Milvus 是在2019年创建的,其唯一目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。作为一个专门设计用于处理输入向量查询的数据库,它能够处理万亿级别的向量索引。与现有的关系型数据库主要处理遵循预定义模式的结构化数据不同,Milvus从底层设计用于处理从非结构化数据转换而来的嵌入向量。
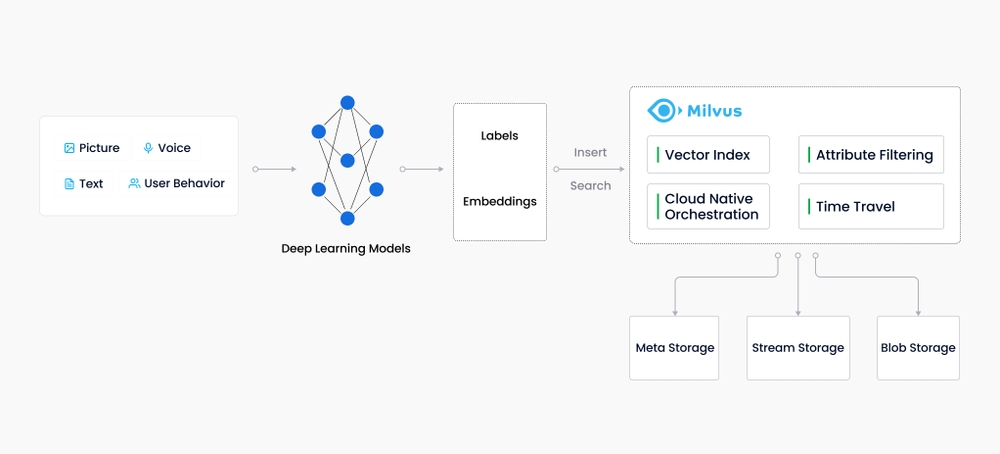
如果您对向量数据库和相似度搜索的世界还不熟悉,请阅读以下关键概念的解释,以更好地理解。
-
非结构化数据:包括图像、视频、音频和自然语言等信息,这些信息不遵循预定义的模型或组织方式。这种数据类型占据了世界数据的约80%,可以使用各种人工智能(AI)和机器学习(ML)模型将其转换为向量。
-
嵌入向量:是对非结构化数据的特征抽象。数学上,嵌入向量是一个浮点数或二进制数的数组。现代的嵌入技术被用于将非结构化数据转换为嵌入向量。
-
向量相似度搜索:是将向量与数据库进行比较,以找到与查询向量最相似的向量的过程。使用近似最近邻搜索算法加速搜索过程。如果两个嵌入向量非常相似,那么原始数据源也是相似的。
-
高性能:在处理大规模数据集的向量搜索时具有高性能。
-
开发者社区:开发者优先的社区,提供多语言支持和工具链。
-
云扩展性:高可靠性,即使出现故障也不会受到影响。
-
混合搜索:通过将标量过滤与向量相似度搜索配对,实现混合搜索。
本文文档为 第三方维护 的中文文档,所有内容基于官方英文文档进行机翻和人工校对,人力资源紧张,如果你有发现任何错误,欢迎提 issues 和 pr.
- fork 仓库
- 翻译文字
- 图片拉入public/assets/文件夹下,所有图片路径(../../../assets/)替换为/assets/。
- 替换所有跳转链接执行 links_convert.py
- 生成目录映射文件_meta.json,执行update_Chinese_metajson.py 配置项将"need_create_meta"设置为 1。
- 中英文目录映射,pages下的aggregated_meta.json存放了中英文对照。执行update_Chinese_metajson.py 配置项将"need_replace_values"设置为 1,

"openaidoc": {
"title": "Openai中文文档",
"type": "page",
"href": "https://www.openaidoc.com.cn/",
"newWindow": true
},
"milvus-io": {
"title": "Milvus-io 中文文档",
"type": "page",
"href": "https://www.milvus-io.com",
"newWindow": true
},
"langchain":{
"title": "Langchain 中文文档",
"type": "page",
"href": "https://www.langchain.com.cn/",
"newWindow": true
}