/$$ /$$ /$$ /$$ /$$
| $$ | $$ |__/ | $$ | $$
/$$$$$$$ /$$$$$$ /$$$$$$ /$$$$$$$| $$ /$$ /$$$$$$$ /$$ /$$$$$$ | $$$$$$$ /$$$$$$
/$$_____/|_ $$_/ /$$__ $$ /$$_____/| $$ /$$/ /$$_____/| $$ /$$__ $$| $$__ $$|_ $$_/
| $$$$$$ | $$ | $$ \ $$| $$ | $$$$$$/ | $$$$$$ | $$| $$ \ $$| $$ \ $$ | $$
\____ $$ | $$ /$$| $$ | $$| $$ | $$_ $$ \____ $$| $$| $$ | $$| $$ | $$ | $$ /$$
/$$$$$$$/ | $$$$/| $$$$$$/| $$$$$$$| $$ \ $$ /$$$$$$$/| $$| $$$$$$$| $$ | $$ | $$$$/
|_______/ \___/ \______/ \_______/|__/ \__/|_______/ |__/ \____ $$|__/ |__/ \___/
/$$ \ $$
:) = +$ :( = -$ | $$$$$$/
\______/
Stock analyzer and stock predictor using Elasticsearch, Twitter, News headlines and Python natural language processing and sentiment analysis. How much do emotions on Twitter and news headlines affect a stock's price? Let's find out ...


- Python 3. (tested with Python 3.6.5)
- Elasticsearch 5.
- Kibana 5.
- elasticsearch python module
- nltk python module
- requests python module
- tweepy python module
- beautifulsoup4 python module
- textblob python module
- vaderSentiment python module
$ git clone https://github.com/shirosaidev/stocksight.git
$ cd stocksightInstall python requirements using pip
pip install -r requirements.txt
Create a new twitter application and generate your consumer key and access token. https://developer.twitter.com/en/docs/basics/developer-portal/guides/apps.html https://developer.twitter.com/en/docs/basics/authentication/guides/access-tokens.html
Copy config.py.sample to config.py
Set elasticsearch settings in config.py for your env
Add twitter consumer key/access token and secrets to config.py
Edit config.py and modify NLTK tokens required/ignored and twitter feeds you want to mine. NLTK tokens required are keywords which must be in tweet before adding it to Elasticsearch (whitelist). NLTK tokens ignored are keywords which if are found in tweet, it will not be added to Elasticsearch (blacklist).
Run sentiment.py to create 'stocksight' index in Elasticsearch and start mining and analyzing Tweets using keywords
$ python sentiment.py -k TSLA,'Elon Musk',Musk,Tesla --debugStart mining and analyzing Tweets from feeds in config using cached user ids from file
$ python sentiment.py -f twitteruserids.txt --debugStart mining and analyzing News headlines and following headline links and scraping relevant text on landing page
$ python sentiment.py -n TSLA --followlinks --debugRun stockprice.py to add stock prices to 'stocksight' index in Elasticsearch
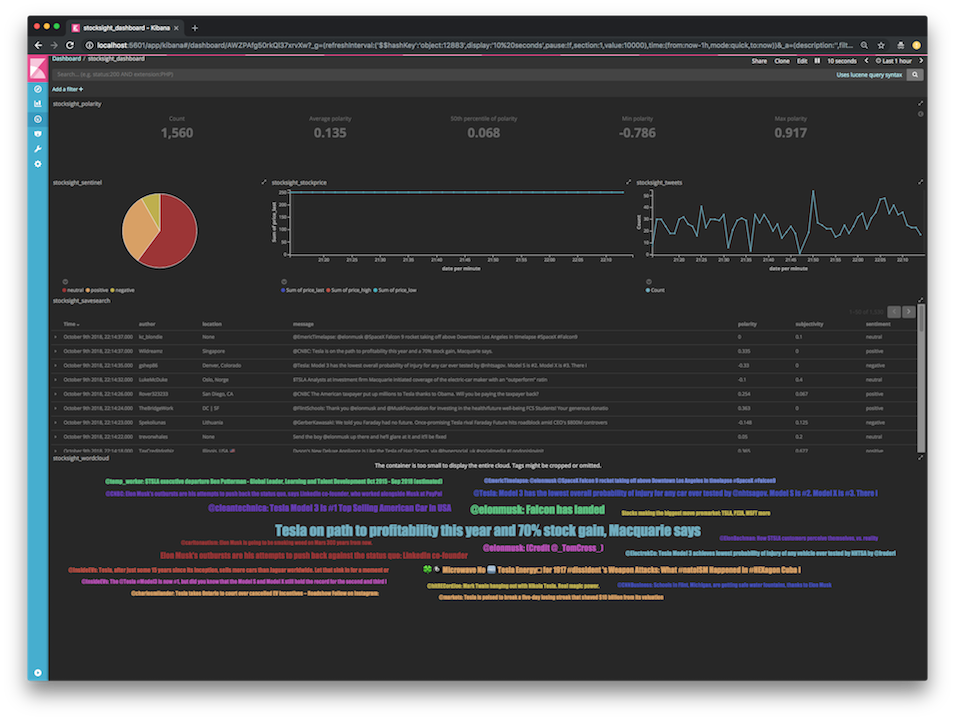
$ python stockprice.py -s TSLA --debugLoad 'stocksight' index in Kibana and import export.json file for visuals/dashboard.
usage: sentiment.py [-h] [-i INDEX] [-d] [-k KEYWORDS] [-u URL] [-f FILE]
[-n SYMBOL] [--frequency FREQUENCY] [--followlinks] [-v]
[--debug] [-q] [-V]
optional arguments:
-h, --help show this help message and exit
-i INDEX, --index INDEX
Index name for Elasticsearch (default: stocksight)
-d, --delindex Delete existing Elasticsearch index first
-k KEYWORDS, --keywords KEYWORDS
Use keywords to search for in Tweets instead of feeds.
Separated by comma, case insensitive, spaces are ANDs
commas are ORs. Example: TSLA,'Elon
Musk',Musk,Tesla,SpaceX
-u URL, --url URL Use twitter users from any links in web page at url
-f FILE, --file FILE Use twitter user ids from file
-n SYMBOL, --newsheadlines SYMBOL
Get news headlines instead of Twitter using stock
symbol, example: TSLA
--frequency FREQUENCY
How often in seconds to retrieve news headlines
(default: 120 sec)
--followlinks Follow links on news headlines and scrape relevant
text from landing page
-v, --verbose Increase output verbosity
--debug Debug message output
-q, --quiet Run quiet with no message output
-V, --version Prints version and exits
usage: stockprice.py [-h] [-i INDEX] [-d] [-s SYMBOL] [-f FREQUENCY] [-v]
[--debug] [-q] [-V]
optional arguments:
-h, --help show this help message and exit
-i INDEX, --index INDEX
Index name for Elasticsearch (default: stocksight)
-d, --delindex Delete existing Elasticsearch index first
-s SYMBOL, --symbol SYMBOL
Stock symbol to use, example: TSLA
-f FREQUENCY, --frequency FREQUENCY
How often in seconds to retrieve stock data, default:
120 sec
-v, --verbose Increase output verbosity
--debug Debug message output
-q, --quiet Run quiet with no message output
-V, --version Prints version and exits