When a prospective employer looks at your GitHub repository they will read two things: your README and your notebook.
Unfortunately, sometimes they see something like this:
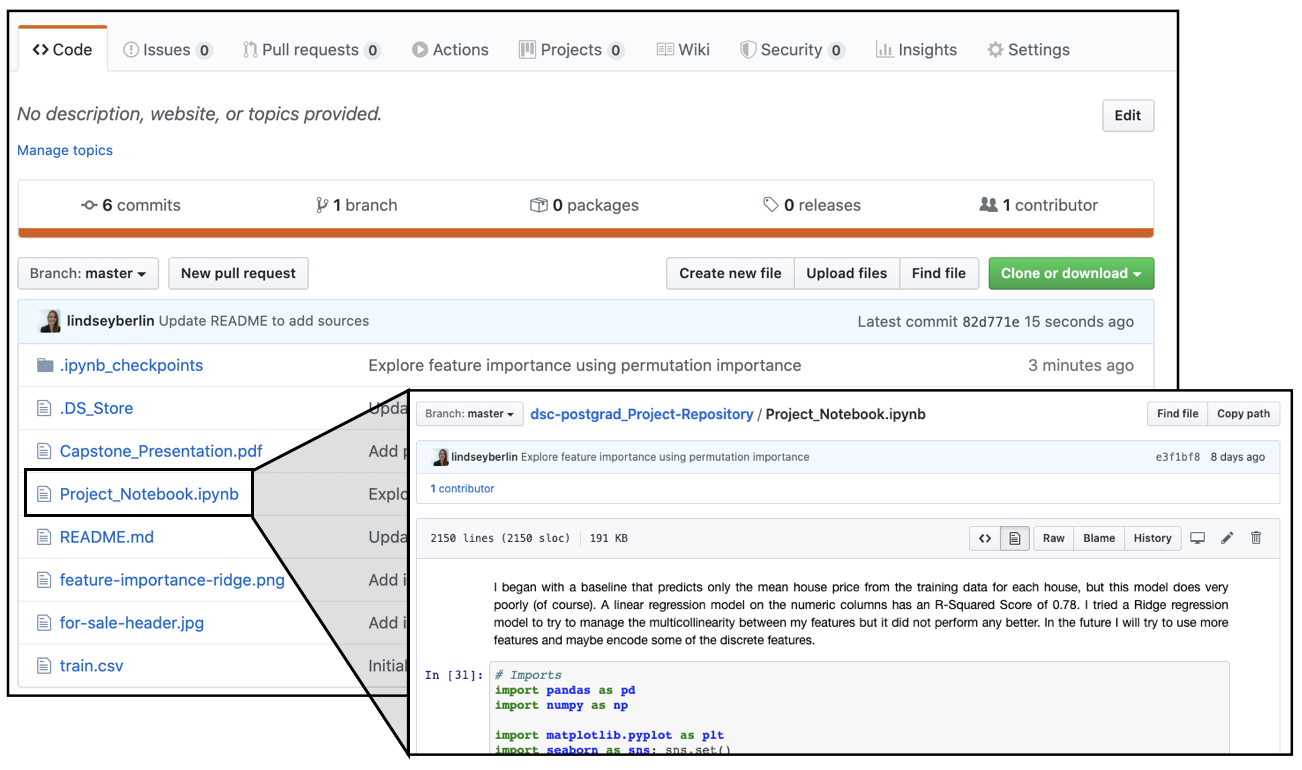
That notebook analysis may contain perfectly valid code, but it's not readable.
To fully communicate the quality of your work it needs to be readable. What does readability mean? It means the most important information is highlighted and complex code is explained.
Since your analysis is in a Jupyter notebook, you have the narrative of your analysis and important code all in the same place. You will use two different tools to enhance the readability of your notebook: markdown for the narrative and comments for the code. The same markdown techniques apply to your README as well.
You will be able to:
- Use markdown to enhance the readability of text
- Use comments to enhance the readability of code
Markdown is a plain text formatting syntax, that allows you to format text quickly without the need to write in a text editor. Markdown allows you to quickly format plain text using special characters like asterisks, dashes, underscores, etc. Markdown enables you to create headers, lists, code blocks and more without lifting your fingers off your keyboard.
For example, which chunk of text is more readable?
Example A:

or
Example B:
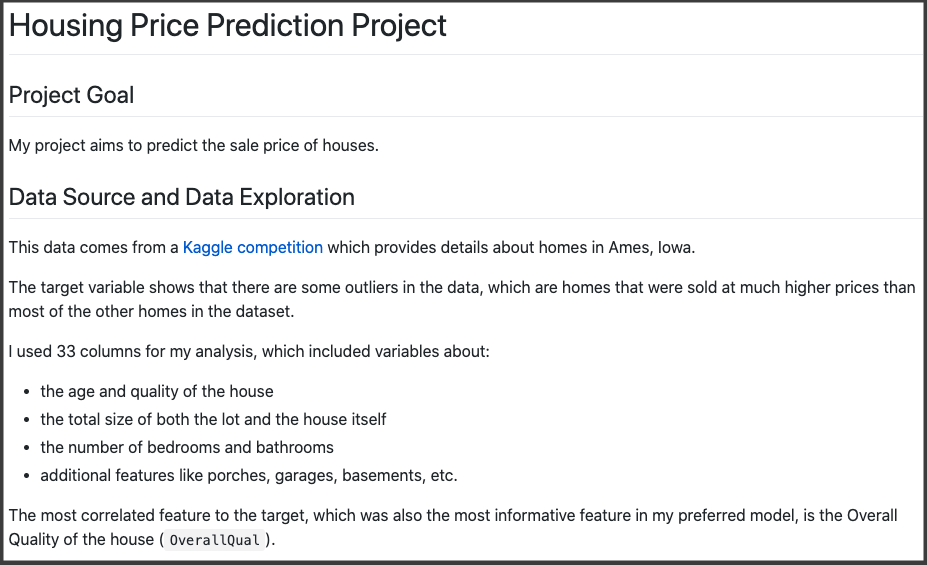
Example B! But what makes them different? The only difference between Examples A and B is that Example B adds Markdown syntax to Example A. Here is what Example B looks like before it is rendered:
# Housing Price Prediction Project
## Project Goal
My project aims to predict the sale price of houses.
When you use text editing software like Microsoft Word or Google Docs, you use different level headings to create a consistent hierarchy of information in your documentation. H1 headings are the highest level, like the title of the document, while H2 and H3 headings are lower in value. You denote a line is a heading by putting a hash mark next to the text, so the title in your analysis:

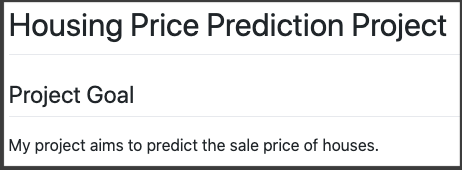
If you add one hash mark:
# Housing Price Prediction Project
The text becomes large and bold:
The title of your analysis should have the highest level of header and your section headings, such as "Business Question" or "Data Understanding" should have H2 headings, etc.
You can practice your understanding of markdown using the following exercise:
- Examine the plaintext below:
- Now examine the rendered text below and find 4 examples of markdown being used to enhance the readability of the text:
- Once you have identified four examples, look at the numbered image below to confirm your answers:
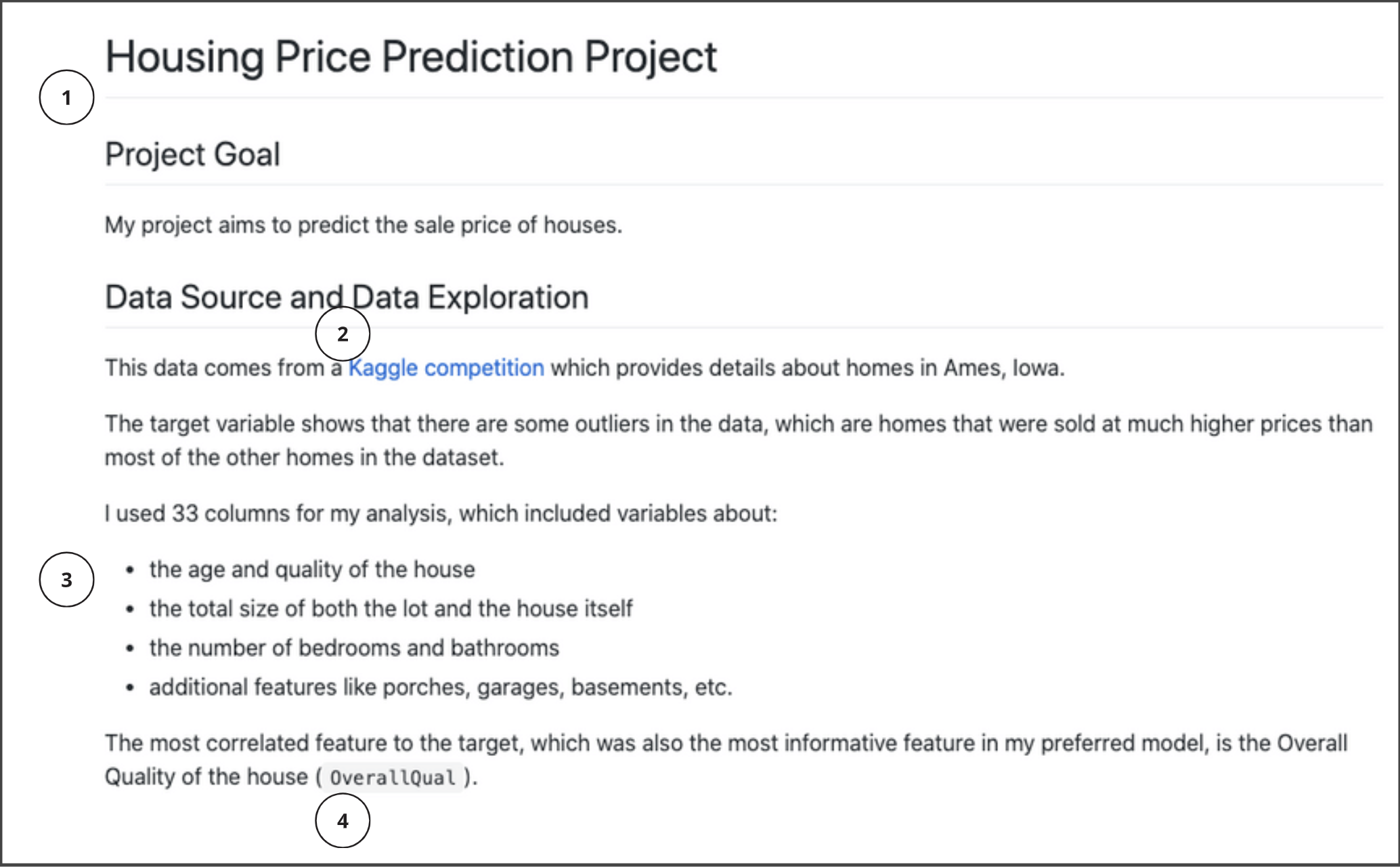
-
Review the numbered answers listed below to confirm what was updated:
- headings and subheadings, used to show the organization of the file
- link embedding, used to create linked text so the full text of a URL does not need to be shown
- bulleted list, used to effectively convey lists
- code text, used to show that this is the name of a variable
Try updating the text in our messy repo to match the updated formatting.
The Zen of Python states that "Readability counts". You covered how to make text more readable, but what about code? Enter code comments and docstrings.
Code comments can show up three main ways:
# Prints the zen of python
print(this)
print(this) # prints the zen of python
# print(this)
print("something else")
If you were given the above bit of code, you could probably figure out what was happening... but you'd need to read through the code itself, and maybe run the cells and play with the code, in order to fully follow not only what the code does but also why the code was written.

If you were instead given this bit of code above, you'd be able to instantly read through exactly what each bit was doing. The comments also clearly show why the code is running. Note that this example uses both markdown cells and code comments, for different reasons! The markdown gives an overview and more of the rationale behind the code, while the code comments talk through what each piece of code actually does.
Docstrings are multi-line comments that usually explain what a function, class, or module is intended to do. Whenever you type shift+tab in a code cell and get the documentation? The documentation is populated by docstrings written in the code itself. Examine the source code for the Pandas groupby object to see docstrings in action.
"""
docstrings are the text in triple quotes
that can take multiple lines and still not interfere
with the code
"""
Docstrings help future employers AND our future selves to understand our code at a later date. It not only makes code more readable, but makes it more usable in the future.
def summarize_dataframe(df):
summary = pd.DataFrame(df.dtypes,columns=['dtypes'])
summary = summary.reset_index()
summary['Name'] = summary['index']
summary = summary[['Name','dtypes']]
summary['Missing'] = df.isnull().sum().values
summary['Uniques'] = df.nunique().values
return summaryIf you wanted to make the above function more readable, you could use BOTH comments and docstrings:
def summarize_dataframe(df):
'''
Summarizes each column in a Pandas dataframe, where each row of the
summary output is a column of the input dataframe, df
Will show the datatype of data in the column, the number of missing values
in that column, and the number of unique values in the column
-
Input:
df : Pandas dataframe
-
Output:
summary : Pandas dataframe, now showing column details
'''
summary = pd.DataFrame(df.dtypes,columns=['dtypes'])
summary = summary.reset_index()
summary['Name'] = summary['index'] # name of each variable
summary = summary[['Name','dtypes']] # data type of each variable
summary['Missing'] = df.isnull().sum().values # number of missing values
summary['Uniques'] = df.nunique().values # number of unique values
return summary- Ultimate guide for readable code: Pep8 standards
- If you want more information on docstring expectations look here
Great, now that you learned more about markdown and code readability, let's put this theory into practice!