XAI is a Machine Learning library that is designed with AI explainability in its core. XAI contains various tools that enable for analysis and evaluation of data and models. The XAI library is maintained by The Institute for Ethical AI & ML, and it was developed based on the 8 principles for Responsible Machine Learning.
You can find the documentation at https://ethicalml.github.io/xai/index.html. You can also check out our talk at Tensorflow London where the idea was first conceived - the talk also contains an insight on the definitions and principles in this library.
| This video of the talk presented at the PyData London 2019 Conference which provides an overview on the motivations for machine learning explainability as well as techniques to introduce explainability and mitigate undesired biases using the XAI Library. |
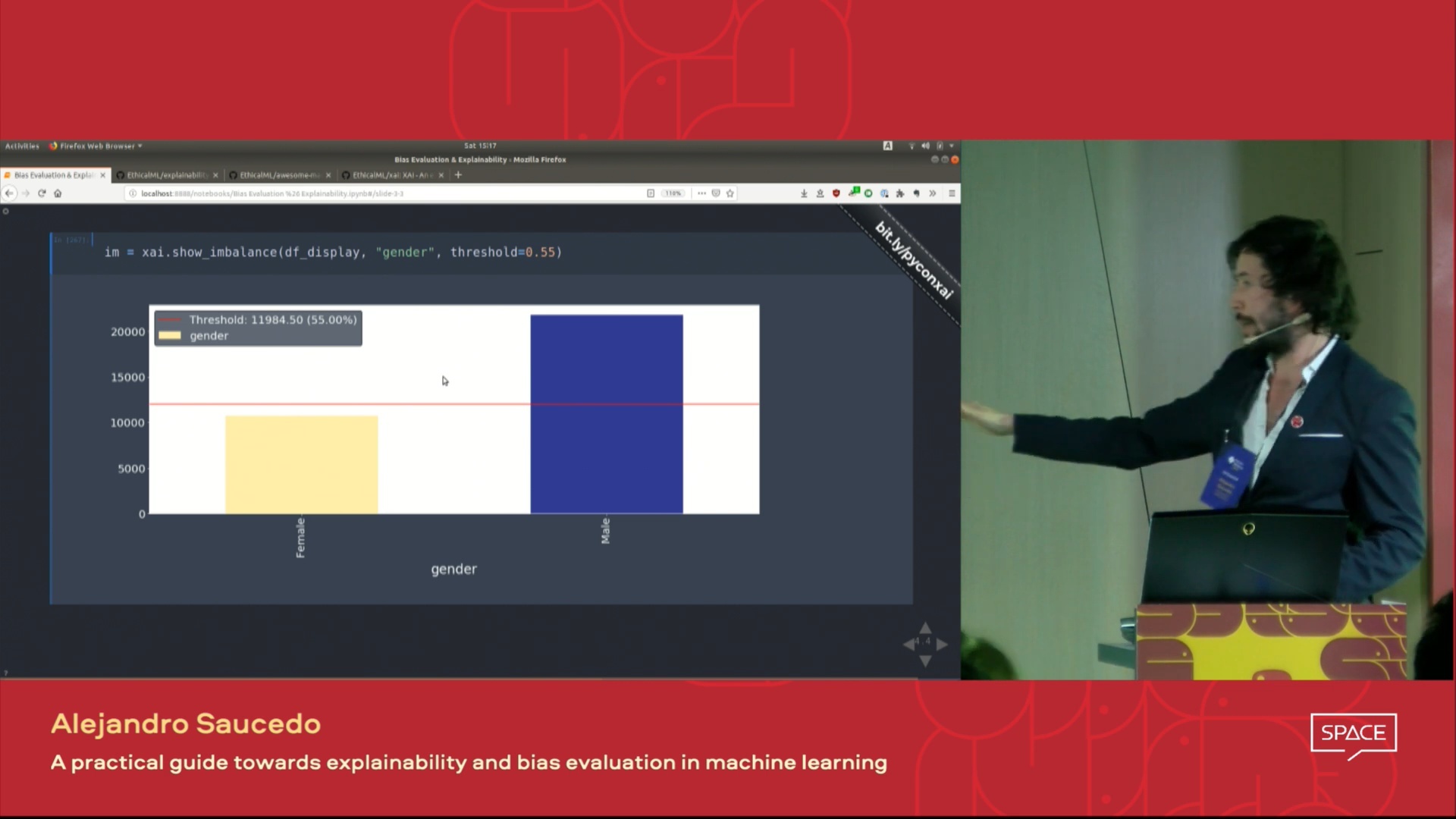
|
| Do you want to learn about more awesome machine learning explainability tools? Check out our community-built "Awesome Machine Learning Production & Operations" list which contains an extensive list of tools for explainability, privacy, orchestration and beyond. |
|
This library is currently in early stage developments and hence it will be quite unstable due to the fast updates. It is important to bare this in mind if using it in production.
If you want to see a fully functional demo in action clone this repo and run the Example Jupyter Notebook in the Examples folder.
We see the challenge of explainability as more than just an algorithmic challenge, which requires a combination of data science best practices with domain-specific knowledge. The XAI library is designed to empower machine learning engineers and relevant domain experts to analyse the end-to-end solution and identify discrepancies that may result in sub-optimal performance relative to the objectives required. More broadly, the XAI library is designed using the 3-steps of explainable machine learning, which involve 1) data analysis, 2) model evaluation, and 3) production monitoring.
We provide a visual overview of these three steps mentioned above in this diagram:

The XAI package is on PyPI. To install you can run:
pip install xai
Alternatively you can install from source by cloning the repo and running:
python setup.py install
You can find example usage in the examples folder.
With XAI you can identify imbalances in the data. For this, we will load the census dataset from the XAI library.
import xai.data
df = xai.data.load_census()
df.head()
ims = xai.imbalance_plot(df, "gender")
im = xai.show_imbalance(df, "gender", "loan")
bal_df = xai.balance(df, "gender", "loan", upsample=0.8)
groups = xai.group_by_columns(df, ["gender", "loan"])
for group, group_df in groups:
print(group)
print(group_df["loan"].head(), "\n")
_ = xai.correlations(df, include_categorical=True, plot_type="matrix")
_ = xai.correlations(df, include_categorical=True)
# Balanced train-test split with minimum 300 examples of
# the cross of the target y and the column gender
x_train, y_train, x_test, y_test, train_idx, test_idx = \
xai.balanced_train_test_split(
x, y, "gender",
min_per_group=300,
max_per_group=300,
categorical_cols=categorical_cols)
x_train_display = bal_df[train_idx]
x_test_display = bal_df[test_idx]
print("Total number of examples: ", x_test.shape[0])
df_test = x_test_display.copy()
df_test["loan"] = y_test
_= xai.imbalance_plot(df_test, "gender", "loan", categorical_cols=categorical_cols)
We are able to also analyse the interaction between inference results and input features. For this, we will train a single layer deep learning model.
model = build_model(proc_df.drop("loan", axis=1))
model.fit(f_in(x_train), y_train, epochs=50, batch_size=512)
probabilities = model.predict(f_in(x_test))
predictions = list((probabilities >= 0.5).astype(int).T[0])

def get_avg(x, y):
return model.evaluate(f_in(x), y, verbose=0)[1]
imp = xai.feature_importance(x_test, y_test, get_avg)
imp.head()
_= xai.metrics_plot(
y_test,
probabilities)
_ = xai.metrics_plot(
y_test,
probabilities,
df=x_test_display,
cross_cols=["gender"],
categorical_cols=categorical_cols)
_ = xai.metrics_plot(
y_test,
probabilities,
df=x_test_display,
cross_cols=["gender", "ethnicity"],
categorical_cols=categorical_cols)
xai.confusion_matrix_plot(y_test, pred)
_ = xai.roc_plot(y_test, probabilities)
protected = ["gender", "ethnicity", "age"]
_ = [xai.roc_plot(
y_test,
probabilities,
df=x_test_display,
cross_cols=[p],
categorical_cols=categorical_cols) for p in protected]
d = xai.smile_imbalance(
y_test,
probabilities)
d = xai.smile_imbalance(
y_test,
probabilities,
display_breakdown=True)
d = xai.smile_imbalance(
y_test,
probabilities,
bins=9,
threshold=0.75,
manual_review=0.375,
display_breakdown=False)