----Nghiên cứu: Bùi Minh Cường - NaVin AIF Technology Company -----
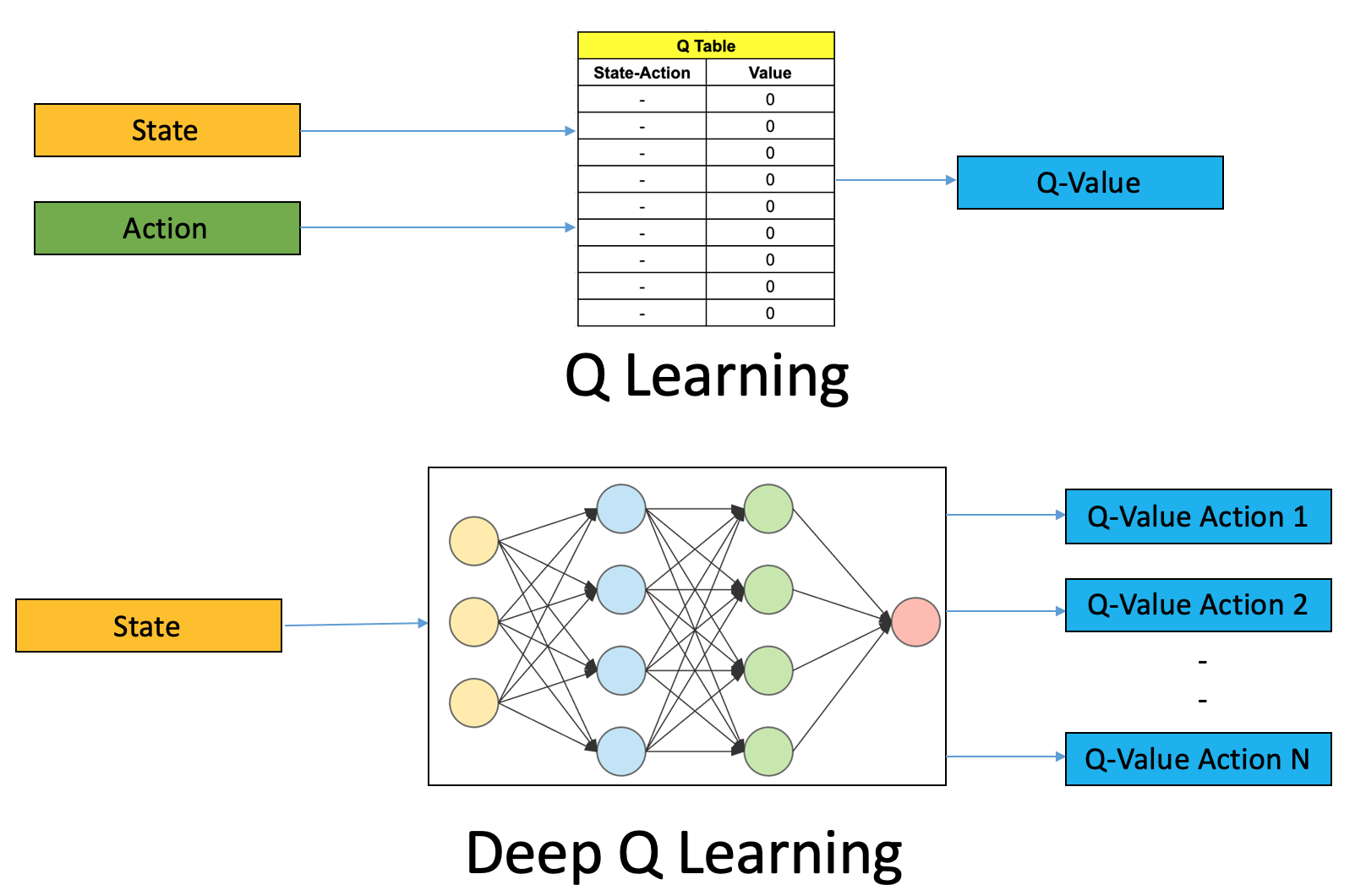
- Về Deep Q-Learning (DQL), một phương pháp học tăng cường (reinforcement learning) sử dụng mạng nơ-ron sâu để ước tính hàm giá trị hành động (Q-value function). DQL là một phần của lĩnh vực trí tuệ nhân tạo (AI) và học máy (machine learning) và đã đánh bại nhiều bài toán trong thế giới thực, bao gồm việc đào tạo máy tính để chơi các trò chơi video. Thuật toán Deep Q-learning được sử dụng trong dự án AI xe không người lái này là thuật toán học tăng cường sâu được DeepMind phát minh vào năm 2013. Nó kết hợp các ý tưởng của Q-learning với thuật toán mạng nơ-ron và cũng là nguồn gốc của các thuật toán học tăng cường hiện đại. Các nhà nghiên cứu đã sử dụng thuật toán này để cho phép máy tính học 49 trò chơi Atari vào năm 2015 và đánh bại con người trong hầu hết các trò chơi đó. Về khả năng ứng dụng, chúng ta không cần phải nói rõ các quy tắc cụ thể của AI. Chỉ cần tiếp tục khám phá, nó sẽ từ từ tìm ra quy luật và hoàn thành nhiều hoạt động trí tuệ mà trước đây cho rằng chỉ con người mới có thể thực hiện được.
Q-learning là một thuật toán học tăng cường. Phương tiện không người lái cần thực hiện hành động dựa trên trạng thái hiện tại. Sau khi nhận được phần thưởng tương ứng, nó có thể cải thiện các hành động này để phương tiện không người lái có thể đưa ra quyết định tốt hơn vào lần tiếp theo ở trạng thái tương tự.
Ta có công thức như sau:
Khởi tạo Q tùy ý // Khởi tạo ngẫu nhiên giá trị Q
Lặp lại (cho mỗi tập): // Mỗi lần bạn thử, đó là một tập từ lúc xe khởi động cho đến khi đâm vào tường.
Khởi tạo S // Xe xuất phát, S là trạng thái vị trí ban đầu
Lặp lại (cho từng bước của tập):
Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*maxQ(S',a)] // Phương trình Bellman cốt lõi của Q-learning, cập nhật giá trị tiện ích hành động
S ← S' // cập nhật vị trí
cho đến khi S là điểm cuối // vị trí đạt đến điểm cuối
Các bước chính của DQL bao gồm:
- Thu thập dữ liệu: Hệ thống tương tác với môi trường và thu thập dữ liệu về các cặp trạng thái-hành động và phần thưởng tương ứng.
- Xây dựng mạng nơ-ron: Tạo một mạng nơ-ron sâu (deep neural network) để dự đoán Q-values dựa trên trạng thái đầu vào.
- Đào tạo mạng: Sử dụng dữ liệu đã thu thập để đào tạo mạng nơ-ron sao cho nó dự đoán Q-values tốt nhất.
- Cập nhật hàm giá trị: Sử dụng mạng nơ-ron đã đào tạo để cập nhật hàm giá trị Q cho mỗi trạng thái-hành động.
- Lựa chọn hành động: Dựa vào hàm giá trị Q đã được ước tính, hệ thống chọn hành động có Q-value cao nhất cho mỗi trạng thái.
Movation
DQL đã được sử dụng thành công trong nhiều ứng dụng, bao gồm việc đào tạo máy tính để chơi các trò chơi video, tự động lái xe ô tô, và nhiều ứng dụng trong lĩnh vực tối ưu hóa và quyết định. Tuy nhiên, việc đào tạo mạng nơ-ron sâu có thể yêu cầu nhiều dữ liệu và thời gian tính toán, và còn tồn tại nhiều thách thức trong việc ứng dụng DQL vào các tình huống thực tế.
Đầu tiên các bước thực hiện của chương trình rất đơn giản, bạn chỉ cần cài đặt các phụ thuộc cần thiết cho chương trình, sau đó chạy chương trình chính. Tại đây có 3 chức năng chính, bạn chỉ cần click và và setup như hướng dẫn. Việc còn lại chỉ là tận hưởng và trải nghiệm.
Reqs:
pip install -r requirements.txt
Usage: ( recomment: using python >= 3.8.3)
python X_Main.py
Bellman Equation
 Mô phỏng + Công thức
Mô phỏng + Công thức
 Softmax-Function
Softmax-Function
- Contact:
- Youtube(❁´◡`❁)
- Linkedin(❁´◡`❁)
- Twitter(❁´◡`❁)
- Zalo
- Gmail
- [NaVin AI Tech] [We Comming Soon]