FallacyScoreboard is an offline tool that downloads YouTube videos, processes them using WhisperX for automatic speech recognition and speaker diarization, detects logical fallacies using LLMs with OLLAMA, and overlays the results on the video with a scoreboard.
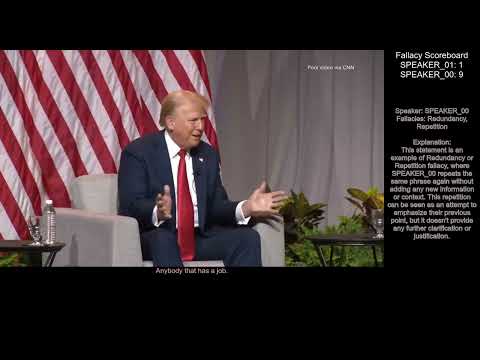
Click the image above to watch a demonstration of FallacyScoreboard in action!
- Download YouTube videos and extract audio
- Transcribe audio using WhisperX with word-level timestamps and speaker diarization
- Detect logical fallacies in transcribed text
- Overlay fallacy detection results on the video with a scoreboard and side panel
- Handle multiple fallacies per speaker segment
- Color-code speakers for easy identification
-
Clone the repository:
git clone https://github.com/latent-variable/FallacyScoreboard.git cd FallacyScoreboard -
Create a Python environment:
conda create --name fallacyscoreboard python=3.10 conda activate fallacyscoreboard
-
Install dependencies:
pip install -r requirements.txt
-
Install ImageMagick: FallacyScoreboard uses MoviePy, which requires ImageMagick. Make sure to install ImageMagick and set the path in the script:
change_settings({"IMAGEMAGICK_BINARY": r"path/to/your/ImageMagick-7.1.1-Q16-HDRI/magick.exe"})
-
Process a YouTube video:
from fallacyscoreboard import fallacy_detection_pipeline output_path = "path/to/output/directory" video_url = "https://www.youtube.com/watch?v=example" fallacy_detection_pipeline(video_url, output_path)
This function will:
- Download the YouTube video
- Extract audio from the video
- Transcribe the audio using WhisperX
- Detect fallacies in the transcription
- Overlay the fallacies and scoreboard on the video
-
Customize OLLAMA settings: You can customize the OLLAMA host and model by modifying these variables in the script:
OLLAMA_HOST = 'http://localhost:11434' OLLAMA_MODEL = 'llama3.1'
The script will generate several files in the output directory:
- The downloaded video file
- An extracted audio file
- A JSON file with the transcription and diarization results
- A text file with formatted transcription
- A JSON file with fallacy analysis results
- The final video with overlaid fallacy scoreboard and explanations
This project is licensed under the MIT License - see the LICENSE file for details.
- Ensure you have sufficient disk space and computational resources, as processing videos can be resource-intensive.
- The quality of fallacy detection depends on the OLLAMA model used. Experiment with different models for best results.
- This tool is for educational and research purposes. Always respect copyright and terms of service when using YouTube content.