


This repository contains the code to reproduce the results from the paper Occupancy Networks - Learning 3D Reconstruction in Function Space.
You can find detailed usage instructions for training your own models and using pretrained models below.
If you find our code or paper useful, please consider citing
@inproceedings{Occupancy Networks,
title = {Occupancy Networks: Learning 3D Reconstruction in Function Space},
author = {Mescheder, Lars and Oechsle, Michael and Niemeyer, Michael and Nowozin, Sebastian and Geiger, Andreas},
booktitle = {Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
First you have to make sure that you have all dependencies in place. The simplest way to do so, is to use anaconda.
You can create an anaconda environment called mesh_funcspace using
conda env create -f environment.yaml
conda activate mesh_funcspace
Next, compile the extension modules. You can do this via
CXX=gcc python setup.py build_ext --inplace
To compile the dmc extension, you have to have a cuda enabled device set up.
If you experience any errors, you can simply comment out the dmc_* dependencies in setup.py.
You should then also comment out the dmc imports in im2mesh/config.py.


You can now test our code on the provided input images in the demo folder.
To this end, simply run
python generate.py configs/demo.yaml
This script should create a folder demo/generation where the output meshes are stored.
The script will copy the inputs into the demo/generation/inputs folder and creates the meshes in the demo/generation/meshes folder.
Moreover, the script creates a demo/generation/vis folder where both inputs and outputs are copied together.
To evaluate a pretrained model or train a new model from scratch, you have to obtain the dataset. To this end, there are two options:
- you can download our preprocessed data
- you can download the ShapeNet dataset and run the preprocessing pipeline yourself
Take in mind that running the preprocessing pipeline yourself requires a substantial amount time and space on your hard drive. Unless you want to apply our method to a new dataset, we therefore recommmend to use the first option.
You can download our preprocessed data (73.4 GB) using
bash scripts/download_data.sh
This script should download and unpack the data automatically into the data/ShapeNet folder.
Alternatively, you can also preprocess the dataset yourself. To this end, you have to follow the following steps:
- download the ShapeNet dataset v1 and put into
data/external/ShapeNet. - download the renderings and voxelizations from Choy et al. 2016 and unpack them in
data/external/Choy2016 - build our modified version of mesh-fusion by following the instructions in the
external/mesh-fusionfolder
You are now ready to build the dataset:
cd scripts
bash dataset_shapenet/build.sh
This command will build the dataset in data/ShapeNet.build.
To install the dataset, run
bash dataset_shapenet/install.sh
If everything worked out, this will copy the dataset into data/ShapeNet.
When you have installed all binary dependencies and obtained the preprocessed data, you are ready to run our pretrained models and train new models from scratch.
To generate meshes using a trained model, use
python generate.py CONFIG.yaml
where you replace CONFIG.yaml with the correct config file.
The easiest way is to use a pretrained model. You can do this by using one of the config files
configs/img/onet_pretrained.yaml
configs/pointcloud/onet_pretrained.yaml
configs/voxels/onet_pretrained.yaml
configs/unconditional/onet_cars_pretrained.yaml
configs/unconditional/onet_airplanes_pretrained.yaml
configs/unconditional/onet_sofas_pretrained.yaml
configs/unconditional/onet_chairs_pretrained.yaml
which correspond to the experiments presented in the paper.
Our script will automatically download the model checkpoints and run the generation.
You can find the outputs in the out/*/*/pretrained folders.
Please note that the config files *_pretrained.yaml are only for generation, not for training new models: when these configs are used for training, the model will be trained from scratch, but during inference our code will still use the pretrained model.
For evaluation of the models, we provide two scripts: eval.py and eval_meshes.py.
The main evaluation script is eval_meshes.py.
You can run it using
python eval_meshes.py CONFIG.yaml
The script takes the meshes generated in the previous step and evaluates them using a standardized protocol.
The output will be written to .pkl/.csv files in the corresponding generation folder which can be processed using pandas.
For a quick evaluation, you can also run
python eval.py CONFIG.yaml
This script will run a fast method specific evaluation to obtain some basic quantities that can be easily computed without extracting the meshes. This evaluation will also be conducted automatically on the validation set during training.
All results reported in the paper were obtained using the eval_meshes.py script.
Finally, to train a new network from scratch, run
python train.py CONFIG.yaml
where you replace CONFIG.yaml with the name of the configuration file you want to use.
You can monitor on http://localhost:6006 the training process using tensorboard:
cd OUTPUT_DIR
tensorboard --logdir ./logs --port 6006
where you replace OUTPUT_DIR with the respective output directory.
For available training options, please take a look at configs/default.yaml.
- In our paper we used random crops and scaling to augment the input images.
However, we later found that this image augmentation decreases performance on the ShapeNet test set.
The pretrained model that is loaded in
configs/img/onet_pretrained.yamlwas hence trained without data augmentation and has slightly better performance than the model from the paper. The updated table looks a follows: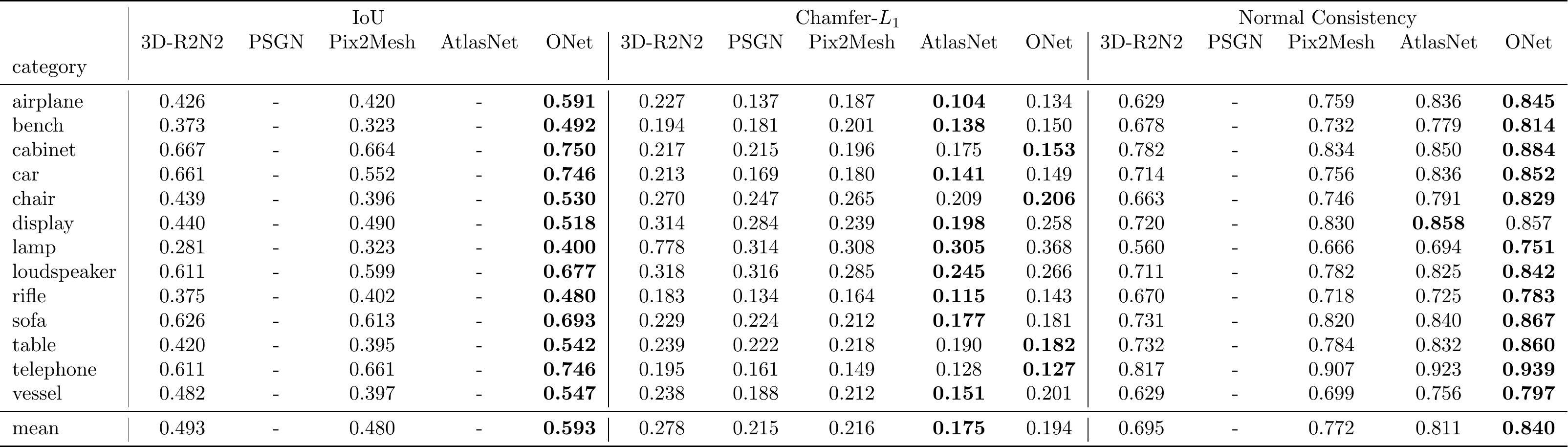 For completeness, we also provide the trained weights for the model which was used in the paper in
For completeness, we also provide the trained weights for the model which was used in the paper in configs/img/onet_legacy_pretrained.yaml. - Note that training and evaluation of both our model and the baselines is performed with respect to the watertight models, but that normalization into the unit cube is performed with respect to the non-watertight meshes (to be consistent with the voxelizations from Choy et al.). As a result, the bounding box of the sampled point cloud is usually slightly bigger than the unit cube and may differ a little bit from a point cloud that was sampled from the original ShapeNet mesh.

Please also check out the following concurrent papers that have proposed similar ideas: