A rewrite of the Ranger deep learning optimizer to integrate newer optimization ideas and, in particular:
- uses the AdamW optimizer as its core (or, optionally, MadGrad)
- Adaptive gradient clipping
- Gradient centralization
- Positive-Negative momentum
- Norm loss
- Stable weight decay
- Linear learning rate warm-up
- Explore-exploit learning rate schedule
- Lookahead
- Softplus transformation
- Gradient Normalization
You can find a full description of most of our algorithm in the Ranger21 paper (only Softplus and Gradient Normalization were added after the paper). Researchers and library authors desiring to port the code might also be interested in the Flax implementation which was written with a focus on readability.
Until this is up on PyPi, this can either be installed via cloning the package:
git clone https://github.com/lessw2020/Ranger21.git
cd Ranger21
python -m pip install -e .
or directly installed from github:
python -m pip install git+https://github.com/lessw2020/Ranger21.git
Ranger, with Radam + Lookahead core, is now approaching two years old.
*Original publication, Aug 2019: New deep learning optimizer Ranger
In the interim, a number of new developments have happened including the rise of Transformers for Vision.
Thus, Ranger21 (as in 2021) is a rewrite with multiple new additions reflective of some of the most impressive papers this past year. The focus for Ranger21 is that these internals will be parameterized, and where possible, automated, so that you can easily test and leverage some of the newest concepts in AI training, to optimize the optimizer on your respective dataset.
Full Run on ImageNet in progress - results so far (going to 60 epochs, Ranger21 started later):
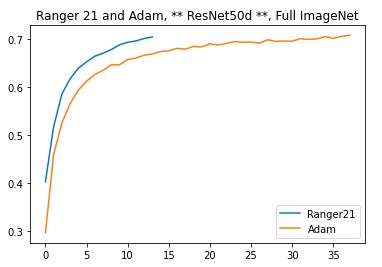
Ranger 21 (7/10/21 version) :
Accuracy: 76.63% Validation Loss: 14.42
Adam:
Accuracy: 64.84% Validation Loss: 17.19
Net results: 18.18% greater accuracy with Ranger21 vs Adam, same training epochs.
July 10: 3 new improvements to Ranger21 Three new items have been added to Ranger21 after testing on sub ImageNet benchmark:
- Gradient Normalization - this continues the Gradient centralization concept by normalizing the gradient (vs. gradient centralization subtracts the mean). On ImageNet it produces faster convergence in the first 20 or so epochs.
- Softplus transform - by running the final variance denom through the softplus function, it lifts extremely small values to keep them viable. This helps with refining the training updates and in testing on our sub ImageNet benchmark, it set a new high in accuracy and val loss. (usage: softplus = True is default, set to False at init to turn off). Please see https://arxiv.org/abs/1908.00700 for the original paper.
- Adaptive clipping now supports unlimited dimensions - some users were hitting issues running with 3D or 4D convolutions. Ranger21 now handles dimensions of any size with this update.
June 25: Arxiv paper nearly ready, back to work on Ranger21 after that! Paper is in review and should be published on Arxiv next week. Once that is done, will get back to working on Ranger21 - including working on the tutorial notebook.
May 16 - ImageNet training finished, finishing paper, updated Ranger21 with 1 off iteration fix and new show_schedule() feature:
- ImageNet runs have finished and hope to have arxiv paper ready in next week or so.
- Big thanks to @zsgj-Xxx for finding that the warmup ends up with the lr being 1 iteration short. Have updated with fix.
- In order to make it easier to see the lr schedule, have added a new show_schedule() that will show a pyplot image directly, along with the start/max/min values for the schedule. This info was already there via the tracking_lr list, but you'd have to pull the data and then manually plot. Now it's even easier to train, and then make a single line call:
optimizer.show_schedule()
to quickly view the full schedule, and key values.

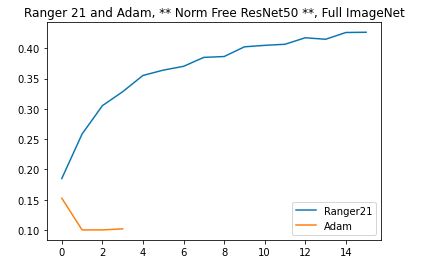
May 1 PM - Multiple ImageNet runs in progress, updated Ranger code checked in Have multiple ImageNet runs in progress to prep for a paper for Ranger21. The Base comparison is simply Adam on ImageNet and Ranger21 on ImageNet, with a ResNet50. Ranger21 started later but has already matched Adam with half the epochs...plan is to run to 60 epochs each.

In addition, training a BN Free (no batch norm) ResNet50 as an additional comparison. Of interest, even after 4 restarts, Adam was unable to get more than 3 epochs in on the NormFree Resnet50. By comparison, Ranger21 is doing well so this already shows the improved resilience of training with Ranger21.
- Ranger21 code updates - due to firsthand experience, have added in safety guards in the event that num_epochs set for Ranger21 does not match the actual epochs being run, as well as updated the linear warmdown code to be simpler and never go below the min_lr designated (defaults to 3e-5).
If there is an epoch mis-match between num_epochs passed to optimizer and the atual run, this will start to spew a lot of text to alert you on each iteration, but the lr itself will now be automatically guarded and not go below the min_lr.

April 27 PM - Ranger21 now training on ImageNet! Starting work on benchmarking Ranger21 on ImageNet. Due to cost, will train to 60 epochs on ImageNet and compare with same setup with 60 epochs using Adam to have a basic "gold standard" comparison. Training is underway now.
April 26 PM - added smarter auto warmup based on Dickson Neoh report (tested with only 5 epochs), and first pip install setup thanks to @BrianPugh!
The warmup structure for Ranger21 is based on the paper by Ma/Yarats which uses the beta2 param to compute the default warmup. However, that also assumes we have a longer training run. @DNH on the fastai forums tested with 5 epochs which meant it never got past warmup phase.
Thus have added a check for the % warmup relative to the total training time and will auto fall back to 30% (settable via warmup_pct_default) in order to account for shorter training runs.
- First pip install for Ranger21, thanks to @BrianPugh! In the next week or two will be focusing on making Ranger21 easier to install and use vs adding new optimizer features and thanks to @BrianPugh we've already underway with a basic pip install.
git clone https://github.com/lessw2020/Ranger21.git
cd Ranger21
python -m pip install -e .
```
or directly installed from github:
```
python -m pip install git+https://github.com/lessw2020/Ranger21.git
April 25 PM - added guard for potential key error issue Update checked in to add additional guard to prevent a key error reported earlier today during lookahead step. This should correct, but since unable to repro locally, please update to latest code and raise an issue if you encounter this. Thanks!
April 25 - Fixed warmdown calculation error, moved to Linear warmdown, new high in benchmark: Found that there was an error in the warmdown calculations. Fixed and also moved to linear warmdown. This resulted in another new high for the simple benchmark, with results now moved to above so they don't get lost in the updates section.
Note that the warmdown now calculates based on the decay between the full lr, to the minimal lr (defaults to 3e-5), rather than previously declining to 0.
Note that you can display the lr curves directly by simply using:
lr_curve = optimizer.tracking_lr
plt.plot(lr_curve)
Ranger21 internally tracks the lr per epoch for this type of review.
Additional updates include adding a 'clear_cache' to reset the cached lookahead params, and also moved the lookahead procesing to it's own function and cleaned up some naming conventions. Will use item_active=True/False rather than the prior using_item=True/False to keep the code simpler as now item properties are alpha grouped vs being cluttered into the using_item layout.
April 24 - New record on benchmark with NormLoss, Lookahead, PosNeg momo, Stable decay etc. all combined NormLoss and Lookahead integrated into Ranger21 set a new high on our simple benchmark (ResNet 18, subset of ImageWoof).
Best Accuracy = 73.41 Best Val Loss = 15.06
For comparison, using plain Adam on this benchmark:
Adam Only Accuracy = 64.84 Best Adam Val Loss = 17.19
In otherwords, 12.5%+ higher accuracy atm for same training epochs by using Ranger21 vs Adam.
Basically it shows that the integration of all these various new techniques is paying off, as currently combining them delivers better than any of them + Adam.
New code checked in - adds Lookahead and of course Norm Loss. Also the settings is now callable via .show_settings() as an easy way to check settings.
Given that the extensive settings may become overwhelming, planning to create config file support to make it easy to save out settings for various architectures and ideally have a 'best settings' recipe for CNN, Transformer for Image/Video, GAN, etc.
April 23 - Norm Loss will be added, initial benchmarking in progress for several features A new soft regularizer, norm loss, was recently published in this paper on Arxiv: https://arxiv.org/abs/2103.06583v1
It's in the spirit of weight decay, but approaches it in a unique manner by nudging the weights towards the oblique manifold..this means unlike weight decay, it can actually push smaller weights up towards the norm 1 property vs weight decay only pushes down. Their paper also shows norm less is less sensitive to hyperparams such as batch size, etc. unlike regular weight decay.
One of the lead authors was kind enough to share their TF implemention, and have reworked it into PyTorch form and integrated into Ranger21. Initial testing set a new high for validation loss on my very basic benchmark. Thus, norm loss will be available with the next code update.
Also did some initial benchmarking to set vanilla Adam as a baseline, and ablation style testing with pos negative momentum. Pos neg momo alone is a big improvement over vanilla Adam, and looking forward to mapping out the contributions and synergies between all of the new features being rolled into Ranger21 including norm loss, adapt gradient clipping, gc, etc.
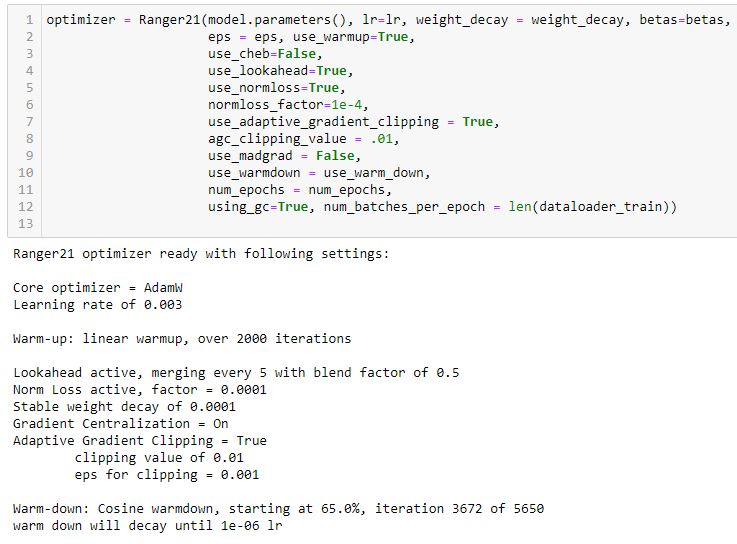
April 18 PM - Adaptive gradient clipping added, thanks for suggestion and code from @kayuksel. AGC is used in NFNets to replace BN. For our use case here, it's to have a smarter gradient clipping algo vs the usual hard clipping, and ideally better stabilize training.
Here's how the Ranger21 settings output looks atm:

April 18 AM - chebyshev fractals added, cosine warmdown (cosine decay) added
Chebyshev performed reasonably well, but still needs more work before recommending so it's defaulting to off atm.
There are two papers providing support for using Chebyshev, one of which is:
https://arxiv.org/abs/2010.13335v1
Cosine warmdown has been added so that the default lr schedule for Ranger21 is linear warmup, flat run at provided lr, and then cosine decay of lr starting at the X% passed in. (Default is .65).
April 17 - building benchmark dataset(s) As a cost effective way of testing Ranger21 and it's various options, currently taking a subset of ImageNet categories and building out at the high level an "ImageSubNet50" and also a few sub category datasets. These are similar in spirit to ImageNette and ImageWoof, but hope to make a few relative improvements including pre-sizing to 224x224 for speed of training/testing.
First sub-dataset in progress in ImageBirds, which includes:
n01614925 bald eagle
n01616318 vulture
n01622779 grey owl
n01806143 peacock
n01833805 hummingbird
This is a medium-fine classification problem and will use as first tests for this type of benchmarking. Ideally, will make a seperate repo for the ImageBirds shortly to make it available for people to use though hosting the dataset poses a cost problem...
April 12 - positive negative momentum added, madgrad core checked in Testing over the weekend showed that positive negative momentum works really well, and even better with GC.
Code is a bit messy atm b/c also tested Adaiw, but did not do that well so removed and added pos negative momentum.
Pos Neg momentum is a new technique to add parameter based, anisotropic noise to the gradient which helps it settle into flatter minima and also escape saddle points.
In other words, better results.
Link to their excellent paper:
https://arxiv.org/abs/2103.17182
You can toggle between madgrad or not with the use_madgrad = True/False flag:
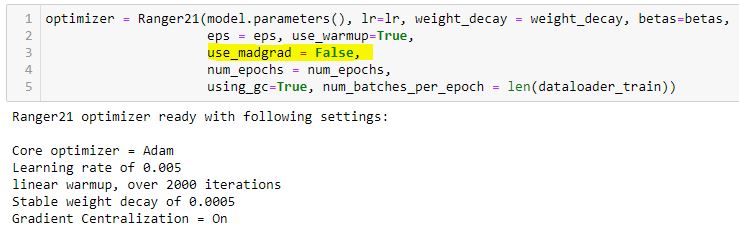
April 10 - madgrad core engine integrated Madgrad has been added in a way that you will be able to select to use MadGrad or Adam as the core 'engine' for the optimizer.
Thus, you'll be able to simply toggle which opt engine to use, as well as the various enhancements (warmup, stable weight decay, gradient_centralization) and thus quickly find the best optimization setup for your specific dataset.
Still testing things and then will update code here... Gradient centralization good for both - first findings are gradient centralization definitely improves MadGrad (just like it does with Adam core) so will have GC on as default for both engines.

One item - the starting lr for madgrad is very different (typically higher) than with Adam....have done some testing with automated LR scheduling (HyperExplorer and ABEL), but that will be added later if it's successful. But if you simply plug your usual Adam LR's into Madgrad you won't be impressed :)
Note that AdamP projection was also tested as an option, but impact was minimal, so will not be adding it atm.
April 6 - Ranger21 alpha ready - automatic warmup added. Seeing impressive results with only 3 features implemented.
Stable weight decay + GC + automated linear warmup seem to sync very nicely.
Thus if you are feeling adventorous, Ranger21 is basically alpha usable. Recommend you use the default warmup (automatic by default), but test lr and weight decay.
Ranger21 will output the settings at init to make it clear what you are running with:
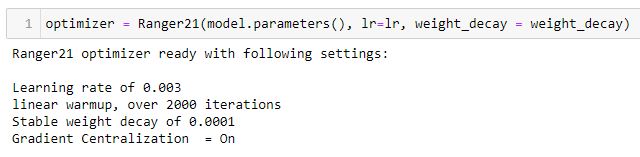
April 5 - stable weight decay added. Quick testing shows nice results with 1e-4 weight decay on subset of ImageNet.
Current feature set planned:
1 - feature complete - automated, Linear and Exponential warmup in place of RAdam. This is based on the findings of https://arxiv.org/abs/1910.04209v3
2 - Feature in progress - MadGrad core engine . This is based on my own testing with Vision Transformers as well as the compelling MadGrad paper: https://arxiv.org/abs/2101.11075v1
3 - feature complete - Stable Weight Decay instead of AdamW style or Adam style: needs more testing but the paper is very compelling: https://arxiv.org/abs/2011.11152v3
4 - feature complete - Gradient Centralization will be continued - as always, you can turn it on or off. https://arxiv.org/abs/2004.01461v2
5 - Lookahead may be brought forward - unclear how much it may help with the new MadGrad core, which already leverages dual averaging, but will probably include as a testable param.
6 - Feature implementation in progress - dual optimization engines - Will have Adam and Madgrad core present as well so that one could quickly test with both Madgrad and Adam (or AdamP) with the flip of a param.
If you have ideas/feedback, feel free to open an issue.
You can use the following BibTex to cite the Ranger21 paper in your research:
@article{wright2021ranger21,
title={Ranger21: a synergistic deep learning optimizer},
author={Wright, Less and Demeure, Nestor},
year={2021},
journal={arXiv preprint arXiv:2106.13731},
}