- 2018/06/09 - 添加增加node剧本
- 2019/03/08 - 推倒重来,仿照kubeadm,但是支持多网卡下部署,etcd支持单独的机器跑
- 2019/03/14 - 修复setup里yum cache报错,优化etcd非master成员场景下的逻辑,18号:改善未在fstab关闭swap和模板渲染回车问题,增加更多可选设置参数
- 2019/03/20 - 增加管理组件可选日志写入文件和logrotate配置,添加增加node剧本
- 2019/03/21 - 增加有备份db文件下一键恢复etcd集群剧本,26号:增加etcd备份脚本
- 2019/04/04 - 修改haproxy为七层check,优化和向后兼容apiserver和etcd配置文件
- 2019/04/10 - 增加证书ip预留和增加master剧本,以及理论上修复了部分人证书生成有误的问题
- 2019/08/07 - 版本变更到v1.13.9,并增加组件ep,部分逻辑写法修复
- 2019/08/23 - 版本变更到v1.13.10避免golang的net包漏洞
- 2019/09/19 - 版本变更到v1.13.11增加部分内核参数增加chrony可选
系统可采用Ubuntu 16.x(未完成)与CentOS 7.x(CentOS建议使用最新的)
本次安裝的版本:
- Kubernetes v1.13.11 (HA高可用)
- CNI plugins v0.8.1
- Etcd v3.3.15
- flanneld v0.11.0
- Calico (不写,可以自行去找yaml部署)
- Docker CE 18.06.03(应该能19.03的)
hosts文件写ip来支持多网卡部署
因为kubeadm扣的步骤,路径九成九一致,剧本里路径不给自定义
HA是基于VIP,无法用于云上(测试过青云默认解除ip和mac绑定可以飘VIP(同时青云的话记得注释掉setup/tasks/centos.yml里的NetworkManager那行),阿里不行,存在ip和mac绑定,所以flannel的host-gw应该也用不了),阿里四层SLB也有问题
安装过程是参考的Kubernetes v1.13.11 HA全手动苦工安装教学
下面是我的配置,电脑配置低就两个Node节点,master节点建议也跑kubelet但是请打上污点,聚合路由有空测试试试
| IP | Hostname | CPU | Memory |
|---|---|---|---|
| 172.16.1.3 | k8s-m1 | 2 | 2G |
| 172.16.1.4 | k8s-m2 | 2 | 2G |
| 172.16.1.5 | k8s-m3 | 2 | 2G |
| 172.16.1.6 | k8s-n1 | 2 | 2G |
| 172.16.1.7 | k8s-n1 | 2 | 2G |
- 每台主机端口和密码最好一致(不一致最好懂点ansible修改hosts文件)
- 单master也可以玩
centos通过yum或者pip安装最新版ansible(role的一些写法依赖较新版本的ansible)
#可以yum安装指定版本或者离线安装 yum install -y https://releases.ansible.com/ansible/rpm/release/epel-7-x86_64/ansible-2.7.8-1.el7.ans.noarch.rpm
yum install -y wget epel-release && yum install -y python-pip git sshpass
pip install ansible
# 嫌弃慢就下面的
# pip install --no-cache-dir ansible -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
#离线安装ansible的话可以先下载下来用yum解决依赖
yum install wget -y 1 > /dev/null
wget https://releases.ansible.com/ansible/rpm/release/epel-7-x86_64/ansible-2.7.8-1.el7.ans.noarch.rpm
yum localinstall ansible-2.7.8-1.el7.ans.noarch.rpm -y
1 git clone
git clone https://github.com/zhangguanzhang/Kubernetes-ansible.git
cd Kubernetes-ansible
2 配置脚本属性
-
修改当前目录ansible的
inventory/hosts分组成员文件 -
修改
group_vars/all.yml里面的参数
- ansible_ssh_pass为ssh密码(如果每台主机密码不一致请注释掉
all.yml里的ansible_ssh_pass后按照的hosts文件里的注释那样写上每台主机的密码) VIP为高可用HA的虚ip,和master在同一个网段没有被使用过的ip即可,NETMASK为VIP的掩码,certSANs是预留ip后续扩节点INTERFACE_NAME为各机器的ip所在网卡名字Centos可能是ens33或eth0,如果业务做了bond是bond后的网卡,看情况自行修改.测试vip可用度是某台机器手动添加ip addr add/del $VIP/$MASK dev $interface后其他机器手动ping下- 其余的参数按需修改,不熟悉最好别乱改,
roles/node/templates/kubelet-conf.yml.j2里可以修改下gc和预留资源 - 涉及到一些集群更新状态的参数参考 https://github.com/kubernetes-sigs/kubespray/blob/master/docs/kubernetes-reliability.md
nodeStatusUpdate变量对应下面的三种+默认值任选其一,单独选项的值优先级高nodeStatusUpdate,
--node-status-update-frequency为kubelet上传自身状态
--node-monitor-period为kube-controller多久查看一次node状态
--node-monitor-grace-period为kube-controller认为node多久无响应后是NotReady
--pod-eviction-timeout为kube-controller认为node无响应后多久驱逐该node上的pod
- Fast update and Fast Reaction
| 参数 | 值 | 默认值 |
|---|---|---|
| --node-status-update-frequency | 4s | 10s |
| --node-monitor-period | 2s | 5s |
| --node-monitor-grace-period | 20s | 40s |
| --pod-eviction-timeout | 30s | 5m |
- Medium Update and Average Reaction
| 参数 | 值 | 默认值 |
|---|---|---|
| --node-status-update-frequency | 20s | 10s |
| --node-monitor-period | 5s | 5s |
| --node-monitor-grace-period | 2m | 40s |
| --pod-eviction-timeout | 1m | 5m |
- Low Update and Show reaction
| 参数 | 值 | 默认值 |
|---|---|---|
| --node-status-update-frequency | 1m | 10s |
| --node-monitor-period | 5s | 5s |
| --node-monitor-grace-period | 5m | 40s |
| --pod-eviction-timeout | 1m | 5m |
- 运行下
ansible all -m ping测试连通性
3 开始运行安装,下面是用法(小白用法)
- ----- setup.yml -------
- setup: 机器设置(关闭swap安装一些依赖+ntp)+内核升级并重启,例如
ansible-playbook setup.yml,带上-e 'kernel=false'不会升级内核.dnsmasq不是错误,重启后连上后进剧本目录ansible all -m ping看看连通性 - ----- deploy.yml -------
- docker: 安装docker,默认是18.06,其他版本自行修改
group_vars/all.yml, 运行命令为ansible-playbook deploy.yml --tags docker - 这步不是标签,手动运行
bash get-binaries.sh all: 通过docker下载k8s和etcd的二进制文件还有cni插件,觉得不信任可以自己其他方式下载,cni插件可能不好下载.如果是运行剧本机器不是master[0]请自行下载相关文件到/usr/local/bin - tls: 生成证书和管理组件的kubeconfig,kubeconfig生成依赖kubectl命令,此步确保已经下载有.运行命令为
ansible-playbook deploy.yml --tags tls,下面的也是tag改tags后面标签为下面的即可 - etcd: 部署etcd,etcd可以非master上跑,按照提示设置好hosts文件即可. 另外要注意3.3开始配置文件里的
auto-compaction-retention值类型从int更改为字符串了,生成alias别名脚本存放在目录/etc/profile.d/etcd.sh,命令为etcd_v2和etcd_v3方便操作etcd,etcd成员上的脚本目录有etcd_cron.sh备份脚本生成,可以复制相关证书在etcd外上备份,用法-c保留几个备份,-d指定备份目录 - HA: keepalived+haproxy
- master: 管理组件,检测apiserver端口那个
curl -sk https://master[0]:6443/healthz的uri模块写法不知道是不是没调对经常报错,测试apiserver端口这步会出现带有...ignoring报错请忽略,执行完运行下kubectl get cs有输出就不用管 - bootstrap: 生成bootstrap文件给kubelet注册用
- node: kubelet,执行完后看看
kubectl get node有没有,没有就复制启动参数前台运行debug,不会就翻到现在页面的结尾部分 - addon: kube-proxy,flannel,coredns.metrics-server flannel二进制跑请运行前下载二进制文件
bash get-binaries.sh flanneld,否则提前拉取镜像使用命令拉取ansible Allnode -m shell -a 'curl -s https://zhangguanzhang.github.io/bash/pull.sh | bash -s -- quay.io/coreos/flannel:v0.11.0-amd64', flanneld错误的话请按照本页面最后面的方法去debug错误信息到issue里
4 勇者玩法
- setup后执行
ansible-playbook deploy.yml --tags docker然后运行脚本bash get-binaries.sh all确认下载完后运行ansible-playbook deploy.yml --skip-tags docker
运行到master后可以查看下管理组件状态
$ kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
运行完node后kubectl get node -o wide查看注册上来否
运行完addon后查看node状态是否为ready,以及kube-system命名空间下pod是否运行
不想master跑可以按照输出的命令打污点
kubectl taint nodes ${node_name} node-role.kubernetes.io/master="":NoSchedule
master的ROLES字段默认是none,它显示的值是来源于一个label
kubectl label node ${node_name} node-role.kubernetes.io/master=""
kubectl label node ${node_name} node-role.kubernetes.io/node=""
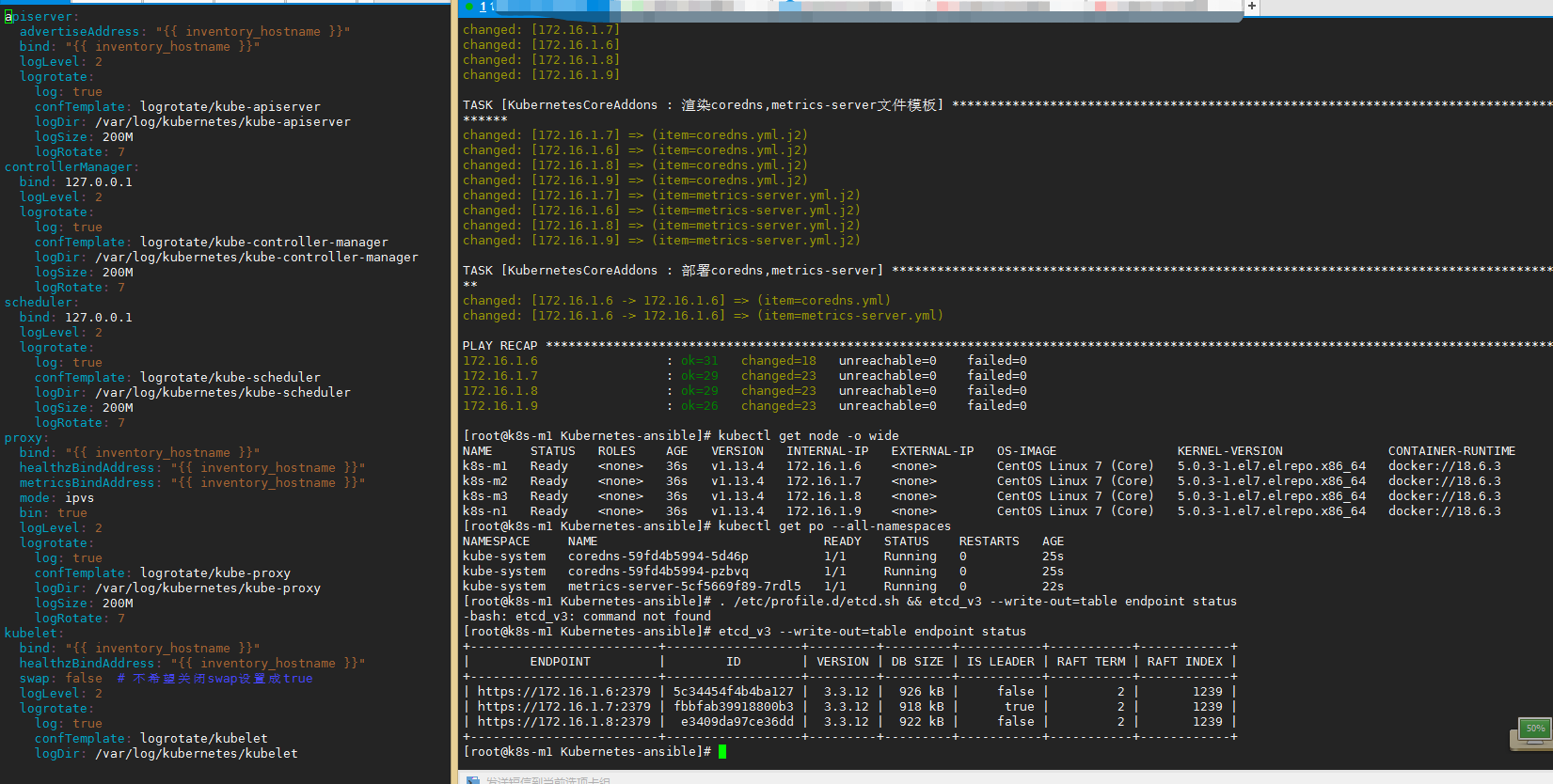
5 后续添加Node节点
- 在当前的ansible目录改hosts,添加[newNode]分组写上成员和信息,role是复用的,所以不要在此时修改一些标志位参数,例如flanneld.type和bin
- 执行
ansible-playbook setup.yml -e 'run=newNode',此时也可以带上-e kernel=false不升级内核,然后等待重启完可以ping通后执行ansible-playbook addNode.yml - 然后查看是否添加上
$ kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-m1 Ready <none> 28m v1.13.11 172.16.1.3 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-m2 Ready <none> 28m v1.13.11 172.16.1.4 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-m3 Ready <none> 28m v1.13.11 172.16.1.5 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-n1 Ready <none> 28m v1.13.11 172.16.1.6 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
k8s-n2 Ready <none> 6s v1.13.11 172.16.1.7 <none> CentOS Linux 7 (Core) 5.0.3-1.el7.elrepo.x86_64 docker://18.6.3
6 备份恢复
- 把etcdctl和证书复制了单独一台机器上就可以外部操作和备份集群了,etcd备份:
etcd_v3 snapshot save test.db - 恢复备份执行
ansible-playbook restoreETCD.yml -e 'db=/root/Kubernetes-ansible/test.db',db指定db文件在剧本机器的路径 etcd_v3 --write-out=table endpoint status查看状态
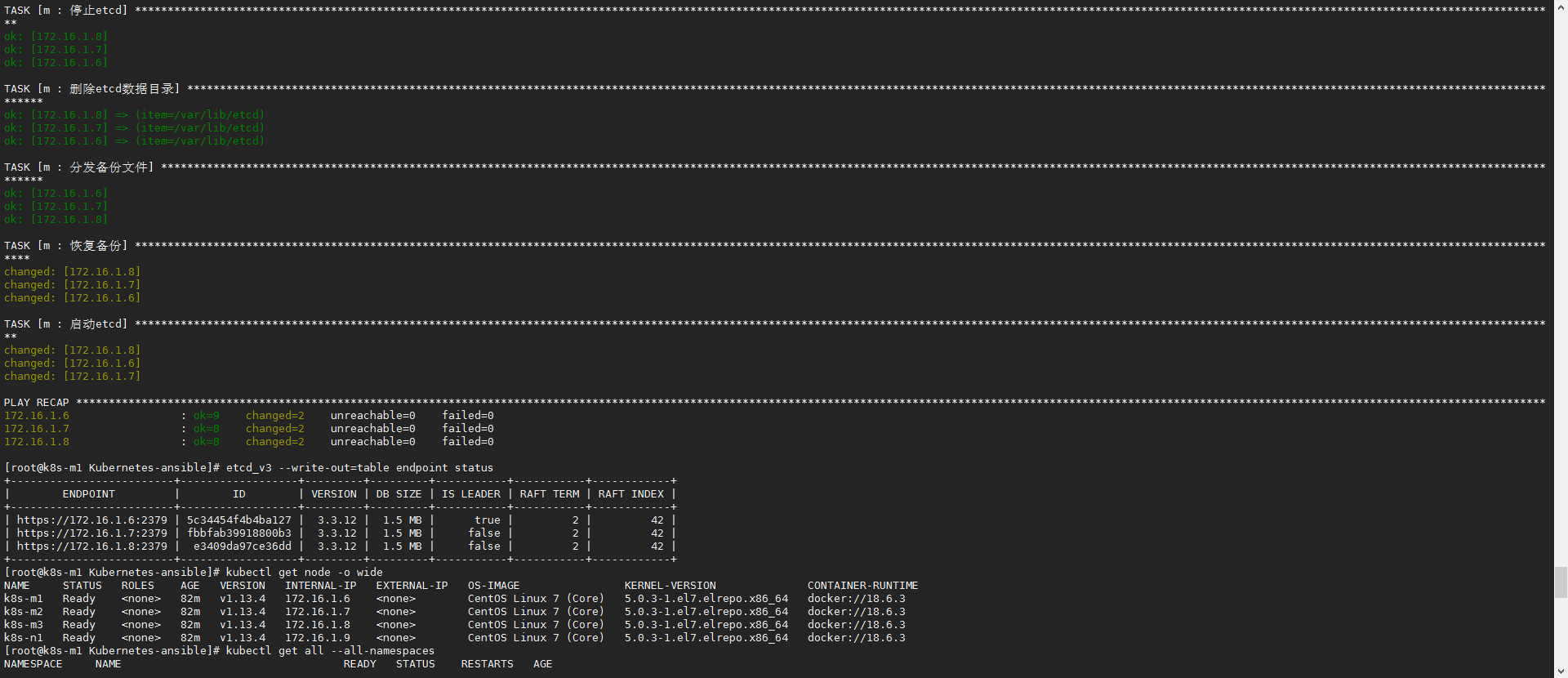
7 增加master(没事不要随便扩master)
- ca文件还在就能增加,增加的时候可能会有空窗期,理论上我写成滚动了,但是会丢一些apiserver的session,没事不要尝试扩master
Master下面子组取消newMaster的注释,newMaster组取消注释填上信息,然后执行ansible-playbook preRedo.yml设置新机器的系统设置,然后执行ansible-playbook redo.yml- 步骤是检查ca文件存在否,设置新机器系统设置重启,然后安装docker和剧本复用生成证书发送证书,重启进程
后面的一些Extraaddon后续更新(当然也别等我更新,集群到node那了所谓的coredns和flannel后就可以用可以去找官方的addon部署)
例如kubelet
$ systemctl cat kubelet
# /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/kubernetes/kubernetes
After=docker.service
Requires=docker.service
[Service]
ExecStart=/usr/local/bin/kubelet \
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig \
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \
--config=/etc/kubernetes/kubelet-conf.yml \
--hostname-override=k8s-m1 \
--pod-infra-container-image=100.64.2.62:9999/pause-amd64:3.1 \
--allow-privileged=true \
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin \
--cert-dir=/etc/kubernetes/pki \
--logtostderr=false \
--log-dir=/var/log/kubernetes/kubelet \
--v=2
Restart=always
RestartSec=10s
[Install]
WantedBy=multi-user.target
把ExecStart的部分复制在终端运行,去掉--logtostderr和--log-dir相关的不前台打印日志的选项,--v是日志等级,1-8
$ /usr/local/bin/kubelet \
--bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig \
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \
--config=/etc/kubernetes/kubelet-conf.yml \
--hostname-override=k8s-m1 \
--pod-infra-container-image=100.64.2.62:9999/pause-amd64:3.1 \
--allow-privileged=true \
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin \
--cert-dir=/etc/kubernetes/pki \
--logtostderr=false \
--v=2
另外kubelet启动报下面错的话,请开启ipv6
docker_service.go:401] Streaming server stopped unexpectedly: listen tcp [::1]:0: bind: cannot assign requested address
开启ipv6
ansible all -m shell -a 'echo 0 > /proc/sys/net/ipv6/conf/all/disable_ipv6'
sed -ri sed -rn '/f\.[a|d].+ipv6/s#1#0#' /etc/sysctl.d/k8s-sysctl.conf
ansible all -m copy -a 'src=/etc/sysctl.d/k8s-sysctl.conf dest=/etc/sysctl.d/k8s-sysctl.conf'
二进制flannel开启前台运行debug得手动export加环境变量或者下面行内环境变量
NODE_NAME=k8s-m1 /usr/local/bin/flanneld ......