从开发层改造mysql性能,提升中文全文检索速度的实战(附性能对比结果)
[本文github更新地址] tag: mysql中文全文检索实战与性能对比
〇、业务需求与解决方案:
- 从开发层改造mysql性能,提升中文全文检索速度的实战
- PoC对此问题进行实际的论证实验工作;
一、性能对比结论:
- 先说结论,mysql80使用中文全文检索方式查询,相比select Like%语句,可以快几倍甚至百倍,也可以慢几倍;
- 其查询速度完全取决于查询场景是否符合全文检索最佳实践,本次实战的对比结果如下:
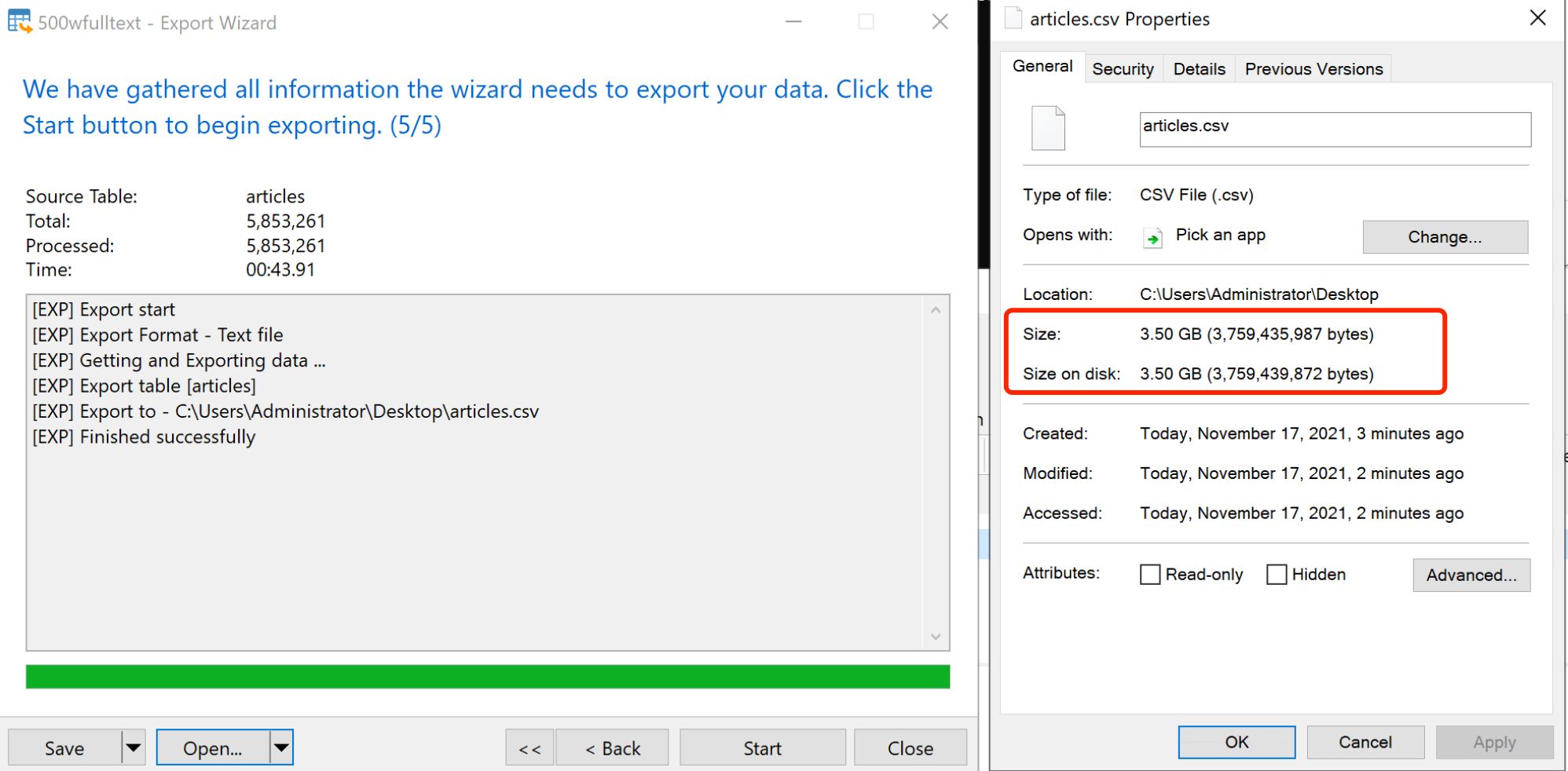
- 在超过500万(csv容量3.5GB)行记录的中文内容字段下测试出此结论,详情如下:
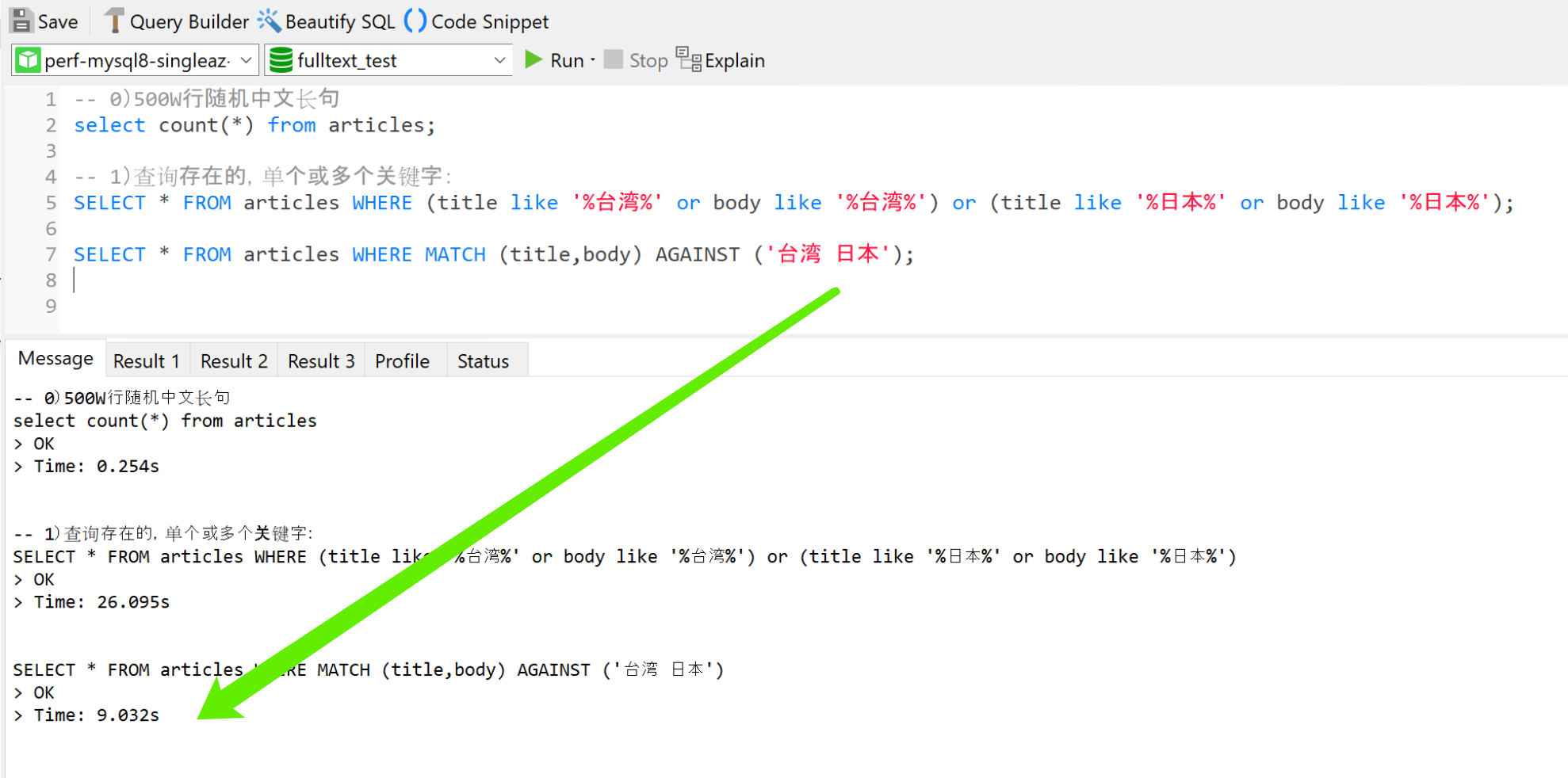
1)查询存在的,单个或多个关键字:
使用“mysql全文检索方式”速度比“select Like%语句” 快 10-n倍,n取决于查询关键字的个数。如图:
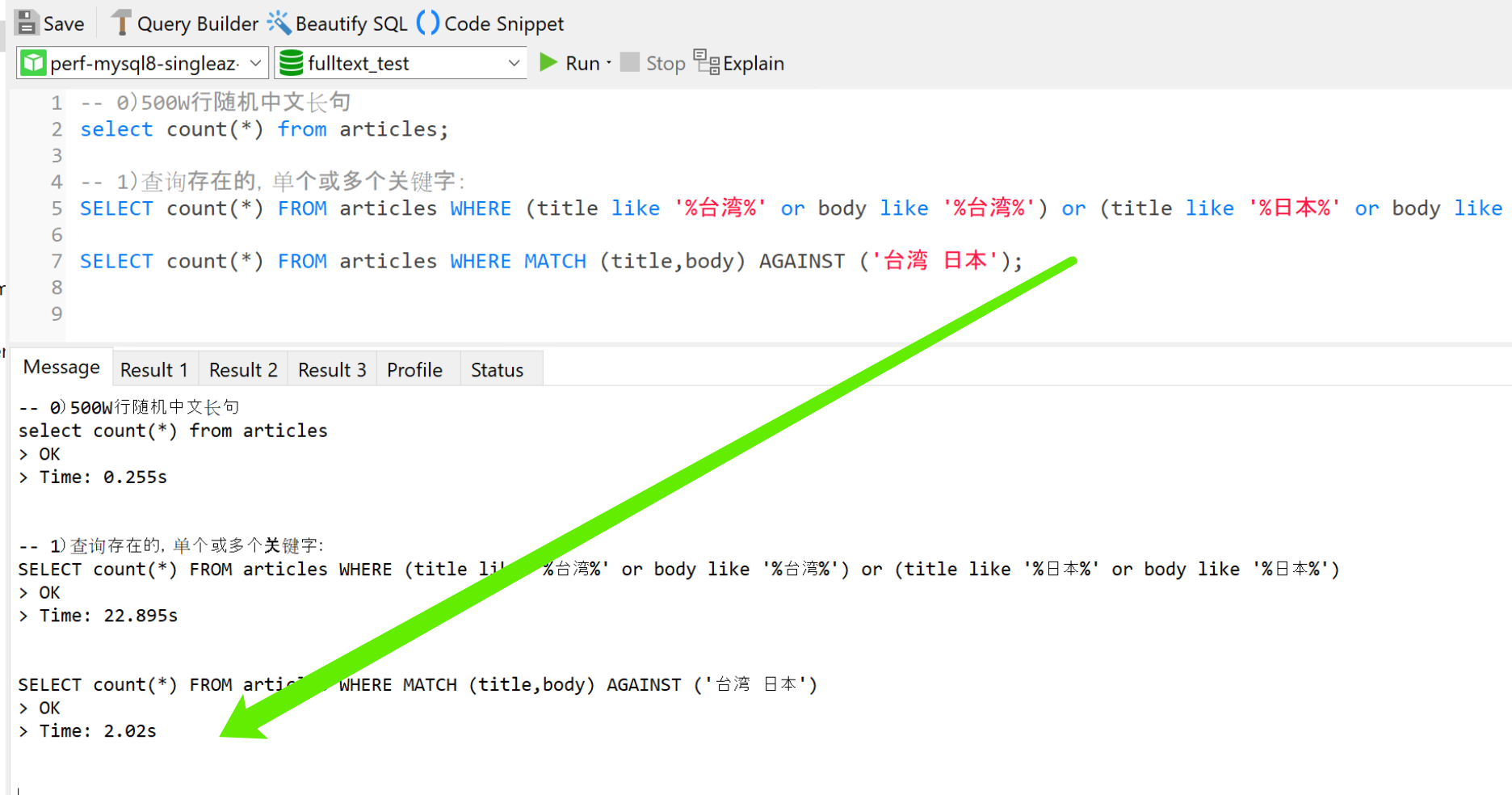
*求count是因为select load 100W行数据耗费大量时间,无法充分体现两者差距;
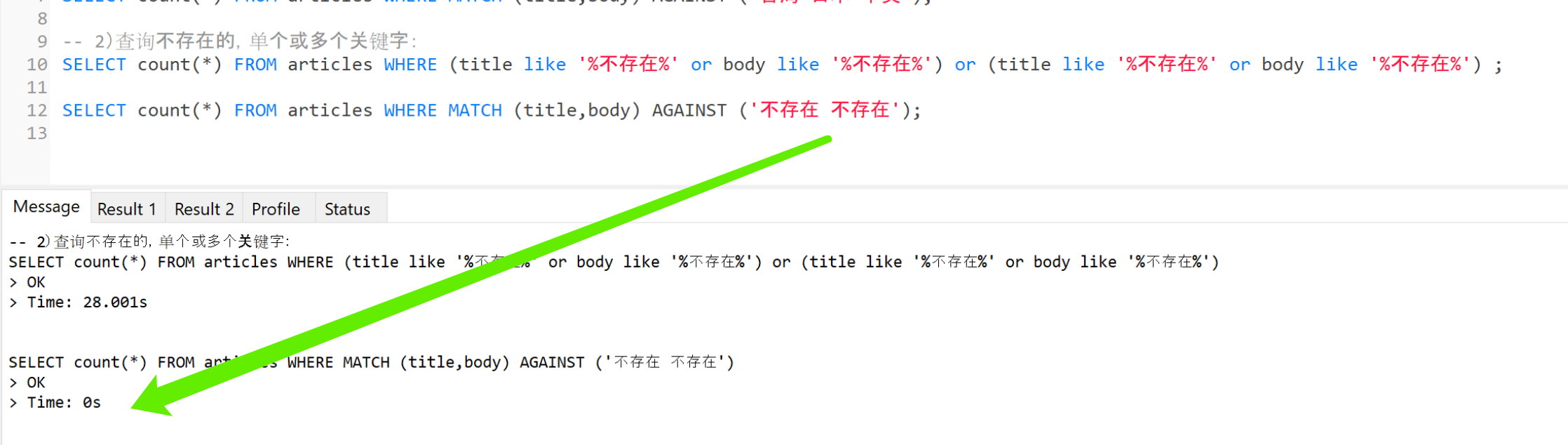
2)查询不存在的,单个或多个关键字:
使用“mysql全文检索方式”速度比“select Like%语句” 快 n倍,n接近于大无穷;如图:
3)查询长句:
使用“mysql全文检索方式”速度比“select Like%语句” 慢 n 倍。 句子越长查询速度越慢,如图:
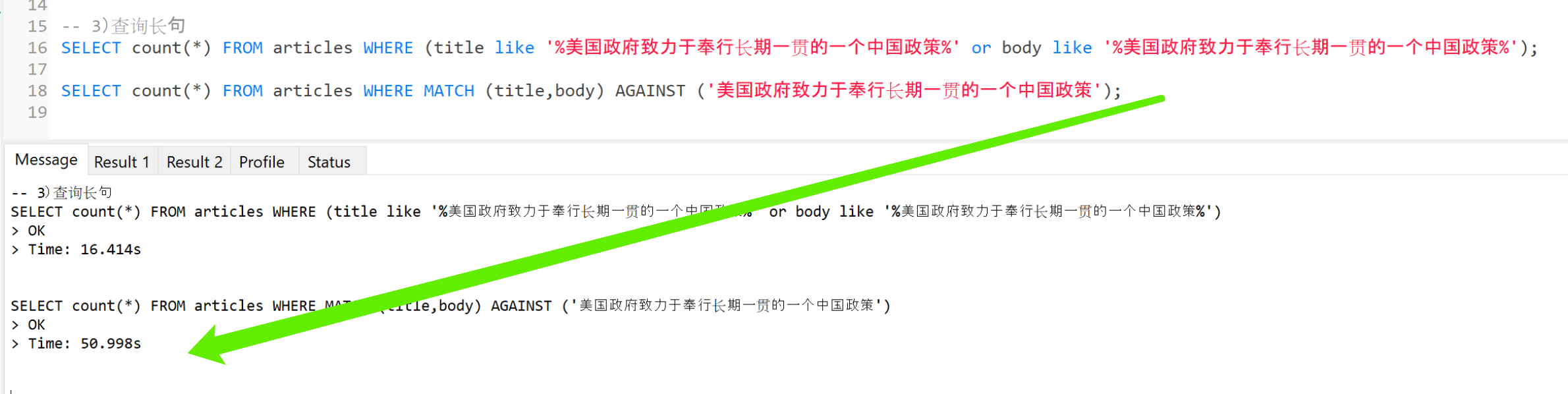
*长句查询不符合最佳实践,不推荐使用;
4)环境说明:
mysql80,配置 32c/128g/500GB,单表3列简单schema,一个自增字段+两个VARCHAR/TEXT字段,500W(csv容量3.5GB)行随机中文长句;
AWS硬件配置说明:
| NO | 类型 | AWS型号 | 配置 | 容量 | 版本或操作系统 | 端口及访问 | |
|---|---|---|---|---|---|---|---|
| 1 | 数据库 | AWS RDS db.m6g.8xlarge | 32c/128g | 500GB SSD | Mysql 8.0.26 | 采用私有子网部署,公网无法直接访问;可通过服务器内网访问 · 端口开放:3306(仅供内网) | |
| 2 | 服务器1 | AWS EC2 m5.xlarge | 4c/16g | 500GB SSD | Microsoft Windows Server 2019 | 可以通过公网RDP访问;可以连通RDS数据库3306端口; · 端口开放:RDP端口3389;端口开放:80,443 |
表结构: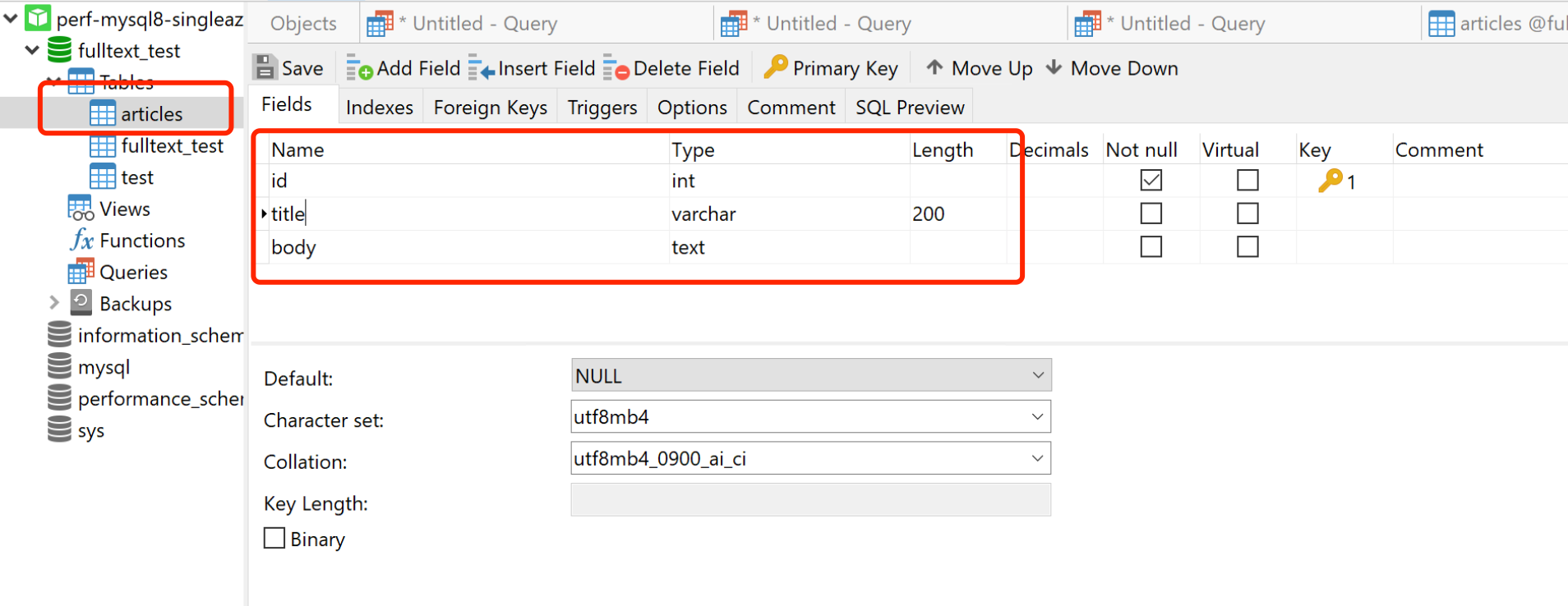
导出csv后的容量:
二、mysql中文全文检索实战步骤
1、环境搭建
1)创建表结构
-- 创建表的同时创建全文索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR (200),
body TEXT,
FULLTEXT (title, body) WITH PARSER ngram
) ENGINE = INNODB;
-- 通过 alter table 的方式来添加索引
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;2)创建500W行中文测试数据中文(大约需要100分钟)
DROP PROCEDURE IF EXISTS proc_initData;--若是存在此存储过程则删掉
DELIMITER $
CREATE PROCEDURE proc_initData()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<=999999 DO
insert into articles (title, body) values (' 在**共产党成立一百周年的重要历史时刻,在党和人民胜利实现第一个百年奋斗目标、全面建成小康社会,正在向着全面建成社会主义现代化强国的第二个百年奋斗目标迈进的重大历史关头,党的十九届六中全会于2021年11月8日至11日在北京胜利召开,审议通过了《****关于党的百年奋斗重大成就和历史经验的决议》。全会聚焦总结党的百年奋斗重大成就和历史经验,突出**特色社会主义新时代这个重点,强调“党的百年奋斗展示了马克思主义的强大生命力,马克思主义的科学性和真理性在**得到充分检验,马克思主义的人民性和实践性在**得到充分贯彻,马克思主义的开放性和时代性在**得到充分彰显”,“全党必须坚持马克思列宁主义、*****、***理论、‘三个代表’重要**、科学发展观,全面贯彻***新时代**特色社会主义**,用马克思主义的立场、观点、方法观察时代、把握时代、引领时代,不断深化对共产党执政规律、社会主义建设规律、人类社会发展规律的认识”。','**建党,理论强党,理论武装是最强大的武装。党的十八大以来,在团结带领全党全国各族人民开辟马克思主义**化新境界、创造新时代**特色社会主义伟大成就的非凡历程中,***总书记发表一系列重要讲话、作出一系列重大部署,从根本上阐明了坚持用马克思主义及其**化创新理论武装全党的重大意义、方向原则、方式方法、目标任务等问题。《坚持用马克思主义及其**化创新理论武装全党》一文,是***总书记2012年11月至2021年7月期间讲话、信函中有关内容的节录,深刻阐述了马克思主义作为我们立党立国根本指导**的重大意义,系统总结了我们党创造性推进马克思主义**化的壮阔历程和丰硕成果,对用马克思主义**化最新成果武装头脑、指导实践、推动工作作出战略部署,内涵丰富、**深刻,具有很强的现实性、指导性。');
insert into articles (title, body) values ('联播视频丨***同美国总统拜登举行视频会晤','北京时间16日上午8点46分,华盛顿时间15日晚上19点46分,一场遥隔万里的视频会晤开始。一开场,两位领导人互相招手,微笑致意。');
insert into articles (title, body) values ('***主席:“总统先生,你好。今天是我们第一次以视频方式会晤,看到老朋友我感到很高兴。”','拜登总统:“我很高兴能找到时间同您会晤。希望我们的对话能够坦诚直率,像过去一样。”一声“老朋友”,胸怀坦荡。“像过去一样”,意味悠长。');
insert into articles (title, body) values ('上周六,一个重要消息正式“官宣”:经中美双方商定,中美两国元首将于北京时间11月16日举行视频会晤。','在这场举世瞩目的视频会晤中,两国领导人将关注哪些重要议题?会晤能否取得两国和世界人民所期待的成果?释放了哪些重要信号?《时政新闻眼》全程关注会晤进程,为您解析。');
insert into articles (title, body) values ('10年前,时任美国副总统拜登应时任**国家副主席***的邀请访华,6天行程,***一路陪同。次年,拜登邀请***回访,访美期间,拜登陪同***参加11场活动。','9年前那次访美时,***曾表示,**问题事关**主权和领土完整,始终是中美关系中最核心、最敏感的问题。在今年这次视频会晤中,习主席郑重阐述了中方在**问题上的原则立场。他指出,一个**原则和中美三个联合公报是中美关系的政治基础。历届美国政府对此都有明确承诺。**问题的真正现状和一个**的核心内容是:世界上只有一个**,**是**的一部分,中华人民共和国政府是代表**的唯一合法政府。拜登表示,美国政府致力于奉行长期一贯的一个**政策,不支持“台独”,希望台海地区保持和平稳定。');
SET i = i+1;
END WHILE;
END $
CALL proc_initData();二、参数配置
中文全文检索有2个关键参数,分别为:
show variables like '%ngram%';
show variables like '%ft_min_word_len%';建议保留缺省值;如下需要单个汉字查询,需要设置参数为:
ngram_token_size=1
ft_min_word_len = 1
三、查询语句
-- 0)500W行随机中文长句
select count(*) from articles;
-- 1)查询存在的,单个或多个关键字:
SELECT count(*) FROM articles WHERE (title like '%**%' or body like '%**%') or (title like '%日本%' or body like '%日本%') or (title like '%中美%' or body like '%中美%');
SELECT count(*) FROM articles WHERE MATCH (title,body) AGAINST ('** 日本 中美');
-- 2)查询不存在的,单个或多个关键字:
SELECT count(*) FROM articles WHERE (title like '%不存在%' or body like '%不存在%') or (title like '%不存在%' or body like '%不存在%') ;
SELECT count(*) FROM articles WHERE MATCH (title,body) AGAINST ('不存在 不存在');
-- 3)查询长句
SELECT count(*) FROM articles WHERE (title like '%美国政府致力于奉行长期一贯的一个**政策%' or body like '%美国政府致力于奉行长期一贯的一个**政策%');
SELECT count(*) FROM articles WHERE MATCH (title,body) AGAINST ('美国政府致力于奉行长期一贯的一个**政策');
四、查询结果
三、mysql中文全文检索实战步骤背景介绍
1)概念说明
你可能会说,用 like + % 就可以实现模糊匹配了,为什么还要全文索引?like + % 在文本比较少时是合适的,但是对于大量的文本数据检索,是不可想象的。全文索引在大量的数据面前,能比 like + % 快 N 倍,速度不是一个数量级,但是全文索引可能存在精度问题。
你可能没有注意过全文索引,不过至少应该对一种全文索引技术比较熟悉:各种的搜索引擎。虽然搜索引擎的索引对象是超大量的数据,并且通常其背后都不是关系型数据库,不过全文索引的基本原理是一样的。
2)版本支持(本次实战使用mysql80)
开始之前,先说一下全文索引的版本、存储引擎、数据类型的支持情况
- MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引;
- MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
- 只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
测试或使用全文索引时,要先看一下自己的 MySQL 版本、存储引擎和数据类型是否支持全文索引。
3)英文的全文检索说明
创建
1.创建表时创建全文索引
create table fulltext_test (
id int(11) NOT NULL AUTO_INCREMENT,
content text NOT NULL,
tag varchar(255),
PRIMARY KEY (id),
FULLTEXT KEY content_tag_fulltext(content,tag) -- 创建联合全文索引列
) ENGINE=MyISAM DEFAULT CHARSET=utf8;2.在已存在的表上创建全文索引
create fulltext index content_tag_fulltext
on fulltext_test(content,tag);3.通过 SQL 语句 ALTER TABLE 创建全文索引
alter table fulltext_test
add fulltext index content_tag_fulltext(content,tag);删除
1.直接使用 DROP INDEX 删除全文索引
drop index content_tag_fulltext
on fulltext_test;2.通过 SQL 语句 ALTER TABLE 删除全文索引
alter table fulltext_test
drop index content_tag_fulltext;使用全文索引
和常用的模糊匹配使用 like + % 不同,全文索引有自己的语法格式,使用 match 和 against 关键字,比如
select * from fulltext_test
where match(content,tag) against('xxx xxx');注意: match() 函数中指定的列必须和全文索引中指定的列完全相同,否则就会报错,无法使用全文索引,这是因为全文索引不会记录关键字来自哪一列。如果想要对某一列使用全文索引,请单独为该列创建全文索引。
添加测试数据
有了上面的知识,就可以测试一下全文索引了。首先创建测试表,插入测试数据
create table test (
id int(11) unsigned not null auto_increment,
content text not null,
primary key(id),
fulltext key content_index(content)
) engine=MyISAM default charset=utf8;
insert into test (content) values ('a'),('b'),('c');
insert into test (content) values ('aa'),('bb'),('cc');
insert into test (content) values ('aaa'),('bbb'),('ccc');
insert into test (content) values ('aaaa'),('bbbb'),('cccc');按照全文索引的使用语法执行下面查询
select * from test where match(content) against('aaaa');常见问题:最小搜索长度
最常见的就是 最小搜索长度 导致的。另外插一句,使用全文索引时,测试表里至少要有 4 条以上的记录,否则,会出现意想不到的结果。MySQL 中的全文索引,有两个变量,最小搜索长度和最大搜索长度,对于长度小于最小搜索长度和大于最大搜索长度的词语,都不会被索引。通俗点就是说,想对一个词语使用全文索引搜索,那么这个词语的长度必须在以上两个变量的区间内。这两个的默认值可以使用以下命令查看
show variables like '%ft%';可以看到这两个变量在 MyISAM 和 InnoDB 两种存储引擎下的变量名和默认值
-- MyISAM
ft_min_word_len = 4;
ft_max_word_len = 84;
-- InnoDB
innodb_ft_min_token_size = 3;
innodb_ft_max_token_size = 84;可以看到最小搜索长度 MyISAM 引擎下默认是 4,InnoDB 引擎下是 3,也即,MySQL 的全文索引只会对长度大于等于 4 或者 3 的词语建立索引,而刚刚搜索的只有 aaaa 的长度大于等于 4。
修改最小搜索长度
全文索引的相关参数都无法进行动态修改,必须通过修改 MySQL 的配置文件来完成。修改最小搜索长度的值为 1,首先打开 MySQL 的配置文件 /etc/my.cnf,在 [mysqld] 的下面追加以下内容
[mysqld]
innodb_ft_min_token_size = 1
ft_min_word_len = 1
然后重启 MySQL 服务器,并修复全文索引。注意,修改完参数以后,一定要修复下索引,不然参数不会生效。两种修复方式,可以使用下面的命令修复
repair table test quick;或者直接删掉重新建立索引,再次执行上面的查询,a、aa、aaa 就都可以查出来了。但是,这里还有一个问题,搜索关键字 a 时,为什么 aa、aaa、aaaa 没有出现结果中,讲这个问题之前,先说说两种全文索引。
两种全文索引:
A、自然语言的全文索引
默认情况下,或者使用 in natural language mode 修饰符时,match() 函数对文本集合执行自然语言搜索,上面的例子都是自然语言的全文索引。
自然语言搜索引擎将计算每一个文档对象和查询的相关度。这里,相关度是基于匹配的关键词的个数,以及关键词在文档中出现的次数。在整个索引中出现次数越少的词语,匹配时的相关度就越高。相反,非常常见的单词将不会被搜索,如果一个词语的在超过 50% 的记录中都出现了,那么自然语言的搜索将不会搜索这类词语。上面提到的,测试表中必须有 4 条以上的记录,就是这个原因。
这个机制也比较好理解,比如说,一个数据表存储的是一篇篇的文章,文章中的常见词、语气词等等,出现的肯定比较多,搜索这些词语就没什么意义了,需要搜索的是那些文章中有特殊意义的词,这样才能把文章区分开。
B、布尔全文索引
在布尔搜索中,我们可以在查询中自定义某个被搜索的词语的相关性,当编写一个布尔搜索查询时,可以通过一些前缀修饰符来定制搜索。
MySQL 内置的修饰符,上面查询最小搜索长度时,搜索结果 ft_boolean*_*syntax 变量的值就是内置的修饰符,下面简单解释几个,更多修饰符的作用可以查手册
- + 必须包含该词
- - 必须不包含该词
- > 提高该词的相关性,查询的结果靠前
- < 降低该词的相关性,查询的结果靠后
- (*)星号 通配符,只能接在词后面
对于上面提到的问题,可以使用布尔全文索引查询来解决,使用下面的命令,a、aa、aaa、aaaa 就都被查询出来了。
select * test where match(content) against('a*' in boolean mode);几个注意点
- 使用全文索引前,搞清楚版本支持情况;
- 全文索引比 like + % 快 N 倍,但是可能存在精度问题;
- 如果需要全文索引的是大量数据,建议先添加数据,再创建索引;
- 对于中文,可以使用 MySQL 5.7.6 之后的版本,或者第三方插件。
- 事实上,MyISAM 存储引擎对全文索引的支持有很多的限制,例如表级别锁对性能的影响、数据文件的崩溃、崩溃后的恢复等,这使得 MyISAM 的全文索引对于很多的应用场景并不适合。所以,多数情况下的建议是使用别的解决方案,例如 Sphinx、Lucene 等等第三方的插件,亦或是使用 InnoDB 存储引擎的全文索引。
4)中文的全文检索说明
MySQL 的全文索引最开始仅支持英语,因为英语的词与词之间有空格,使用空格作为分词的分隔符是很方便的。亚洲文字,比如汉语、日语、汉语等,是没有空格的,这就造成了一定的限制。不过 MySQL 5.7.6 开始,引入了一个 ngram 全文分析器来解决这个问题,并且对 MyISAM 和 InnoDB 引擎都有效。从MySQL 5.7.6开始,MySQL内置了ngram全文解析器,用来支持中文、日文、韩文分词。 本文使用的InnoDB数据库引擎。
ngram全文解析器
ngram就是一段文字里面连续的n个字的序列。ngram全文解析器能够对文本进行分词,每个单词是连续的n个字的序列。例如,用ngram全文解析器对“生日快乐”进行分词:
n=1: '生', '日', '快', '乐'
n=2: '生日', '日快', '快乐'
n=3: '生日快', '日快乐'
n=4: '生日快乐'MySQL 中使用全局变量ngram_token_size来配置ngram中n的大小,它的取值范围是1到10,默认值是2。通常ngram_token_size设置为要查询的单词的最小字数。如果需要搜索单字,就要把ngram_token_size设置为1。在默认值是2的情况下,搜索单字是得不到任何结果的。因为中文单词最少是两个汉字,推荐使用默认值2。
创建全文索引
1、创建表的同时创建全文索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR (200),
body TEXT,
FULLTEXT (title, body) WITH PARSER ngram
) ENGINE = INNODB;2、通过 alter table 的方式来添加
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;3、直接通过create index的方式
CREATE FULLTEXT INDEX ft_index ON articles (title,body) WITH PARSER ngram;全文检索模式
常用的全文检索模式有两种: 1、自然语言模式(NATURAL LANGUAGE MODE) , 自然语言模式是MySQL 默认的全文检索模式。自然语言模式不能使用操作符,不能指定关键词必须出现或者必须不能出现等复杂查询。 2、BOOLEAN模式(BOOLEAN MODE) BOOLEAN模式可以使用操作符,可以支持指定关键词必须出现或者必须不能出现或者关键词的权重高还是低等复杂查询。
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('一路 一带' IN NATURAL LANGUAGE MODE);
-- 不指定模式,默认使用自然语言模式
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('一路 一带');
上面的示例返回结果会自动按照相关性排序,相关性高的在前面。相关性的值是一个非负浮点数,0表示无相关性。
-- 获取相关性的值
SELECT id,title,
MATCH (title,body) AGAINST ('手机' IN NATURAL LANGUAGE MODE) AS score
FROM articles
ORDER BY score DESC;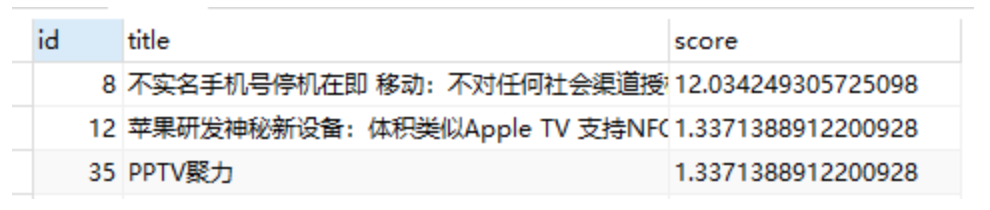
-- 获取匹配结果记录数
SELECT COUNT(*) FROM articles
WHERE MATCH (title,body)
AGAINST ('一路 一带' IN NATURAL LANGUAGE MODE);可以使用BOOLEAN模式执行高级查询。
-- 必须包含"腾讯"
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+腾讯' IN BOOLEAN MODE);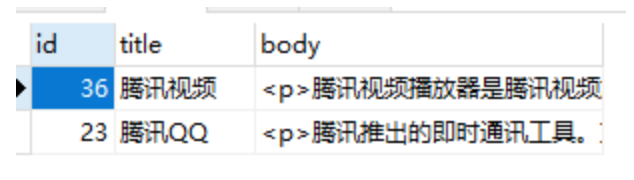
-- 必须包含"腾讯",但是不能包含"通讯工具"
SELECT * FROM articles
WHERE MATCH (title,body)
AGAINST ('+腾讯 -通讯工具' IN BOOLEAN MODE);
下面的例子演示了BOOLEAN模式下运算符的使用方式:
'apple banana'
无操作符,表示或,要么包含apple,要么包含banana
'+apple +juice'
必须同时包含两个词
'+apple macintosh'
必须包含apple,但是如果也包含macintosh的话,相关性会更高。
'+apple -macintosh'
必须包含apple,同时不能包含macintosh。
'+apple ~macintosh'
必须包含apple,但是如果也包含macintosh的话,相关性要比不包含macintosh的记录低。
'+apple +(>juice <pie)'
查询必须包含apple和juice或者apple和pie的记录,但是apple juice的相关性要比apple pie高。
'apple*'
查询包含以apple开头的单词的记录,如apple、apples、applet。
'"some words"'
使用双引号把要搜素的词括起来,效果类似于like '%some words%',
例如“some words of wisdom”会被匹配到,而“some noise words”就不会被匹配。注意
- 只能在类型为CHAR、VARCHAR或者TEXT的字段上创建全文索引。
- 全文索引只支持InnoDB和MyISAM引擎。
- MATCH (columnName) AGAINST ('keywords')。MATCH()函数使用的字段名,必须要与创建全文索引时指定的字段名一致。如上面的示例,MATCH (title,body)使用的字段名与全文索引ft_articles(title,body)定义的字段名一致。如果要对title或者body字段分别进行查询,就需要在title和body字段上分别创建新的全文索引。
- MATCH()函数使用的字段名只能是同一个表的字段,因为全文索引不能够跨多个表进行检索。
- 如果要导入大数据集,使用先导入数据再在表上创建全文索引的方式要比先在表上创建全文索引再导入数据的方式快很多,所以全文索引是很影响TPS的。