**现在有9亿网民,我们随便一个人做点什么都会产生大量数据,比如看一下视频发表一下感想。
点赞57万,投币45万,评论1W+,再比如前段时间的618购物节,无数网民疯狂购物产生无数的消费数据,这么庞大的数据量该如何存储?
我们都知道mysql有性能瓶颈,当数据量到达2100w左右的时候,效率就会大幅下降。
mysql> show global variables like '%page%';
+--------------------------------------+-----------+
| Variable_name | Value |
+--------------------------------------+-----------+
| innodb_log_compressed_pages | ON |
| innodb_max_dirty_pages_pct | 75.000000 |
| innodb_max_dirty_pages_pct_lwm | 0.000000 |
| innodb_page_cleaners | 1 |
| innodb_page_size | 16384 |
| innodb_stats_persistent_sample_pages | 20 |
| innodb_stats_sample_pages | 8 |
| innodb_stats_transient_sample_pages | 8 |
| large_page_size | 0 |
| large_pages | OFF |
+--------------------------------------+-----------+
10 rows in set (0.01 sec)也就是说innode_page_size为16kb,我们常用int,bigint和varchar作为主键,当然mysql官方推荐使用int或bigint作为主键。总所周知mysql中一个int类型的所占用字节为4个字节,一个bigint占了8个字节,那一个索引呢?
SELECT * FROM `information_schema`.`TABLES` where table_name='table_name' 可以查看有关表的信息,关于索引的大小就在index_length,所以一个索引的占用是6个字节。
所以一个page我们可以存多少数据量呢,首先我们B+tree的degree是3。
int类型 16384 / (6+4) = 1638 行,也就是说我们能存
1638 * 1638 * 16 = 42928704bigint类型 16384 / (8+6) = 1170,也就是说能存
1170 * 1170 * 16 = 21977344所以我们说mysql到了2100w,就到头了,不是因为不能存,而是数据存进去,B+tree的高度会增加,遍历子节点的次数要增加。
我们可以采用水平拓展的方式去实现存储。比如9亿网民,单张表我们存2100W。那就多搞张表。
# 数据库1
db_member_0
tb_member_0
tb_member_1
tb_member_2
tb_member_3
tb_member_9
# 数据库2
db_member_1
tb_member_0
tb_member_1
tb_member_9
db_member_9 db_member_x表示我第x个数据库,tb_member_x表示库里的第x个表。这样就可以存21亿的数据量。
如何存储某一位网民的假设我们的主键id是202006272319230001,这个id是用年月日时分秒加一个0001这样的数字组合而成的,我们对单库的表个数取模,比如我数据库db_member_0 中用户表有10个,那id个位对10取模就存在某个表里,他的十位取模决定了存在某个库里。
也就是说0001存在0号库的1号表里,0072存7号库的2号表里。
上述说了这么多,但是我们的数据库表id可能是自增的,那查询的时候如何处理?
这个就是今天第一个要解决的问题leaf分布式ID。
There are no two identical leaves in the world.
世界上没有两片完全相同的树叶。
— 莱布尼茨
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
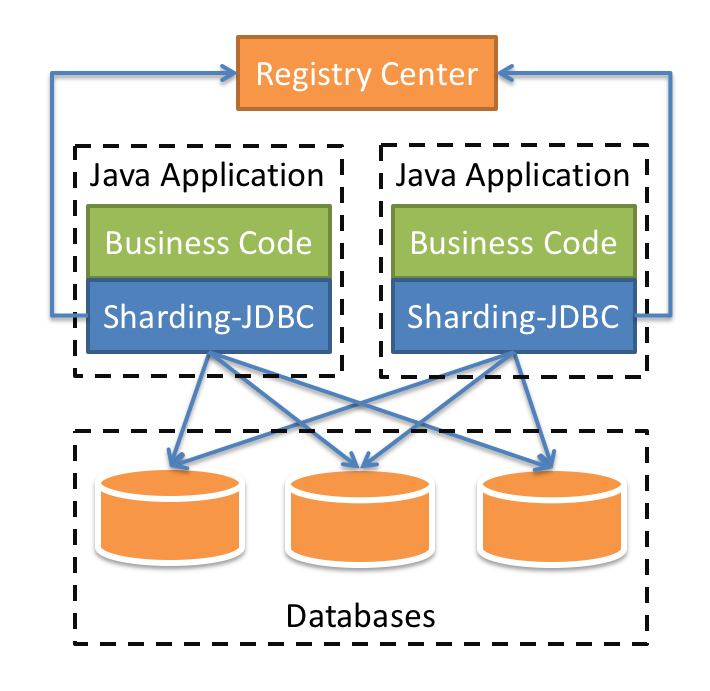
实际参考项目 hello-sharding-jdbc 项目地址
实际参考项目hello-sharding-proxy项目地址
[Leaf——美团点评分布式ID生成系统](https://tech.meituan.com/2017/04/21/mt-leaf.html)
[B+Tree 数据结构](https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html)
[为什么我的mysql里index_length是0bytes](https://stackoverflow.com/questions/29692421/mysql-why-is-my-index-length-0-0-bytes)