Churn-prediction

Customer churn predicted with 87% accuracy using state-of-the-art technique.
Customer churn prediction slashes marketing costs upto 40%. Significant historical work has been done on it and almost every company in the world uses such a tool. I present a holistic data science pipeline and the use of LightGBM which is very robust to unusual distributions and is one of the fastest machine learning algorithm till date.
Some results of EDA
Exited vs Balance plot -> People with very high or very low balance are more likely to leave the bank
Exited vs credit score -> No suprises, low credit score leads to people changing their banks
How are classes balanced?
Customer churn is a typicall class imbalance problem. I found SMOTE the best method for solving this problem.
SMOTE (Synthetic Minority Oversampling Technique) is a synthetic data generation technique, it works as follows:
- Identify a data point and its nearest neighbour
- Take their difference
- Multiply this difference by a random number between 0 and 1
- Identify a new point on this line segment by adding the random number to the data point choosen
- Repeat the process
Other techniques which can be used are:
- Collect more data
- Use a different performance metric like AUROC or kappa
- Undersample or Oversample the data
- Try different algorithms like decision tree and its derivates can work here as the splitting rule can force both classes to be adressed
- Try penalized models
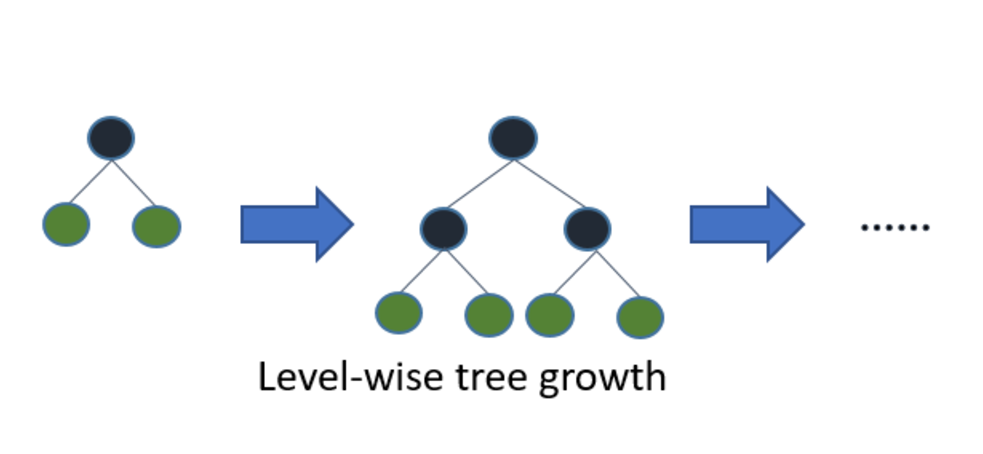
LGBM
Light gbm is a class of gradient boosting methods which uses goss sampling method. Gradient boosting works by training a weak predictor, which produces some residuals. Then these residuals serve as an output for another decision tree (predictor). Similarly, a lot of decision trees are connected sequentially.
If an instance is associated with a small gradient, the training error for this instance is small and it is already well-trained. A straightforward idea is to discard those data instances with small gradients.
However, the data distribution will be changed by doing so, which will hurt the accuracy of the learned
model. To avoid this problem, Gradient-based One-Side Sampling (GOSS) is used.
GOSS firstly sorts the data instances according to the absolute value of their gradients and selects the top a×100% instances. Then it randomly samples b×100% instances from the rest of the data. After that, GOSS amplifies the sampled data with small gradients by a constant 1−a b when calculating the information gain. By doing so, we put more focus on the under-trained instances without changing the original data distribution by much.
For Gradient boosting decision tree, information gain is measured by variance after splitting. Variance of splitting feature j at a point d for that node is equal to: ((sum (Gi^2/number of Xi less than/equal to d)) + (sum (Gi^2/number of Xi greater than d))) / n.
Installation
- Download the data from superdatascience.com
- Clone this repository to your computer.
- Get into the folder using cd Churn-prediction.
Installing the requirements
- pip install lightgbm
- pip install pandas
- pip install numpy
- pip install matplotlib
- pip install seaborn
Usage from scratch
- Run each cell in preprocessing.ipynb for preprocessing steps like one-hot encoding and dropping id and name columns
- Then, run each cell of Feature Engineering.ipynb for engineering some features by having some domain knowledge
- Then, run each cell of Balancing_classes.ipynb for balancing classes using SMOTE
- Then, run each cell of EDA.ipynb for knowing your features and their realtion with churning. Feature selection using exploration and correlations is done.
- Lastly, run each cell of train.ipynb to train the Lightgbm model.
Tool Usage
- Open terminal (in Linux/MacOS) or command prompt (in Windows)
- Type python3 UI.py
- Enter details
- Click on submit