Twitter的存档备份包,我们可以用 grailbird_update 更新备份(见 https://www.yiwan.org/index.php/ltd_documents/384-use-grailbird_update-to-backup-tweets.html) 。只要双击存档备份包里的 index.html 就能够在浏览器里浏览全部推文历史。但是,这个存档浏览可能不是我喜欢的风格,我也不想需要太多元素,我只需要其中一部分内容即可,这个存档 tweets 里包含的图片还是在 twitter 上存储,我又想下载到本地,我还想在我的博客里展示我一段时间内的 tweets ,…… 这么多需求怎么办?只能定制,于是有了下面我的探索路程:批量导出 Tweets 为指定格式内容,并下载相关图片和视频资源到本地,真正实现个性化、离线化。
以下是Twitter存档备份包的文件目录结构:
Tweets_Litanid/
├── css
│ └── application.min.css
├── data
│ └── js
│ ├── payload_details.js
│ ├── tweet_index.js
│ ├── tweets
│ │ ├── 2014_10.js
│ │ ├── 2014_11.js
│ │ ├── 2015_03.js
│ │ ├── …………………………
│ │ ├── …………………………
│ │ ├── …………………………
│ │ ├── …………………………
│ │ ├── 2018_02.js
│ └── user_details.js
├── img
│ ├── bg.png
│ └── sprite.png
├── index.html
├── js
│ ├── application.js
│ └── zh-CN.js
├── lib
│ ├── bootstrap
│ │ ├── bootstrap-dropdown.js
│ │ ├── bootstrap.min.css
│ │ ├── bootstrap-modal.js
│ │ ├── bootstrap-tooltip.js
│ │ ├── bootstrap-transition.js
│ │ ├── glyphicons-halflings.png
│ │ └── glyphicons-halflings-white.png
│ ├── hogan
│ │ └── hogan-2.0.0.min.js
│ ├── jquery
│ │ └── jquery-1.8.3.min.js
│ ├── twt
│ │ ├── sprite.png
│ │ ├── sprite.rtl.png
│ │ ├── twt.all.min.js
│ │ └── twt.min.css
│ └── underscore
│ └── underscore-min.js
├── README.md
├── README.txt
└── tweets.csv
tweets 信息存储有两种格式,一种是.csv格式,上述结构目录树中的tweets.csv便是,另外一种是 json 格式,上述结构目录树中的2014_10.js、 2014_11.js等以年份_月份命名的.js文件便是。刚从 Twitter 官方下载的存档包,两种数据格式都包含所有的推文信息(当然不包含图片和视频)。用 grailbird_update 更新存档备份包,不更新tweets.csv,只更新 json 数据格式,默认只更新三个文件,一是更新增加修改上述以年份_月份命名的.js文件,再就是更新修改payload_details.js和stweet_index.js文件。
如从tweets.csv里提取 tweets 信息,可以参考 Tweet Archive Logger 仓库(https://github.com/liam-m/TweetArchiveLogger), 相关代码见此仓库的 tweet_archive_logger_by_liam-m.py代码文件。
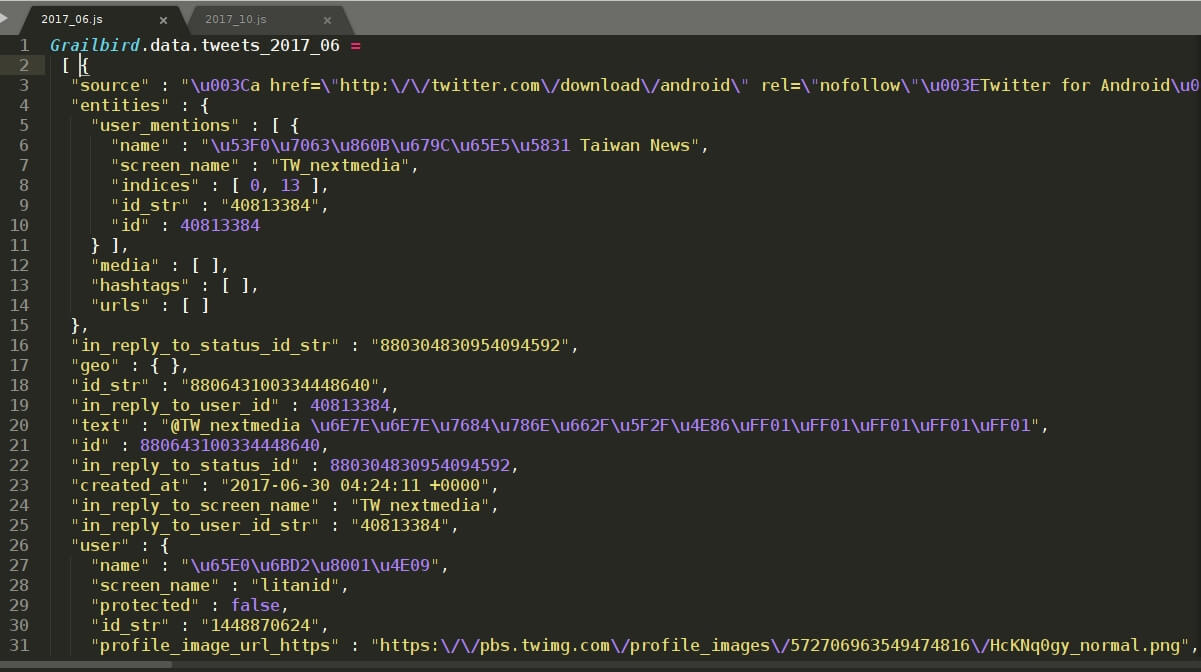
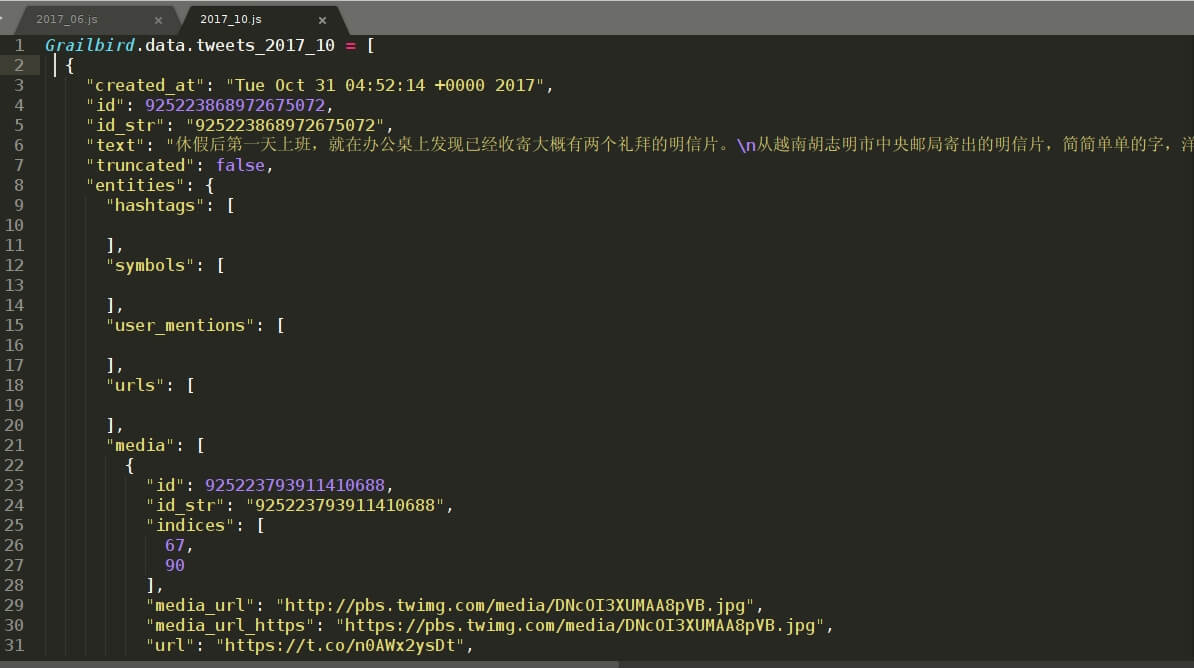
在这里,我们要处理的是以年份_月份命名的.js文件,如2014_10.js、 2014_11.js等,从其中提取 tweets 信息。每个文件包含其中一个月内的全部推文。.js文件内 tweet 存储格式以启用 grailbird_update 更新存档备份包时刻为分界点划分为两部分,之前与之后的格式不一样。我是2017年8月24日启用 grailbird_update 更新存档备份包的,所以我的2017_08.js文件里包含两种存储格式的 tweets 。之前的我们以2017_06.js 为例,之后的我们以2017_10.js为例。如下图:
区别主要有三点:
- "created_at" 时间格式不一样,
2017_06.js里显示的是:"2017-06-22 09:31:07 +0000",2017_10.js里显示的是:"Tue Oct 31 04:52:14 +0000 2017"。 - "text" 显示格式不一样,
2017_06.js显示的是诸如"\u8F66\u7EC8……"的 unicode 编码,2017_10.js里直接显示汉字。 - 如果有多于一张图片,
2017_06.js里所有图片信息在 "entities"->"media" 里,2017_10.js则是在 "extended_entities"->"media" 里。
所以,处理 tweets 信息代码也是有针对性的区分。
此仓库里代码文件extract-tweets_by_DrDrang.py是 Dr. Drang 在博文 Completing my Twitter archive(http://www.leancrew.com/all-this/2013/01/completing-my-twitter-archive/) 里的代码。代码文件twitter-export-image-fill_by_MarcinWichary.py
是 mwichary 在他的 Github repository:twitter-export-image-fill(https://github.com/mwichary/twitter-export-image-fill) 里的代码。我改写完善的文件extract-tweets-to-md_by_litanid_after.py和extract-tweets-to-md_by_litanid_before.py主要是参考借鉴这两篇文章。带 before 的是针对启用 grailbird_update 更新前存档备份包的 json 文件。代码文件extract-tweets-to-md_by_litanid_after.py介绍说明详见我的博文文章《批量处理 Tweets》(https://www.yiwan.org/index.php/ltd_documents/390-batch-processing-tweets.html)。
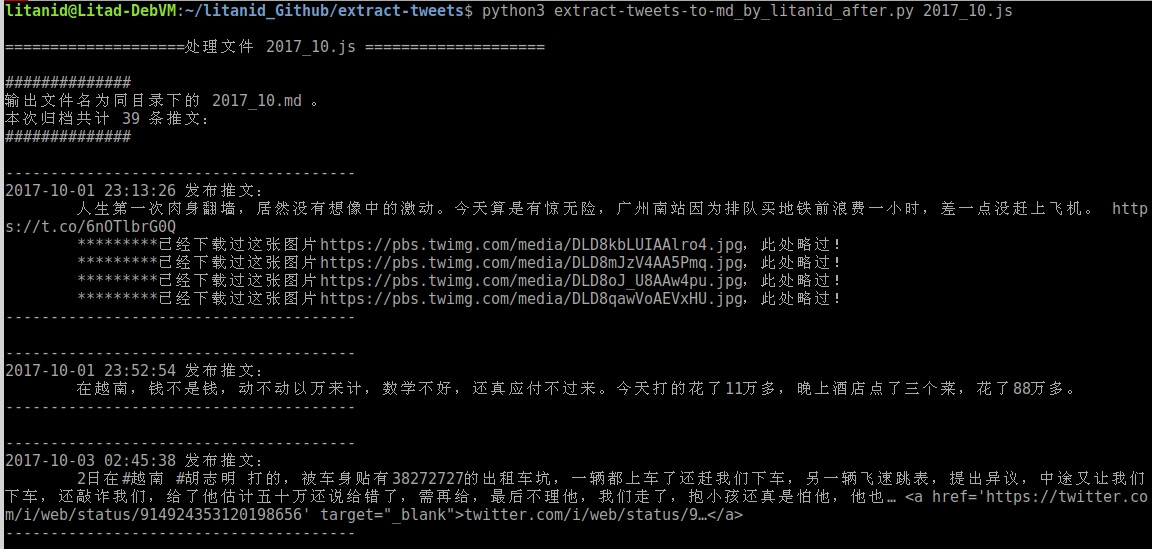
用 python3 运行extract-tweets-to-md_by_litanid_after.py后面跟随放置在同目录下的2017_10.js文件(可以多个文件),运行结果显示如下:
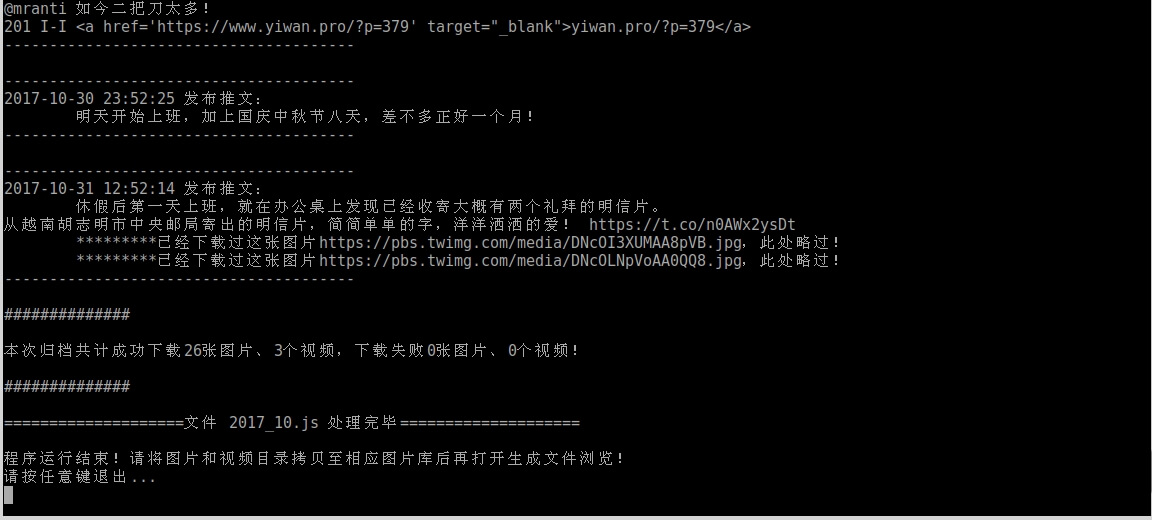
生成同目录下的2017_10.md文件,内容如下:
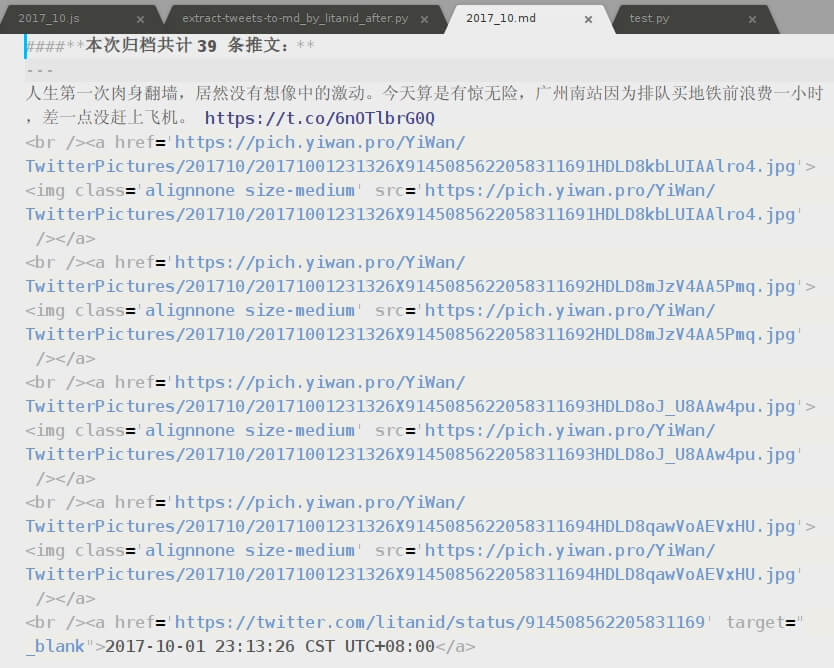
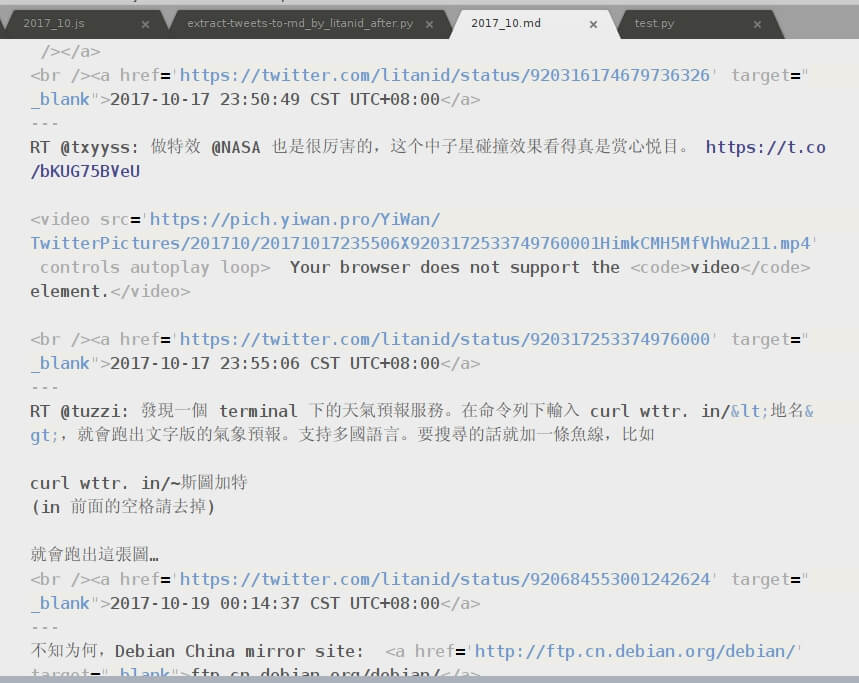
将生成的同目录下的“201710”文件夹拷贝到服务器目录https://pich.yiwan.pro/YiWan/TwitterPictures/下,再在浏览器预览2017_10.md文件,结果显示如下:
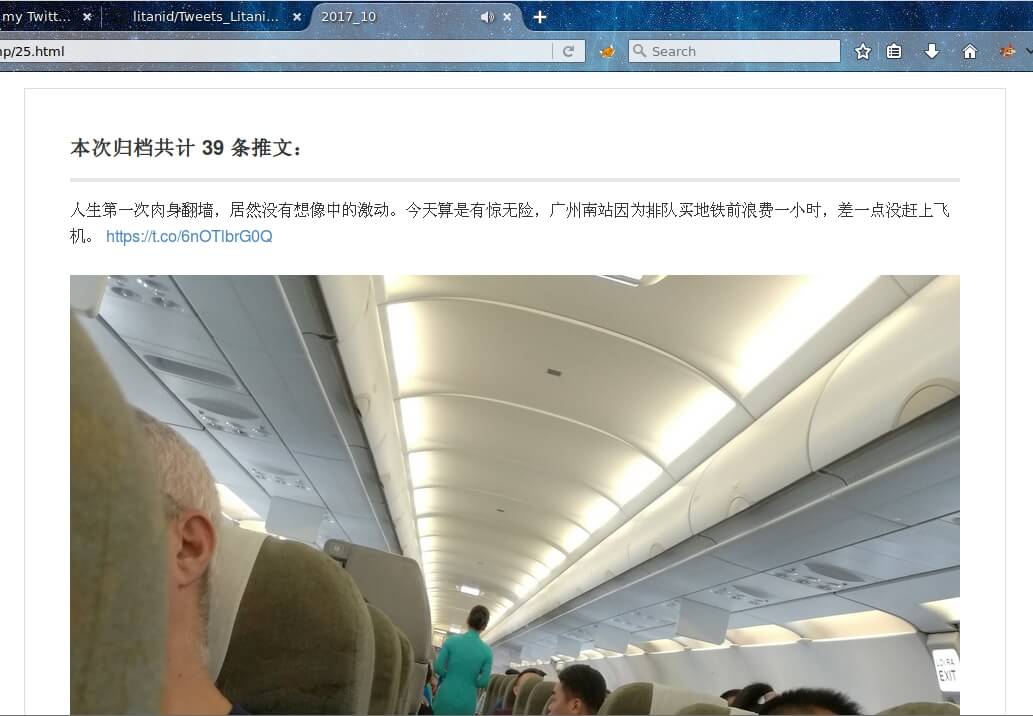
至此处理完毕。输出 Markdown 文件,当然也可以按自己需求输出为其他格式文件。extract-tweets-to-wp_by_litanid_after.py 文件运行输出结果可以直接贴到 wordpress 文章代码编辑窗口里,此处不述,详请看代码。