![]()

Datagen is part of the LDBC project.
📜 If you wish to cite the LDBC SNB, please refer to the documentation repository.
- The Hadoop-based variant (managed in this repository) generates the Interactive SF0.1 to SF1000 data sets. These are used for the SNB Interactive v1 workload.
- Use the Spark-based Datagen for the Business Intelligence (BI) workload and for the Interactive v2 workload.
The LDBC SNB Data Generator (Datagen) is responsible for providing the datasets used by all the LDBC benchmarks. This data generator is designed to produce directed labelled graphs that mimic the characteristics of those graphs of real data. A detailed description of the schema produced by Datagen, as well as the format of the output files, can be found in the latest version of official LDBC SNB specification document.
- Releases
- Configuration
- Compilation and Execution
- Advanced Configuration
- Output
- Troubleshooting (including the out of disk space in
/tmpissue)
Producing large-scale data sets requires non-trivial amounts of memory and computing resources (e.g. SF100 requires 24GB memory and takes about 4 hours to generate on a single machine). To mitigate this, we have pregenerated data sets using 9 different serializers and the update streams using 17 different partition numbers:
- Serializers: csv_basic, csv_basic-longdateformatter, csv_composite, csv_composite-longdateformatter, csv_composite_merge_foreign, csv_composite_merge_foreign-longdateformatter, csv_merge_foreign, csv_merge_foreign-longdateformatter, ttl
- Partition numbers:
- 2^k for k in 1..10: 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024
- 6×2^k for k in 2..7: 24, 48, 96, 192, 384, 768
The data sets are available at the SURF/CWI data repository. We also provide direct links and download scripts.
This version of Datagen uses Hadoop to allow execution over multiple machines. Hadoop version 3.3.6+ is recommended.
Initialize the params.ini file as needed. For example, to generate the basic CSV files, issue:
cp params-csv-basic.ini params.iniThere are three main ways to run Datagen, each using a different approach to configure the amount of memory available.
- using a pseudo-distributed Hadoop installation,
- running the same setup in a Docker image,
- running on a distributed Hadoop cluster.
To configure the amount of memory available, set the HADOOP_CLIENT_OPTS environment variable.
To grab Hadoop, extract it, and set the environment values to sensible defaults, and generate the data as specified in the params-csv-params.ini template file, run the following script:
cp params-csv-basic.ini params.ini
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.3.6/hadoop-3.3.6.tar.gz
tar xf hadoop-3.3.6.tar.gz
export HADOOP_CLIENT_OPTS="-Xmx2G"
# set this to the Hadoop 3.3.6 directory
export HADOOP_HOME=`pwd`/hadoop-3.3.6
./run.shWhen using this setup, a typical issue is that Hadoop runs out of temp space. To fix this, use the workaround described in the Troubleshooting pages.
SNB datagen images are available via Docker Hub where you may find both the latest version of the generator as well as previous stable versions.
Alternatively, the image can be built with the provided Dockerfile. To build, execute the following command from the repository directory:
docker build . --tag ldbc/datagenSet the params.ini in the repository as for the pseudo-distributed case. The file will be mounted in the container by the --mount type=bind,source="$(pwd)/params.ini,target="/opt/ldbc_snb_datagen/params.ini" option. If required, the source path can be set to a different path.
The container outputs its results in the /opt/ldbc_snb_datagen/out/ directory which contains two sub-directories, social_network/ and substitution_parameters/. In order to save the results of the generation, a directory must be mounted in the container from the host. The driver requires the results be in the datagen repository directory. To generate the data, run the following command which includes changing the owner (chown) of the Docker-mounted volumes.
social_network/ directory:
rm -rf social_network/ substitution_parameters/ && \
docker run --rm \
--mount type=bind,source="$(pwd)/",target="/opt/ldbc_snb_datagen/out" \
--mount type=bind,source="$(pwd)/params.ini",target="/opt/ldbc_snb_datagen/params.ini" \
ldbc/datagen && \
sudo chown -R ${USER}:${USER} social_network/ substitution_parameters/If you need to raise the memory limit, use the -e HADOOP_CLIENT_OPTS="-Xmx..." parameter to override the default value. For SF1, -Xmx2G is recommended. For SF1000, -Xmx370G is sufficient.
Instructions are currently not provided.
To run the driver in a multi-threaded configuration, you need multiple update partitions. To generate these, use the numUpdatePartitions value in the params.ini file, e.g. to generate 4 partitions, use:
ldbc.snb.datagen.serializer.numUpdatePartitions:4
This will result in 4×2 update stream CSV files (for Persons and Forums).
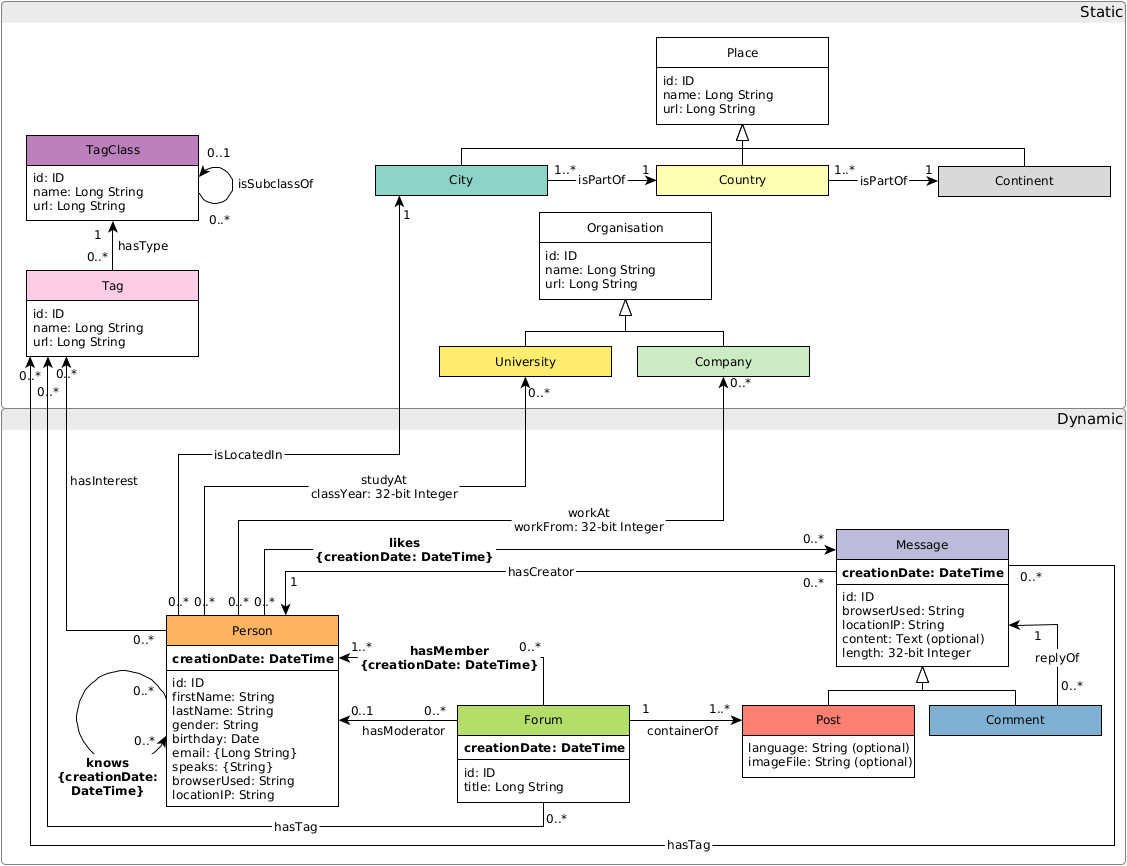
The graph schema is as follows:
- Apache Flink Loader: A loader of LDBC datasets for Apache Flink.