支付宝爬虫(Scrapy版本)
问题反馈
在使用中有任何问题,可以反馈给我,以下联系方式跟我交流- Author: Leo
- Wechat: Leo-sunhailin
- E-mail: 379978424@qq.com
- Github URL: 项目链接
目前的进度
-
2018年8月8日:
- 支付宝又双叒叕改了个人主页的样式和数据获取方式
- 之前有一段时间可以通过接口进行获取,但现在支付宝取消了这个接口
- 支付宝又双叒叕改了个人主页的样式和数据获取方式
-
2018年7月2日:
-
题外话:
- 又好一段时间才捡起这个项目.对支付宝这个反爬开始绝望了.
- 最近应该会研究下...感觉selenium解决不了问题...
-
更新项目:
- 解决了下Windows控制台的报错的问题(加入了一个win_unicode_console包)
- 删除了一些无用的代码
-
-
2018年3月14日:
-
题外话:
- 好一段时间没有更新了,支付宝的反爬有点强.慢慢研究~
-
更新项目:
- 加入二维码登录的方式(需要自己手动扫码)
-
-
2018年2月4日:
- 更新说明看Release
-
2018年1月:
-
将更新提上日程,在测试二维码登录.先上个半成品
-
原先密码登陆的现在基本上不能用了.因为个人页面多了一种反爬手段,其次就是跳出二维码页面.
-
上面这些问题,将在之后尽量解决.
-
-
大概在2017年11月~12月的样子:
-
开始出现跳出验证码页面了.原因应该是支付宝反爬的模型增强了.
-
这段时间维护时间不多,都是个人测试没有更新代码上去
-
-
2017年10月 参加DoraHacks时:
- 当时能够获取到账单和账户信息.
开发环境
-
系统版本:Win10 x64
-
Python版本:3.4.4
-
Python库版本列表:
-
Pillow: 5.0.0
-
Scrapy:1.4.0
-
selenium:3.8.1
-
requests:2.18.4
-
pymongo:3.6.0
-
python_dateutil:2.6.1
-
-
-
Ps: 一定要配好Python的环境,不然Scrapy的命令可能会跑不起来
安装和运行方式
* 安装库# !!!最新登录方式(暂未加入命令, 切换登录需要自己的去改动代码) --- 推荐方式!!!
python cmdline_start_spider.py # 项目根目录下,打开命令行
pip install -r requirements.txt- 启动
# 项目根目录下,启动爬虫
scrapy crawl AlipaySpider -a username="你的用户名" -a password="你的密码"
# 必选参数
-a username=<账号>
-a password=<密码>
# 可选参数
-a option=<爬取类型>
# 1 -> 购物; 2 -> 线下; 3 -> 还款; 4 -> 缴费
# 这里面有四种类型数据对应四种不同的购物清单
#####################################################
# 实验版本
scrapy crawl AlipayQR
# 暂时还没有参数, 能登陆到个人页面了(概率到账单页面).功能
- 模拟登录支付宝(账号密码和二位都可以登陆)
- 获取自定义账单记录和花呗剩余额度(2017年10月份的时候个人页面还有花呗总额度的,后面改版没有了.再之后又出现了,应该是支付宝内部在做调整)
- 数据存储在MongoDB中(暂时存储在MongoDB,后续支持sqlite,json或其他格式的数据)
- 日志记录系统,启动爬虫后会在项目根目录下创建一个Alipay.log的文件(同时写入文件和输出在控制台)
技术点
吐槽一下: 这点可能没啥好说,因为代码是从自己之前写的用非框架的代码搬过来的,搬过来之后主要就是适应Scrapy这个框架,理解框架的意图和执行顺序以及项目的结构,然后进行兼容和测试。
我这个项目主要就用到Spider模块(即爬虫模块),Pipeline和item(即写数据的管道和实体类)
Downloader的那块基本没做处理,因为核心还是在用selenium + webdriver,解析页面用的是Scrapy封装好的Selector.
Scrapy具体的流程看下图: (从官方文档搬过来的)
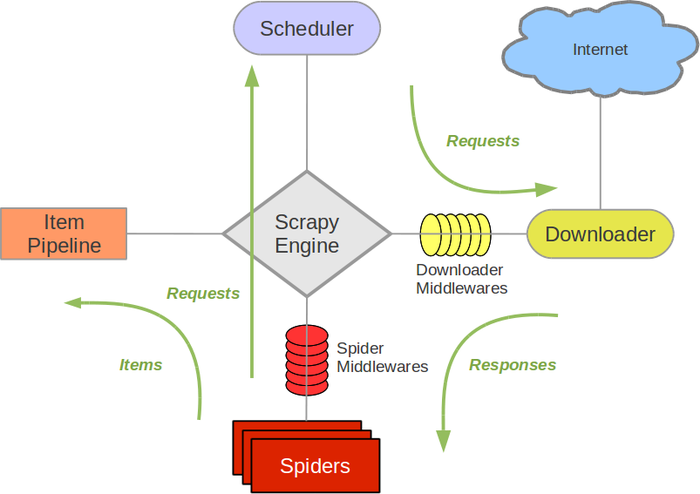
题外话
题外话模块: 上一段讲到了一个Selector,这个是东西是Scrapy基于lxml开发的,但是真正用的时候其实和lxml的selector有点区别.
举个例子吧:
# 两段相同的标签获取下面的文字的方式
# lxml
name = str(tr.xpath('td[@class="name"]/p/a/text()').strip()
# Scrapy
name = tr.xpath('string(td[@class="name"]/p/a)').extract()[0].strip()两行代码对同一个标签的文字提取的方法有些不一样,虽然到最后的结果一样。
lxml中有一个"string(.)"方法也是为了提取文字,但是这个方法是要在先指定了父节点或最小子节点后再使用,就可以获取父节点以下的所有文字或最小子节点对应的文字信息.
而Scrapy的Selector则可以在"string(.)"里面写入标签,方便定位,也很清晰的看出是要去获取文字信息.
具体区别其实可以对比下我非框架下的和Scrapy框架下的代码,里面用xpath定位的方式有点不一样.
未来的进度
- 解决账单获取的问题,目前基本都被二维码页面挡住了(需要研究一段时间)
- 下面的搁置着先:
- 数据源保存的可选择性(从多源选择单源写入到多源写入)
- 修改配置文件的自由度(增加修改settings.py的参数)
- 尽可能优化爬虫的爬取速度
- 研究Scrapy的自定义命令的写法,提高扩展性