements can be the same (if the data structure can be computed in-place).
RESULT algo=sss256_queries runs=5 lce_query_type=sorted length_exp=1 input=/work/smflkurp/pizza_chili_repetitive/cere size=461286644 lce_values_min=1 lce_values_max=1 lce_values_avg=1 lce_values_count=5000000 queries_times_min=8 queries_times_max=8 queries_times_avg=8 check=passed
RESULT algo=sss256_queries runs=5 lce_query_type=sorted length_exp=20 input=/work/smflkurp/pizza_chili_repetitive/cere size=461286644 lce_values_min=18446744073709551615 lce_values_max=0 lce_values_avg=0 lce_values_count=0 queries_times_min=18446744073709551615 queries_times_max=0 queries_times_avg=0 check=passed
Then, there are also the results for the queries. Here, we describe the length of the queries as length_exp, which translates to queries from the file lce\__length\_exp_. The number of answered queries is lce_values_count. Note that we count the number of queries in all runs. If there are no queries, the queries_times_min can is 18446744073709551615 (64-bit unsigned integer). Otherwise, queries_times_[min|max|avg] are the minimum, maximum, and average of the times required to answer the queries of all runs.