基于LZW算法的压缩软件,可压缩任意格式文件,但不保证压缩比小于100%QAQ
LZW压缩算法是由Abraham Lempel、Jacob Ziv和Terry Welch共同发明的一种无损压缩技术。LZW是美国Unisys公司的专利,在2003专利到期,所以现在对LZW压缩的使用已经没有限制。压缩技术的一种核心**就是字典对照,用小的字符串代替长的字符串。压缩的**在几千年前就已经有了,人们喜欢指代,为地名起简称是一种。在计算机则是主要用于解决通信传输问题和存储问题,Morse Code就是很好的例子。
而LZW压缩技术相对于很多压缩方法来说很大的不同是:采用定长编码,并且不存储字典,字典是在压缩和解压过程中根据之前的步骤动态生成的。相比之下Huffman编码则是需要存储字典的变长编码。如果在LZW的基础上做Huffman编码就会得到我们常见的zip格式的结果。
优缺点:一方面在最终压缩结果中不需要存储字典,并且实现起来较为简单;另一方面,对文本文件、bmp和gif等文件有较好的压缩效果,而对png、jpg等格式文件压缩比会大于100%,这是因为png等格式本身就是很好的压缩算法了。
- 我们知道文件可以分为两类,文本文件和二进制文件。

2. 虽然两种文件有不同的表现形式,但是在计算机中它们都是以01代码的方式存储的。所以在编程方面,我们可以采用二进制的方式打开文件。用一个字节代表一个字符,取值范围是0-255,如果是ASCII文件则是0-127。所以需求中对两种文件实现压缩可以规约到同一种实现。
3. 为了提升系统的使用方便程度,所以需要实现图形用户界面,增强可交互性。界面需要提供压缩、解压接口,并且对用户可能导致的异常做出判断。
4. 核心问题是效率问题,所以压缩和解压实现采用C语言,可以手动管理内存,用来提高效率。但是C语言对图形界面支持不是很好,所以采用JAVA做图形用户界面。然后由C语言生成动态数据链接库dll文件,在JAVA中调用C语言函数。
## 三、 LZW算法原理
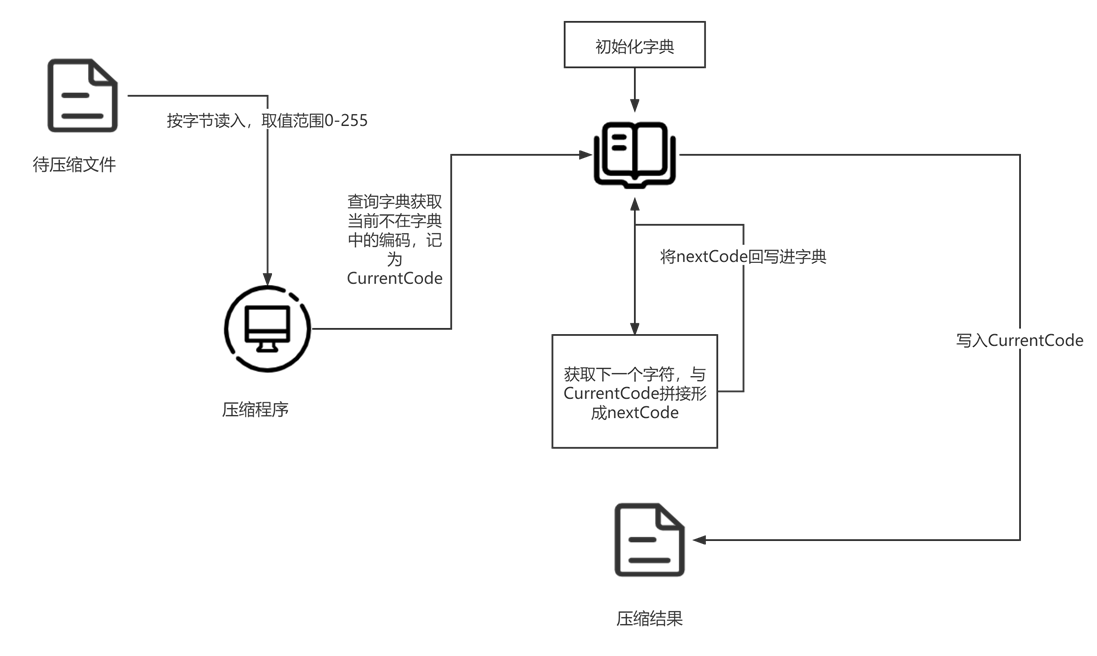
### 1. 压缩流程
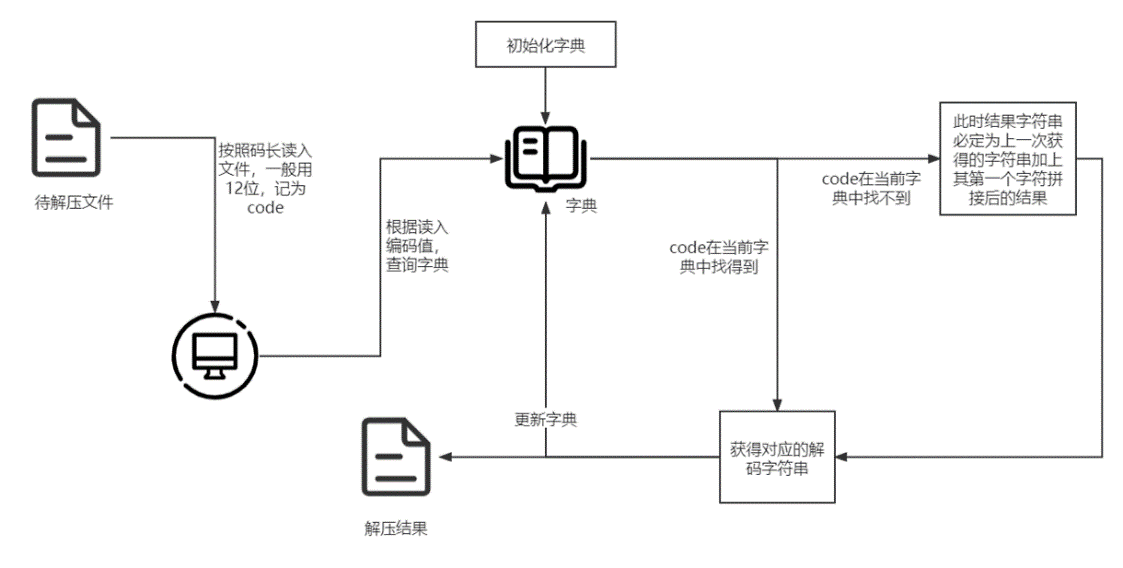
2. 解压流程
3. 例子
A. 例子:实现对字符串 “ababcababac”的压缩。
a. 初始字典:

b. 压缩流程
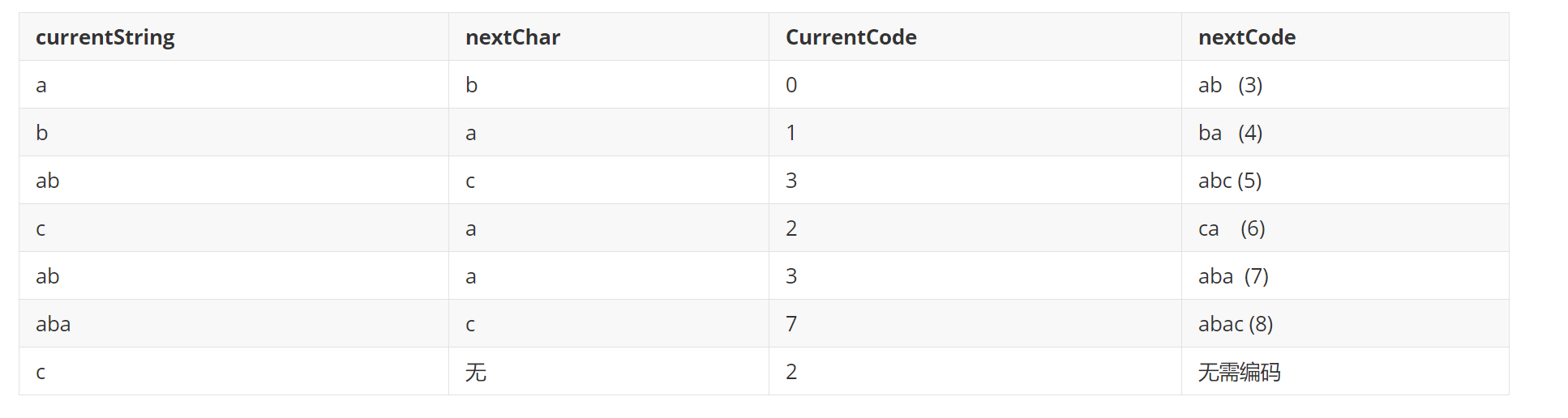
c. 结果:0132372,压缩比:7/11 ≈ 63.6%
B. 例子:实现对字符串 “0132372”的解压缩。
a. 初始字典
b. 解压缩流程
c.结果:ababcababac
在字典中我们可以约定,无论多长的字符串其对应的编码都是定长的,通常选择12位。12位也就决定着编码的取值范围是0-4095,也就是最多4096个编码,字典中最多存放4096个。我们还可以约定一个字符用一个字节表示,也就是8位。所以在字典中可以是1个字节对应12位,可以是2个字节对应12位,可以是3个字节对应12位......可以发现当一个字节对应12位编码的时候,压缩比会大于100%,因此我们希望尽可能多的是两个及以上的字节对应12位。
字典中的4096个编码是否就一定够用呢? 仔细想想是不可能的。如果说1MB的文件是够的,那么如果压缩1GB的文件呢?4096个编码是大概率不够用的。但是为什么选择4096呢?一方面计算机是按字节组织的,12位是一个半字节方便操作,两个12位就相当于3个字节,也就是可以说周期是2。一方面是当文件随机的话,只有长的字符串才有可能出现在字典里面的时候才有可能造成编码个数大于4096,而较长的编码出现一次再出现第二次的概率是很低的。综上,选择4096的效果是很好的。当字典编码个数大于4096的时候,就清空字典,重新开始编码,这个过程相当于对文件进行了分段,对每一段进行单独的压缩,而不同的是分割的每一段大小是不等的。
一开始我的做法:将整个文件从头到尾用一个字典进行了压缩。然后依据字典的长度,生成每一个编码的位数,再写入压缩结果。对小文件来说还是很正常的,但是当文件变大之后,字典的总数特别大,消耗了大量内存,并且需要很多位来存储字典。这样导致了最终压缩效果都特别差,压缩比远远超过100%。并且因为最终的位数可能是23、29这样周期特别大的数,对结果的写入增加了难度,我的想法是将结果首先写入到一个字符串,然后8个一次读取字符串,写入结果。这种做法有两个地方导致巨大的时间复杂度:一方面是当字符串变大的时候,在字典中查找的时候,需要进行比较,导致了更多的比较次数;一方面是字符串的频繁地拼接、截取。这种做法在压缩效果和时间、空间复杂度上都是很明显不值当的选择。
 然后就是进一步对效率地提高:
1. 字符串之间地比较是逐个字符比较的,通过程序实现的,而基本类型之间的比较是由硬件直接完成的。所以我们尽可能地应该使用基本类型的比较,避免字符串的比较。一开始我考虑采用大数乘法、加法的方式,将字符串转换成一个对应的10进制数,这样可以将比较字符串的长度缩短为nlg2,实现之后发现大数乘法、除法的时间复杂度太高了。接着考虑采用16进制数,这样只用原来的n/4的比较长度,但是效果也不行。最终我选择采用64位基本整形(long long),可以表示7个字符组成的字符串(不是8个的原因是,最高位是符号位,在hash函数中我们希望它大于0)。然后不对长度大于7的字符串进行编码,经过测试在字典大小位4096的情况下,很少出现大于7的情况,在BMP文件中出现的较为频繁。尽管这种做法在一定程度上提高了压缩比,但是对时间上带来了很大的改进。
2. 然后字典的存储选择了hash的方式,这是因为LZW的字典需要查找和增加操作,而Hash方式查找和增加的时间复杂度是接近O(1)的。不同的是我对链表散列的方式进行了改进,其中的每一个链表,我都替换成了AVL树。这样提高了在链表中的查找效率。这是学习JAVA中HashMap的做法,在HashMap中当链表长度大于8的时候会转换成红黑树。但是后来经过测试发现我的链表散列的模数选择了4099(质数),大多数AVL树的节点数量都是小于3的,AVL树的改进相对于链表可能没有多大的优势,所以我进行了实际测算。结果发现在向字典插入4096个单词的时候时间上的开销AVL树占有一定的优势,但是空间上AVL树处于明显的劣势,因为AVL树的节点不仅仅要存储高度,还有存储左右子、父母的指针,增大了开销。AVL树在时间上虽然没有多少节点却占有优势,但是具体分析一下,节点数量为1、2的时候AVL树退化到有序链表结构,这两者占据大多数,因此在大多数时候有序链表是不占有优势的。两种方式都做了实现,后面进行memcpy优化后(取决于空间大小),会综合考虑。
然后就是进一步对效率地提高:
1. 字符串之间地比较是逐个字符比较的,通过程序实现的,而基本类型之间的比较是由硬件直接完成的。所以我们尽可能地应该使用基本类型的比较,避免字符串的比较。一开始我考虑采用大数乘法、加法的方式,将字符串转换成一个对应的10进制数,这样可以将比较字符串的长度缩短为nlg2,实现之后发现大数乘法、除法的时间复杂度太高了。接着考虑采用16进制数,这样只用原来的n/4的比较长度,但是效果也不行。最终我选择采用64位基本整形(long long),可以表示7个字符组成的字符串(不是8个的原因是,最高位是符号位,在hash函数中我们希望它大于0)。然后不对长度大于7的字符串进行编码,经过测试在字典大小位4096的情况下,很少出现大于7的情况,在BMP文件中出现的较为频繁。尽管这种做法在一定程度上提高了压缩比,但是对时间上带来了很大的改进。
2. 然后字典的存储选择了hash的方式,这是因为LZW的字典需要查找和增加操作,而Hash方式查找和增加的时间复杂度是接近O(1)的。不同的是我对链表散列的方式进行了改进,其中的每一个链表,我都替换成了AVL树。这样提高了在链表中的查找效率。这是学习JAVA中HashMap的做法,在HashMap中当链表长度大于8的时候会转换成红黑树。但是后来经过测试发现我的链表散列的模数选择了4099(质数),大多数AVL树的节点数量都是小于3的,AVL树的改进相对于链表可能没有多大的优势,所以我进行了实际测算。结果发现在向字典插入4096个单词的时候时间上的开销AVL树占有一定的优势,但是空间上AVL树处于明显的劣势,因为AVL树的节点不仅仅要存储高度,还有存储左右子、父母的指针,增大了开销。AVL树在时间上虽然没有多少节点却占有优势,但是具体分析一下,节点数量为1、2的时候AVL树退化到有序链表结构,这两者占据大多数,因此在大多数时候有序链表是不占有优势的。两种方式都做了实现,后面进行memcpy优化后(取决于空间大小),会综合考虑。
3. 接着是对文件读取速度的提高。我们知道访问磁盘的效率是很低的,而在LZW的实现的时候需要实现一次读取文件中的一个字节的需求,经过我的测试直接这样每次读取一个字节的效率是很低的。于是我想到了封装一个操作文件的类,在其中我可以自己维护缓冲区,一次从文件中读取很多内容(4MB->30MB),通过函数的调用传给主程序。这样的缺点是需要频繁的调用函数,经过测试效果在一次读取一个字节的做法上效率得到了很大的提升。同样也可以这样写入文件。
 由测试结果可以发现,文件读出的主要开销来源是从磁盘读出的次数,函数调用的开销相对来说影响不是很大。而如果将函数功能展开到主程序中,会增加编码难度,同时降低程序的可读性和健壮性,虽然这种方式在一定程度上可以减小函数调用的开销。
同样的,通过File类维护输出的时候的缓冲区。
由测试结果可以发现,文件读出的主要开销来源是从磁盘读出的次数,函数调用的开销相对来说影响不是很大。而如果将函数功能展开到主程序中,会增加编码难度,同时降低程序的可读性和健壮性,虽然这种方式在一定程度上可以减小函数调用的开销。
同样的,通过File类维护输出的时候的缓冲区。
 4. 由于需要频繁的清空字典,同时对字典进行初始化操作。随着初始化次数的增加,其所消耗的时间随之增大,而初始化字典长度为256,字典的总长度为4096,占6.25%,也就意味着理论上会占用6.25%左右的时间。于是我想到了一种优化方式:
4. 由于需要频繁的清空字典,同时对字典进行初始化操作。随着初始化次数的增加,其所消耗的时间随之增大,而初始化字典长度为256,字典的总长度为4096,占6.25%,也就意味着理论上会占用6.25%左右的时间。于是我想到了一种优化方式:
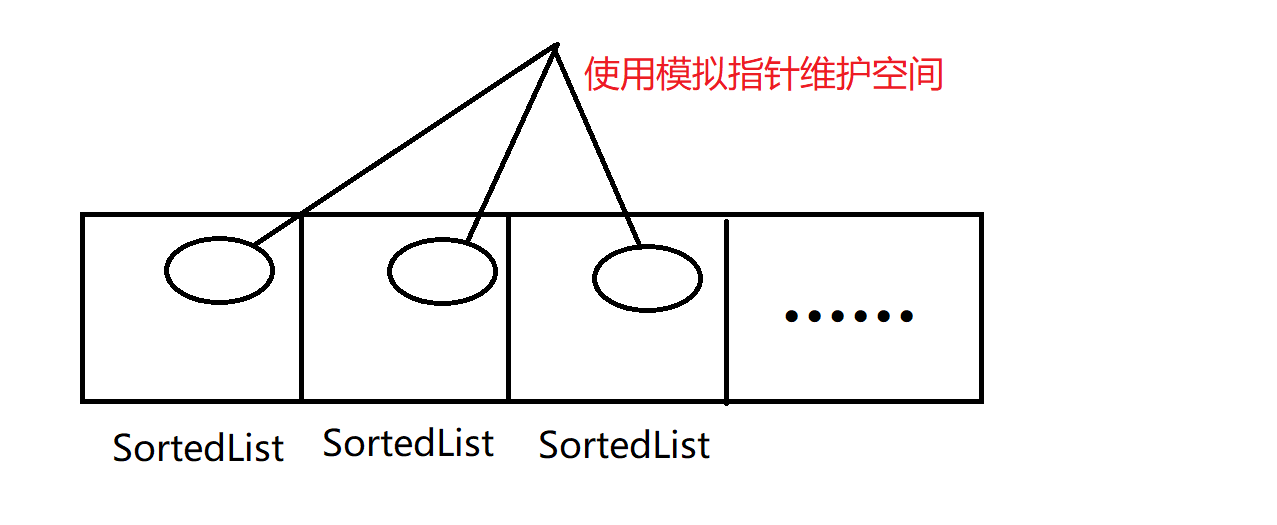 一开始SortedList是间接寻址的方式组织起来的,在内存中不能保证连续,将其改为对象数组的组织方式,在空间上保证连续。同时每个SortedList在空间中也是分散的,采用模拟指针的方式,自己维护一段空间,用于节点的申请和释放,保证空间上的连续。
接着需要创建两个字典,一个字典用于存储使用的字典,一个存储初始化之后的字典。接着每一次初始化操作,就可以转换成通过memcpy函数将初始化完成之后的字典拷贝到使用中的字典。下图是效率分析:
一开始SortedList是间接寻址的方式组织起来的,在内存中不能保证连续,将其改为对象数组的组织方式,在空间上保证连续。同时每个SortedList在空间中也是分散的,采用模拟指针的方式,自己维护一段空间,用于节点的申请和释放,保证空间上的连续。
接着需要创建两个字典,一个字典用于存储使用的字典,一个存储初始化之后的字典。接着每一次初始化操作,就可以转换成通过memcpy函数将初始化完成之后的字典拷贝到使用中的字典。下图是效率分析:
 5. 关于多线程运行的考虑。想到对大文件的压缩效果依然不是很好,我想过对压缩文件进行分步并行运行。但是LZW压缩对文件是顺序压缩的,分段一方面可能造成压缩比的增大。一方面需要存储分段的标记,而这个标记需要用很多位来分割,因为否则很容易对源文件内容造成误解。对压缩结果的写入也会十分的复杂,因为要考虑线程之间的写入次序。综上,对文件压缩过程的多线程实现,可行性低。还有就是可以考虑读文件的时候进行并行操作,也就是在压缩程序运行的时候,读取文件,这两个之间存在并行的可能。但是实际上,进过测试,这种实现对效率的提升没有多大的帮助,甚至效率更低了,一方面是和操作系统的调度有关,一方面是读取文件经过上述的优化之后,效果很好,相对于压缩程序占用的时间是很小的。
5. 关于多线程运行的考虑。想到对大文件的压缩效果依然不是很好,我想过对压缩文件进行分步并行运行。但是LZW压缩对文件是顺序压缩的,分段一方面可能造成压缩比的增大。一方面需要存储分段的标记,而这个标记需要用很多位来分割,因为否则很容易对源文件内容造成误解。对压缩结果的写入也会十分的复杂,因为要考虑线程之间的写入次序。综上,对文件压缩过程的多线程实现,可行性低。还有就是可以考虑读文件的时候进行并行操作,也就是在压缩程序运行的时候,读取文件,这两个之间存在并行的可能。但是实际上,进过测试,这种实现对效率的提升没有多大的帮助,甚至效率更低了,一方面是和操作系统的调度有关,一方面是读取文件经过上述的优化之后,效果很好,相对于压缩程序占用的时间是很小的。
 6. 经过老师的提醒,还可以对编译器本身进行优化,使我联想起了O2优化。O2优化几乎开启了GCC编译器所有可以开启的优化,可以大幅度的提升程序的执行速度。(增加编译选项-O2)
6. 经过老师的提醒,还可以对编译器本身进行优化,使我联想起了O2优化。O2优化几乎开启了GCC编译器所有可以开启的优化,可以大幅度的提升程序的执行速度。(增加编译选项-O2)
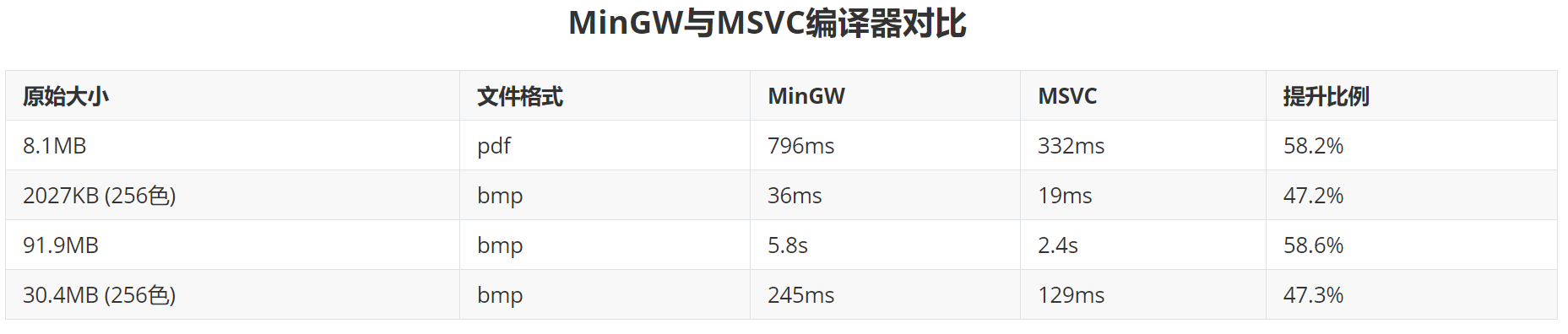
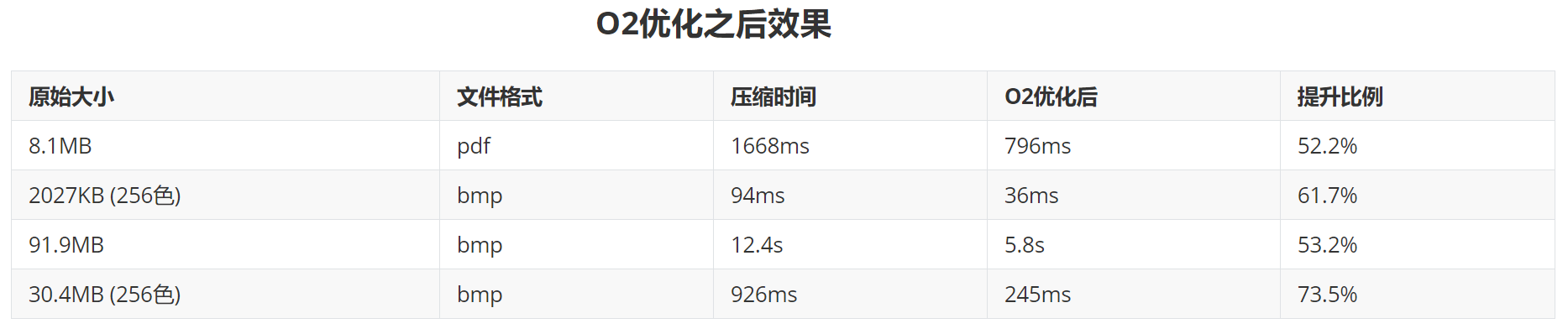 接着尝试过更换编译器,Windows系统上微软做的MSVC(Microsoft Visual Studio Compiler)。经过测试,之前使用的MinGW编译器效率低,在Windows平台上MSVC编译器性能更好,速度提升了1倍。
接着尝试过更换编译器,Windows系统上微软做的MSVC(Microsoft Visual Studio Compiler)。经过测试,之前使用的MinGW编译器效率低,在Windows平台上MSVC编译器性能更好,速度提升了1倍。
- 项目结构
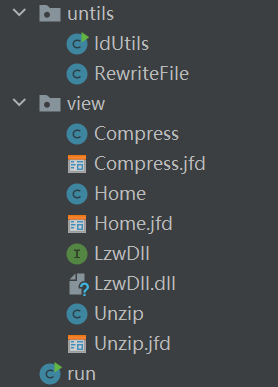
A. 项目类图
B. 压缩、解压核心代码结构
C. JAVA图形界面展示项目结构

2. 压缩方法代码

3. 解压缩代码
4. 读写文件类的封装(仅展示了部分函数)

5. 采用Hash方式存储的字典结构,实现较为简单,未作创新,此处省略。
## 六、 性能分析
注:测试时间是单纯压缩、解压缩时间,未考虑图形渲染用时,JAVA虚拟机用时,以及为解决C/C++语言处理中文路径的问题,而做的缓存。测速受到机器当前时刻忙闲度的影响,所做测试是在机器负载较小情况下做的。
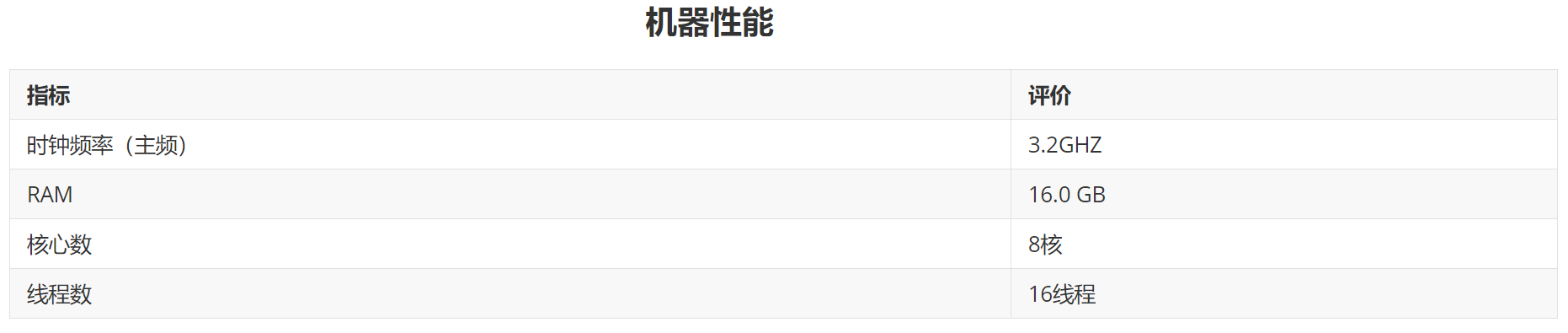
1. 考虑内存、速度开销综合比较AVL散列核链表散列性能


在散列的时候AVL散列的性能是优于有序链表的散列方式的,但是由于AVL树消耗更多的空间,导致AVL散列方式的组织成的字典大小是链表散列方式的1.5倍。这也就意味着,memcpy函数用时会增加1.5倍。综合二者,AVL在空间上的消耗不足以弥补其在时间上的提升,造成程序运行时间下降。应选择有序链表的散列方式。
2. 最终程序运行时间(MinGW编译下结果)
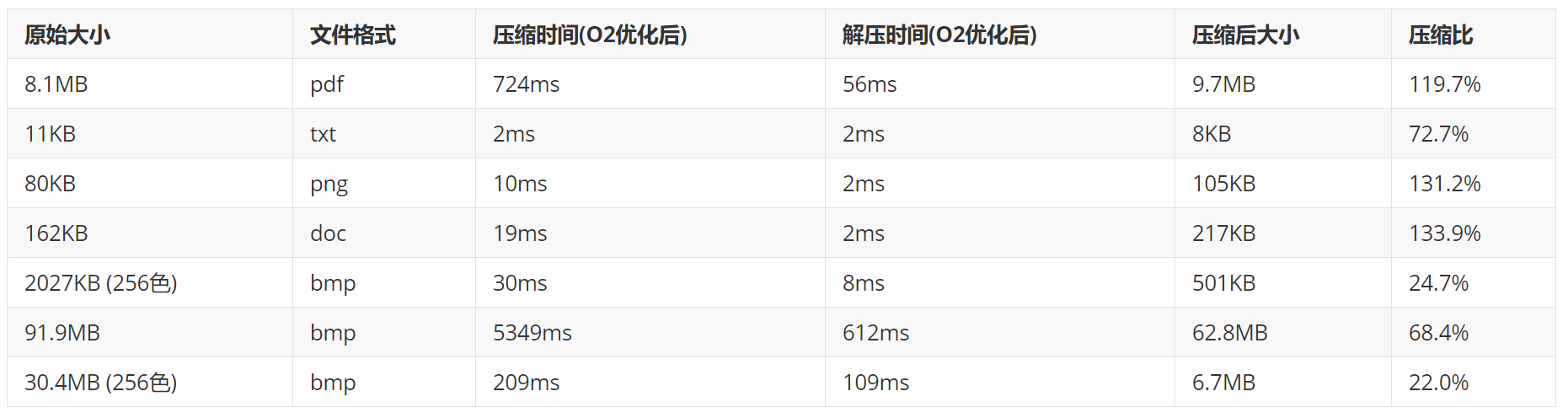
3. 分析:
从结果上看,应证了LZW压缩只对bmp文件、文本文件有较好的压缩效果。对pdf、png等文件格式,压缩比大于100%,原因是pdf、png等格式已经是非常优秀的压缩算法了。同时对比常用压缩软件的压缩时间,通过O2优化之后可以达到近似两倍的效果,已经比较可观了,应该还存在着可以改进的地方。
4. 压缩超大文件性能测试:
结果:内存占用率很小,不会发生内存泄漏,压缩时间可观。
























