连续爬取一个或多个新浪微博用户(如Dear-迪丽热巴、郭碧婷)的数据,并将结果信息写入文件。写入信息几乎包括了用户微博的所有数据,主要有用户信息和微博信息两大类,前者包含用户昵称、关注数、粉丝数、微博数等等;后者包含微博正文、发布时间、发布工具、评论数等等,因为内容太多,这里不再赘述,详细内容见输出部分。具体的写入文件类型如下:
- 写入csv文件(默认)
- 写入MySQL数据库(可选)
- 写入MongoDB数据库(可选)
- 下载用户微博中的原始图片(可选)
- 下载用户微博中的视频(可选)
用户信息
- 用户id:微博用户id,如"1669879400"
- 用户昵称:微博用户昵称,如"Dear-迪丽热巴"
- 性别:微博用户性别
- 微博数:用户的全部微博数(转发微博+原创微博)
- 粉丝数:用户的粉丝数
- 关注数:用户关注的微博数量
- 简介:用户简介
- 主页地址:微博移动版主页url,如https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400
- 头像url:用户头像url
- 高清头像url:用户高清头像url
- 微博等级:用户微博等级
- 会员等级:微博会员用户等级,普通用户该等级为0
- 是否认证:用户是否认证,为布尔类型
- 认证类型:用户认证类型,如个人认证、企业认证、政府认证等
- 认证信息:为认证用户特有,用户信息栏显示的认证信息
微博信息
- 微博id:微博的id,为一串数字形式
- 微博bid:微博的bid,与cookie版中的微博id是同一个值
- 微博内容:微博正文
- 原始图片url:原创微博图片和转发微博转发理由中图片的url,若某条微博存在多张图片,每个url以英文逗号分隔,若没有图片则值为''
- 视频url: 微博中的视频url,若微博中没有视频,则值为''
- 微博发布位置:位置微博中的发布位置
- 微博发布时间:微博发布时的时间,精确到天
- 点赞数:微博被赞的数量
- 转发数:微博被转发的数量
- 评论数:微博被评论的数量
- 微博发布工具:微博的发布工具,如iPhone客户端、HUAWEI Mate 20 Pro等,若没有则值为''
- 话题:微博话题,即两个#中的内容,若存在多个话题,每个url以英文逗号分隔,若没有则值为''
- @用户:微博@的用户,若存在多个@用户,每个url以英文逗号分隔,若没有则值为''
- 原始微博:为转发微博所特有,是转发微博中那条被转发的微博,存储为字典形式,包含了上述微博信息中的所有内容,如微博id、微博内容等等
- 结果文件:保存在当前目录weibo文件夹下以用户昵称为名的文件夹里,名字为"user_id.csv"形式
- 微博图片:原创微博中的图片,保存在以用户昵称为名的文件夹下的img文件夹里
- 微博视频:原创微博中的视频,保存在以用户昵称为名的文件夹下的video文件夹里
以爬取迪丽热巴的微博为例。她的微博昵称为"Dear-迪丽热巴",id为1669879400,用户id获取方法见如何获取user_id。我们选择爬取她的全部原创微博。具体方法是将weibo.py文件的main函数主要部分修改为如下代码:
# 以下是程序配置信息,可以根据自己需求修改
filter = 1 # 值为0表示爬取全部微博(原创微博+转发微博),值为1表示只爬取原创微博
since_date = '1900-01-01' # 起始时间,即爬取发布日期从该值到现在的微博,形式为yyyy-mm-dd
"""mongodb_write值为0代表不将结果写入MongoDB数据库,1代表写入;若要写入MongoDB数据库,
请先安装MongoDB数据库和pymongo,pymongo安装方法为命令行运行:pip install pymongo"""
mongodb_write = 0
"""mysql_write值为0代表不将结果写入MySQL数据库,1代表写入;若要写入MySQL数据库,
请先安装MySQL数据库和pymysql,pymysql安装方法为命令行运行:pip install pymysql"""
mysql_write = 0
pic_download = 1 # 值为0代表不下载微博原始图片,1代表下载微博原始图片
video_download = 1 # 值为0代表不下载微博视频,1代表下载微博视频
wb = Weibo(filter, since_date, mongodb_write, mysql_write,
pic_download, video_download)
user_id_list = ['1669879400']
wb.start(user_id_list)代码具体含义注释里都有,不在赘述。设置完成后运行程序:
$ python weibo.py程序会自动生成一个weibo文件夹,我们以后爬取的所有微博都被存储在weibo文件夹里。然后程序在该文件夹下生成一个名为"Dear-迪丽热巴"的文件夹,迪丽热巴的所有微博爬取结果都在这里。"Dear-迪丽热巴"文件夹里包含一个csv文件、一个img文件夹和一个video文件夹,img文件夹用来存储下载到的图片,video文件夹用来存储下载到的视频。如果你设置了保存数据库功能,这些信息也会保存在数据库里,数据库设置见设置数据库部分。
csv文件结果如下所示:
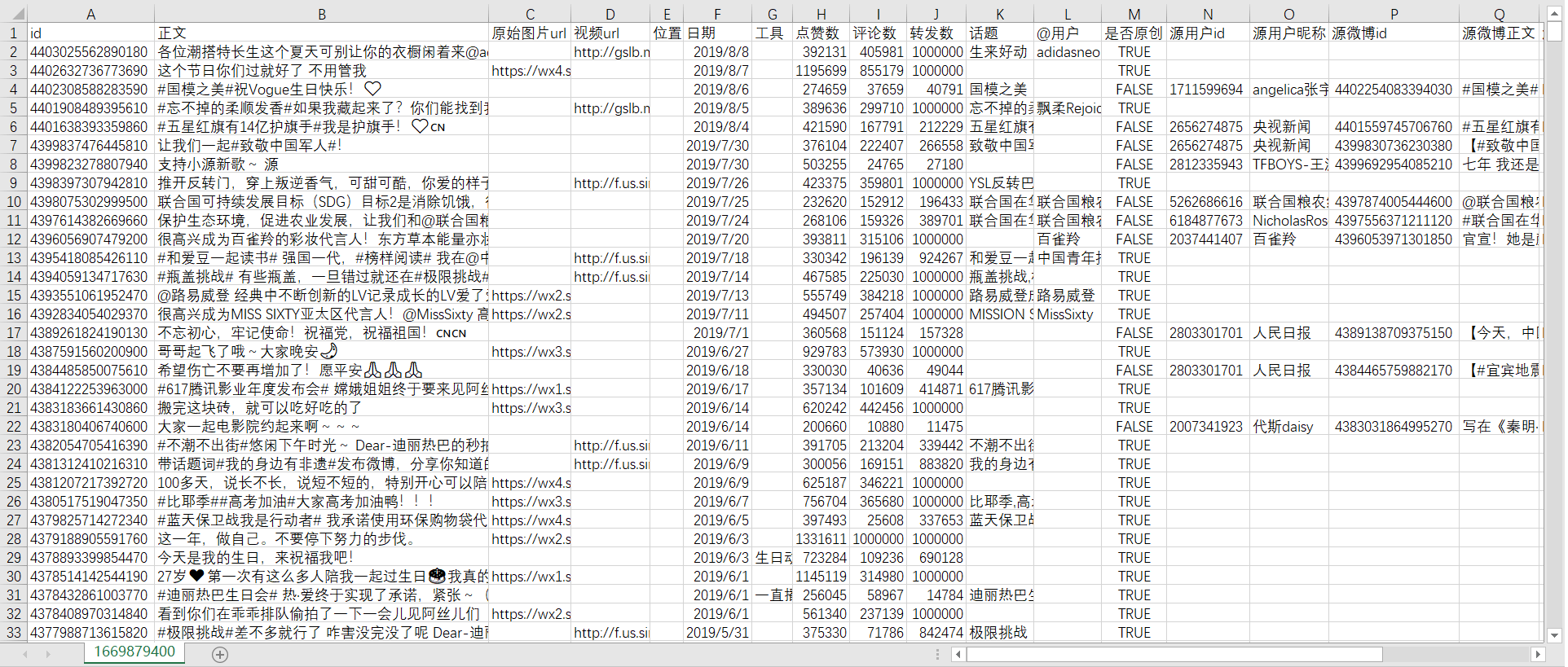
本csv文件是爬取“全部微博”(原创微博+转发微博)的结果文件。因为迪丽热巴很多微博本身都没有图片、发布工具、位置、话题和@用户等信息,所以当这些内容没有时对应位置为空。"是否原创"列用来标记是否为原创微博,
当为转发微博时,文件中还包含转发微博的信息。为了简便起见,姑且将转发微博中被转发的原始微博称为源微博,它的用户id、昵称、微博id等都在名称前加上源字,以便与目标用户自己发的微博区分。对于转发微博,程序除了获取用户原创部分的信息,还会获取源用户id、源用户昵称、源微博id、源微博正文、源微博原始图片url、源微博位置、源微博日期、源微博工具、源微博点赞数、源微博评论数、源微博转发数、源微博话题、源微博@用户等信息。原创微博因为没有这些转发信息,所以对应位置为空。若爬取的是"全部原创微博",则csv文件中不会包含"是否原创"及其之后的转发属性列;
下载的图片如下所示:
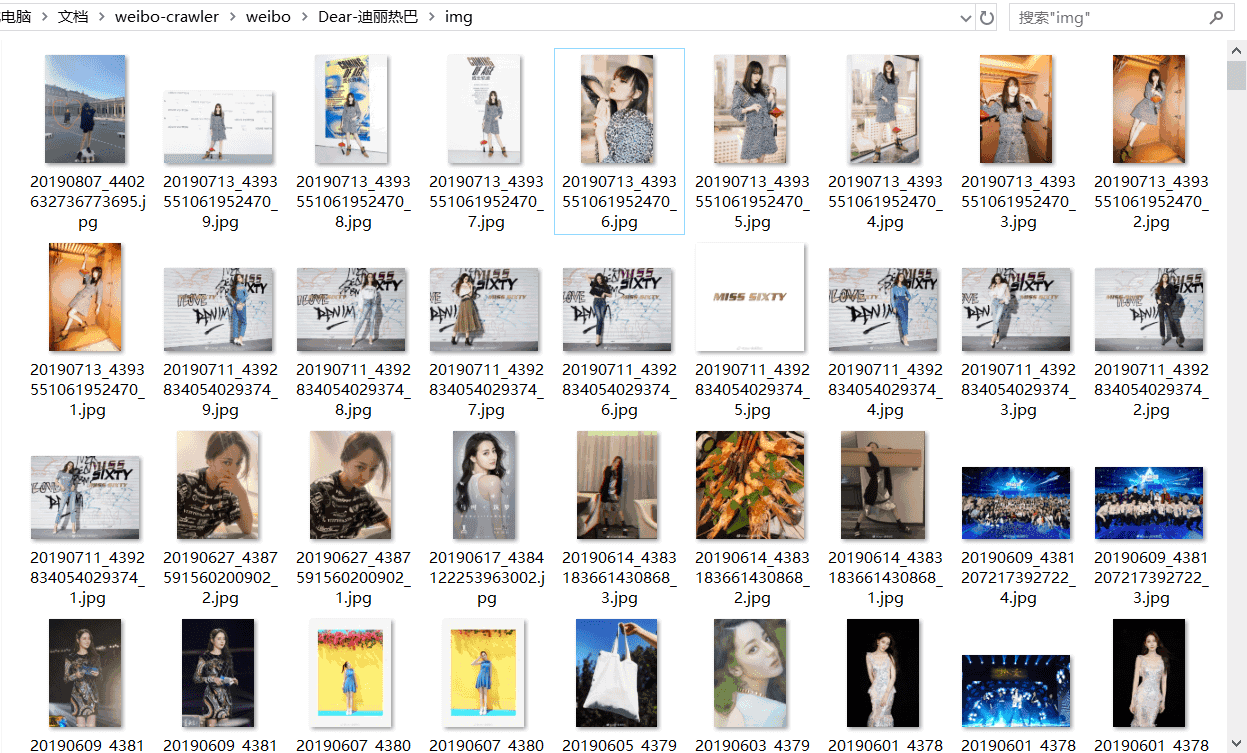
本次下载了788张图片,大小一共1.21GB,包括她原创微博中的所有图片。图片名为yyyymmdd+微博id的形式,若某条微博存在多张图片,则图片名中还会包括它在微博图片中的序号。若某图片下载失败,程序则会以“weibo_id:pic_url”的形式将出错微博id和图片url写入同文件夹下的not_downloaded.txt里;若图片全部下载成功则不会生成not_downloaded.txt;
下载的视频如下所示:
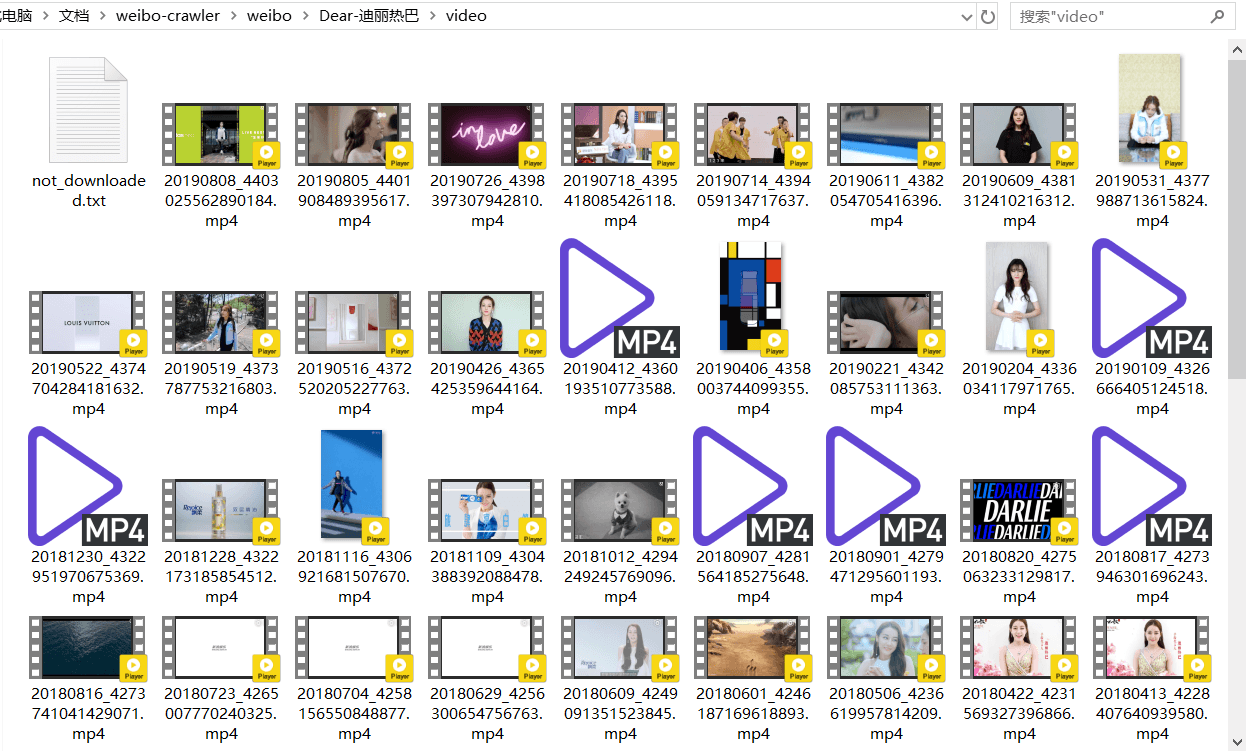
本次下载了66个视频,是她原创微博中的视频,视频名为yyyymmdd+微博id的形式。有三个视频因为网络原因下载失败,程序将它们的微博id和视频url分别以“weibo_id:video_url”的形式写到了同文件夹下的not_downloaded.txt里。
因为我本地没有安装MySQL数据库和MongoDB数据库,所以暂时设置成不写入数据库。如果你想要将爬取结果写入数据库,只需要先安装数据库(MySQL或MongoDB),再安装对应包(pymysql或pymongo),然后将mysql_write或mongodb_write值设置为1即可。写入MySQL需要用户名、密码等配置信息,这些配置如何设置见设置数据库部分。
- 开发语言:python2/python3
- 系统: Windows/Linux/macOS
$ git clone https://github.com/dataabc/weibo-crawler.git运行上述命令,将本项目下载到当前目录,如果下载成功当前目录会出现一个名为"weibo-crawler"的文件夹;
$ pip install -r requirements.txt打开weibo-crawler文件夹下的weibo.py文件,将我们想要爬取的一个或多个微博的user_id赋值给user_id_list,user_id获取方法见如何获取user_id。 user_id设置代码位于weibo.py的main函数里,具体代码如下:
# 爬单个微博,可以改成任意合法的用户id
user_id_list = ['1669879400']或者
# 爬多个微博,可以改成任意合法的用户id
user_id_list = ['1669879400', '1729370543']也可以读取文件中的用户id,每个user_id占一行,也可以在user_id后面加注释(可选),如用户昵称等信息,user_id和注释之间必需要有空格,文件名任意,类型为txt,位置位于本程序的同目录下,文件内容示例如下:
1223178222 胡歌
1669879400 迪丽热巴
1729370543 郭碧婷
假如文件叫user_id_list.txt,则user_id设置代码为:
user_id_list = wb.get_user_list('user_id_list.txt')本部分是可选部分,如果不需要将爬取信息写入数据库,可跳过这一步。本程序目前支持MySQL数据库和MongoDB数据库,如果你需要写入其它数据库,可以参考这两个数据库的写法自己编写。
MySQL数据库写入
要想将爬取信息写入MySQL,请将main函数中的mysql_write变量值改为1。再根据自己的系统环境安装MySQL,然后命令行执行:
$ pip install pymysqlMySQL写入需要主机、端口号、用户名、密码等配置,本程序默认的配置如下:
mysql_config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'charset': 'utf8mb4'
}如果你的配置和上面不同,需要修改main函数,将本程序的配置改成自己的配置,具体代码如下:
mysql_config = {
'host': 'xxx',
'port': xxx,
'user': 'xxx',
'password': 'xxx',
'charset': 'utf8mb4'
}
wb.change_mysql_config(mysql_config)MongoDB数据库写入
要想将爬取信息写入MongoDB,请将main函数中的mongodb_write变量值改为1。再根据自己的系统环境安装MongoDB,然后命令行执行:
$ pip install pymongo
MySQL和MongDB数据库的写入内容一样。程序首先会创建一个名为"weibo"的数据库,然后再创建"user"表和"weibo"表,包含爬取的所有内容。爬取到的微博用户信息或插入或更新,都会存储到user表里;爬取到的微博信息或插入或更新,都会存储到weibo表里,两个表通过user_id关联。如果想了解两个表的具体字段,请点击"详情"。
详情
user表
id:微博用户id,如"1669879400";
screen_name:微博用户昵称,如"Dear-迪丽热巴";
gender:微博用户性别,取值为f或m,分别代表女和男;
statuses_count:微博数;
followers_count:粉丝数;
follow_count:关注数;
description:微博简介;
profile_url:微博主页,如https://m.weibo.cn/u/1669879400?uid=1669879400&luicode=10000011&lfid=1005051669879400;
profile_image_url:微博头像url;
avatar_hd:微博高清头像url;
urank:微博等级;
mbrank:微博会员等级,普通用户会员等级为0;
verified:微博是否认证,取值为true和false;
verified_type:微博认证类型,没有认证值为-1,个人认证值为0,企业认证值为2,政府认证值为3,这些类型仅是个人猜测,应该不全,大家可以根据实际情况判断;
verified_reason:微博认证信息,只有认证用户拥有此属性。
weibo表
user_id:存储微博用户id,如"1669879400";
screen_name:存储微博昵称,如"Dear-迪丽热巴";
id:存储微博id;
text:存储微博正文;
pics:存储原创微博的原始图片url。若某条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为'';
video_url:存储原创微博的视频url。若某条微博没有视频,则值为'';
location:存储微博的发布位置。若某条微博没有位置信息,则值为'';
created_at:存储微博的发布时间;
source:存储微博的发布工具;
attitudes_count:存储微博获得的点赞数;
comments_count:存储微博获得的评论数;
reposts_count:存储微博获得的转发数;
topics:存储微博话题,即两个#中的内容。若某条微博没有话题信息,则值为'';
at_users:存储微博@的用户。若某条微博没有@的用户,则值为'';
retweet_id:存储转发微博中原始微博的微博id。若某条微博为原创微博,则值为''。
大家可以根据自己的运行环境选择运行方式,Linux可以通过
$ python weibo.py运行;
本脚本是一个Weibo类,用户可以按照自己的需求调用Weibo类。 用户可以直接在weibo.py文件中调用Weibo类,具体调用代码示例如下:
# 以下是程序配置信息,可以根据自己需求修改
filter = 1 # 值为0表示爬取全部微博(原创微博+转发微博),值为1表示只爬取原创微博
since_date = '2018-01-01' # 起始时间,即爬取发布日期从该值到现在的微博,形式为yyyy-mm-dd
"""mongodb_write值为0代表不将结果写入MongoDB数据库,1代表写入;若要写入MongoDB数据库,
请先安装MongoDB数据库和pymongo,pymongo安装方法为命令行运行:pip install pymongo"""
mongodb_write = 0
"""mysql_write值为0代表不将结果写入MySQL数据库,1代表写入;若要写入MySQL数据库,
请先安装MySQL数据库和pymysql,pymysql安装方法为命令行运行:pip install pymysql"""
mysql_write = 0
pic_download = 1 # 值为0代表不下载微博原始图片,1代表下载微博原始图片
video_download = 1 # 值为0代表不下载微博视频,1代表下载微博视频
wb = Weibo(filter, since_date, mongodb_write, mysql_write,
pic_download, video_download)
# 下面是自定义MySQL数据库连接配置(可选)
"""因为操作MySQL数据库需要用户名、密码等参数,本程序默认为:
mysql_config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': '123456',
'charset': 'utf8mb4'
}
大家的参数配置如果和默认值不同,可以将上面的参数值替换成自己的,
然后添加如下代码,使修改生效,如果你的参数和默认值相同则不需要下面的代码:
wb.change_mysql_config(mysql_config)"""
# 下面是配置user_id_list
"""user_id_list包含了要爬的目标微博id,可以是一个,也可以是多个,也可以从文件中读取
爬单个微博,user_id_list如下所示,可以改成任意合法的用户id
user_id_list = ['1669879400']
爬多个微博,user_id_list如下所示,可以改成任意合法的用户id
user_id_list = ['1669879400', '1729370543']
也可以在文件中读取user_id_list,文件中可以包含很多user_id,
每个user_id占一行,也可以在user_id后面加注释,如用户昵称,user_id和注释之间必需要有空格,
文件名任意,类型为txt,位置位于本程序的同目录下,文件内容可以为如下形式:
1223178222 胡歌
1669879400 迪丽热巴
1729370543 郭碧婷
比如文件可以叫user_id_list.txt,读取文件中的user_id_list如下所示:
user_id_list = wb.get_user_list('user_id_list.txt')"""
user_id_list = ['1669879400']
wb.start(user_id_list)通过执行wb.start() 完成了微博的爬取工作。在上述代码执行后,我们可以得到很多信息:
wb.user:存储目标微博用户信息;
wb.user包含爬取到的微博用户信息,如用户id、用户昵称、性别、微博数、粉丝数、关注数、简介、主页地址、头像url、高清头像url、微博等级、会员等级、是否认证、认证类型、认证信息等,大家可以点击"详情"查看具体用法。
详情
id:微博用户id,取值方式为wb.user['id'],由一串数字组成;
screen_name:微博用户昵称,取值方式为wb.user['screen_name'];
gender:微博用户性别,取值方式为wb.user['gender'],取值为f或m,分别代表女和男;
statuses_count:微博数,取值方式为wb.user['statuses_count'];
followers_count:微博粉丝数,取值方式为wb.user['followers_count'];
follow_count:微博关注数,取值方式为wb.user['follow_count'];
description:微博简介,取值方式为wb.user['description'];
profile_url:微博主页,取值方式为wb.user['profile_url'];
profile_image_url:微博头像url,取值方式为wb.user['profile_image_url'];
avatar_hd:微博高清头像url,取值方式为wb.user['avatar_hd'];
urank:微博等级,取值方式为wb.user['urank'];
mbrank:微博会员等级,取值方式为wb.user['mbrank'],普通用户会员等级为0;
verified:微博是否认证,取值方式为wb.user['verified'],取值为true和false;
verified_type:微博认证类型,取值方式为wb.user['verified_type'],没有认证值为-1,个人认证值为0,企业认证值为2,政府认证值为3,这些类型仅是个人猜测,应该不全,大家可以根据实际情况判断;
verified_reason:微博认证信息,取值方式为wb.user['verified_reason'],只有认证用户拥有此属性。
wb.weibo:存储爬取到的所有微博信息;
wb.weibo包含爬取到的所有微博信息,如微博id、正文、原始图片url、视频url、位置、日期、发布工具、点赞数、转发数、评论数、话题、@用户等。如果爬的是全部微博(原创+转发),除上述信息之外,还包含原始用户id、原始用户昵称、原始微博id、原始微博正文、原始微博原始图片url、原始微博位置、原始微博日期、原始微博工具、原始微博点赞数、原始微博评论数、原始微博转发数、原始微博话题、原始微博@用户等信息。wb.weibo是一个列表,包含了爬取的所有微博信息。wb.weibo[0]为爬取的第一条微博,wb.weibo[1]为爬取的第二条微博,以此类推。当filter=1时,wb.weibo[0]为爬取的第一条原创微博,以此类推。wb.weibo[0]['id']为第一条微博的id,wb.weibo[0]['text']为第一条微博的正文,wb.weibo[0]['created_at']为第一条微博的发布时间,还有其它很多信息不在赘述,大家可以点击下面的"详情"查看具体用法。
详情
user_id:存储微博用户id。如wb.weibo[0]['user_id']为最新一条微博的用户id;
screen_name:存储微博昵称。如wb.weibo[0]['screen_name']为最新一条微博的昵称;
id:存储微博id。如wb.weibo[0]['id']为最新一条微博的id;
text:存储微博正文。如wb.weibo[0]['text']为最新一条微博的正文;
pics:存储原创微博的原始图片url。如wb.weibo[0]['pics']为最新一条微博的原始图片url,若该条微博有多张图片,则存储多个url,以英文逗号分割;若该微博没有图片,则值为'';
video_url:存储原创微博的视频url。如wb.weibo[0]['video_url']为最新一条微博的视频url;若该微博没有视频,则值为'';
location:存储微博的发布位置。如wb.weibo[0]['location']为最新一条微博的发布位置,若该条微博没有位置信息,则值为'';
created_at:存储微博的发布时间。如wb.weibo[0]['created_at']为最新一条微博的发布时间;
source:存储微博的发布工具。如wb.weibo[0]['source']为最新一条微博的发布工具;
attitudes_count:存储微博获得的点赞数。如wb.weibo[0]['attitudes_count']为最新一条微博获得的点赞数;
comments_count:存储微博获得的评论数。如wb.weibo[0]['comments_count']为最新一条微博获得的评论数;
reposts_count:存储微博获得的转发数。如wb.weibo[0]['reposts_count']为最新一条微博获得的转发数;
topics:存储微博话题,即两个#中的内容。如wb.weibo[0]['topics']为最新一条微博的话题,若该条微博没有话题信息,则值为'';
at_users:存储微博@的用户。如wb.weibo[0]['at_users']为最新一条微博@的用户,若该条微博没有@的用户,则值为'';
retweet:存储转发微博中原始微博的全部信息。假如wb.weibo[0]为转发微博,则wb.weibo[0]['retweet']为该转发微博的原始微博,它存储的属性与wb.weibo[0]一样,只是没有retweet属性;若该条微博为原创微博,则wb[0]没有"retweet"属性,大家可以点击"详情"查看具体用法。
详情
假设爬取到的第i条微博为转发微博,则它存在以下信息:
user_id:存储原始微博用户id。wb.weibo[i-1]['retweet']['user_id']为该原始微博的用户id;
screen_name:存储原始微博昵称。wb.weibo[i-1]['retweet']['screen_name']为该原始微博的昵称;
id:存储原始微博id。wb.weibo[i-1]['retweet']['id']为该原始微博的id;
text:存储原始微博正文。wb.weibo[i-1]['retweet']['text']为该原始微博的正文;
pics:存储原始微博的原始图片url。wb.weibo[i-1]['retweet']['pics']为该原始微博的原始图片url,若该原始微博有多张图片,则存储多个url,以英文逗号分割;若该原始微博没有图片,则值为'';
video_url:存储原始微博的视频url。如wb.weibo[i-1]['retweet']['video_url']为该原始微博的视频url;若该微博没有视频,则值为'';
location:存储原始微博的发布位置。wb.weibo[i-1]['retweet']['location']为该原始微博的发布位置,若该原始微博没有位置信息,则值为'';
created_at:存储原始微博的发布时间。wb.weibo[i-1]['retweet']['created_at']为该原始微博的发布时间;
source:存储原始微博的发布工具。wb.weibo[i-1]['retweet']['source']为该原始微博的发布工具;
attitudes_count:存储原始微博获得的点赞数。wb.weibo[i-1]['retweet']['attitudes_count']为该原始微博获得的点赞数;
comments_count:存储原始微博获得的评论数。wb.weibo[i-1]['retweet']['comments_count']为该原始微博获得的评论数;
reposts_count:存储原始微博获得的转发数。wb.weibo[i-1]['retweet']['reposts_count']为该原始微博获得的转发数;
topics:存储原始微博话题,即两个#中的内容。wb.weibo[i-1]['retweet']['topics']为该原始微博的话题,若该原始微博没有话题信息,则值为'';
at_users:存储原始微博@的用户。wb.weibo[i-1]['retweet']['at_users']为该原始微博@的用户,若该原始微博没有@的用户,则值为''。
1.打开网址https://weibo.cn,搜索我们要找的人,如"迪丽热巴",进入她的主页;
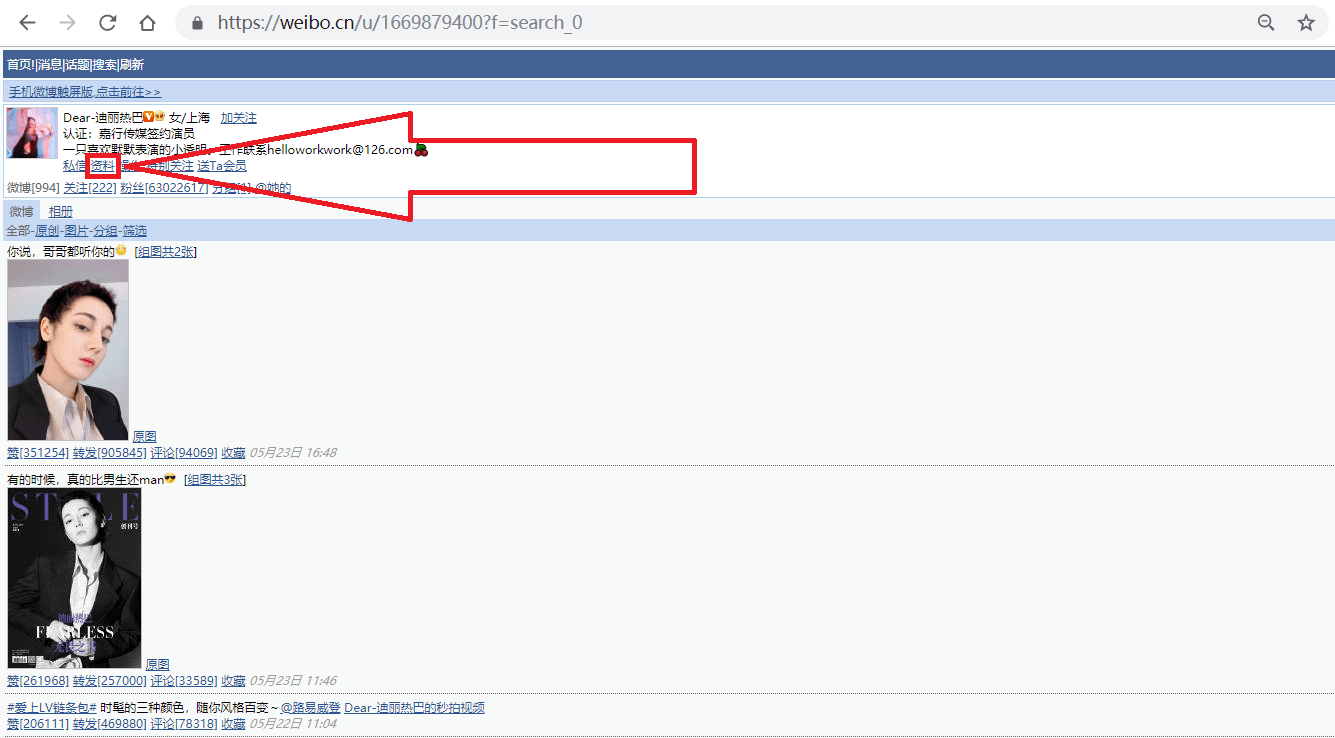
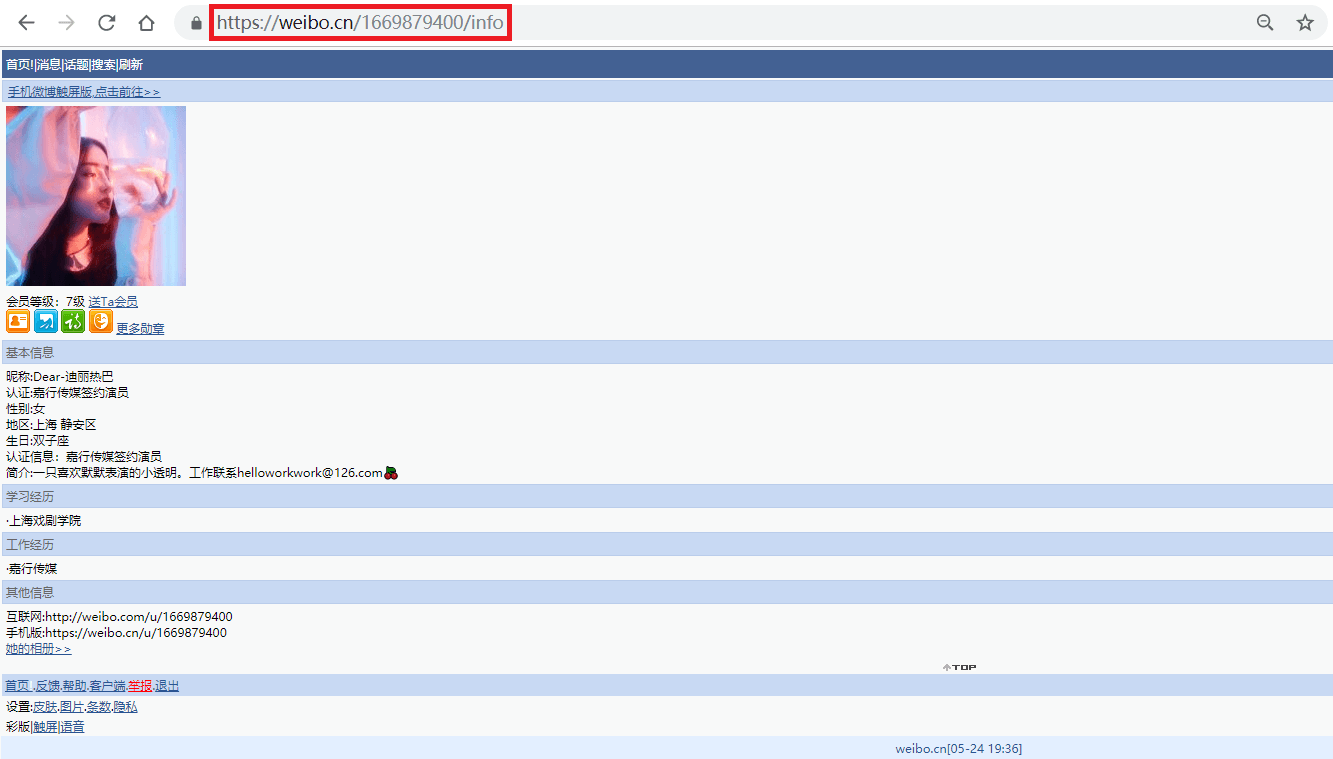
事实上,此微博的user_id也包含在用户主页(https://weibo.cn/u/1669879400?f=search_0)中,之所以我们还要点击主页中的"资料"来获取user_id,是因为很多用户的主页不是"https://weibo.cn/user_id?f=search_0"的形式,而是"https://weibo.cn/个性域名?f=search_0"或"https://weibo.cn/微号?f=search_0"的形式。其中"微号"和user_id都是一串数字,如果仅仅通过主页地址提取user_id,很容易将"微号"误认为user_id。