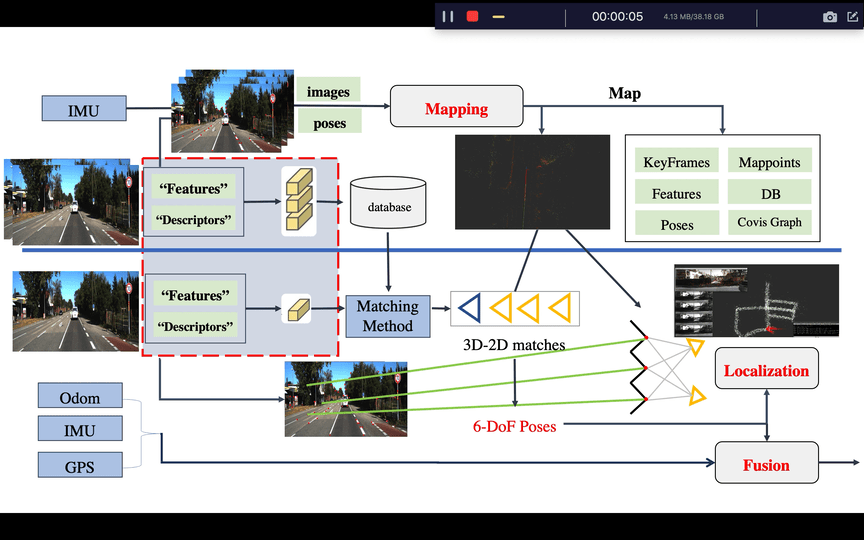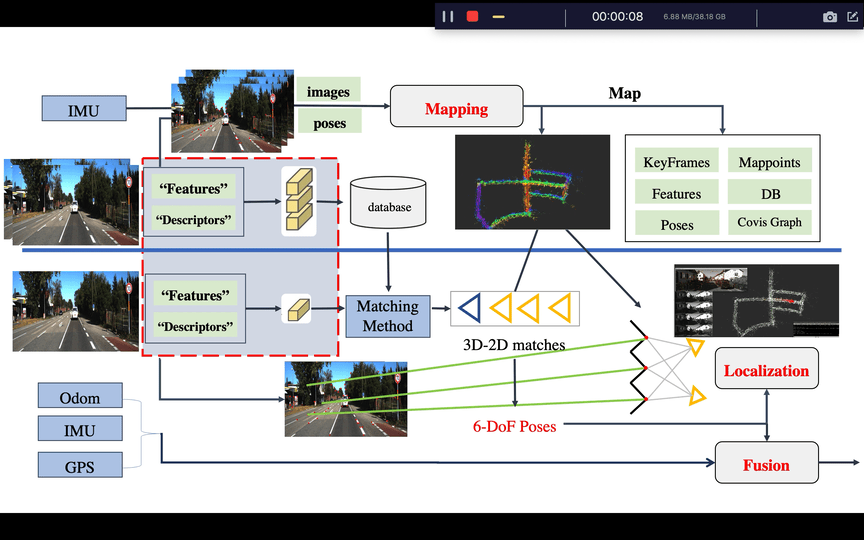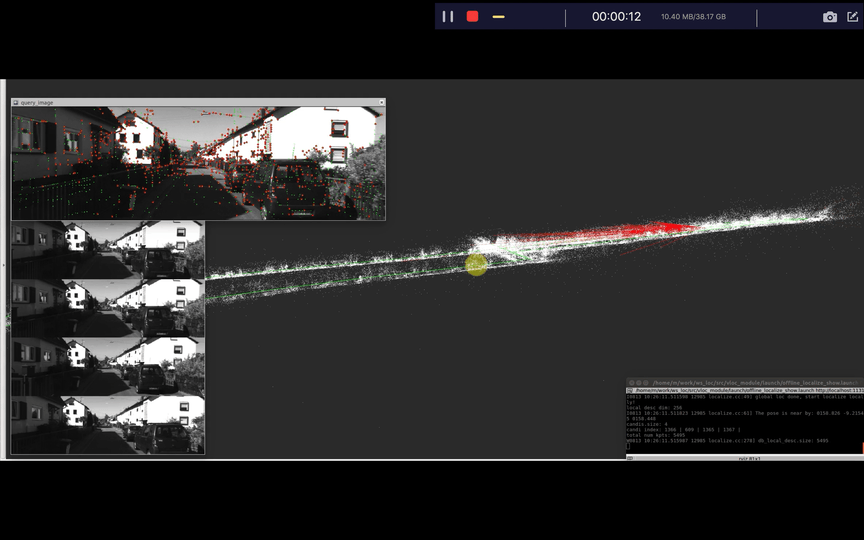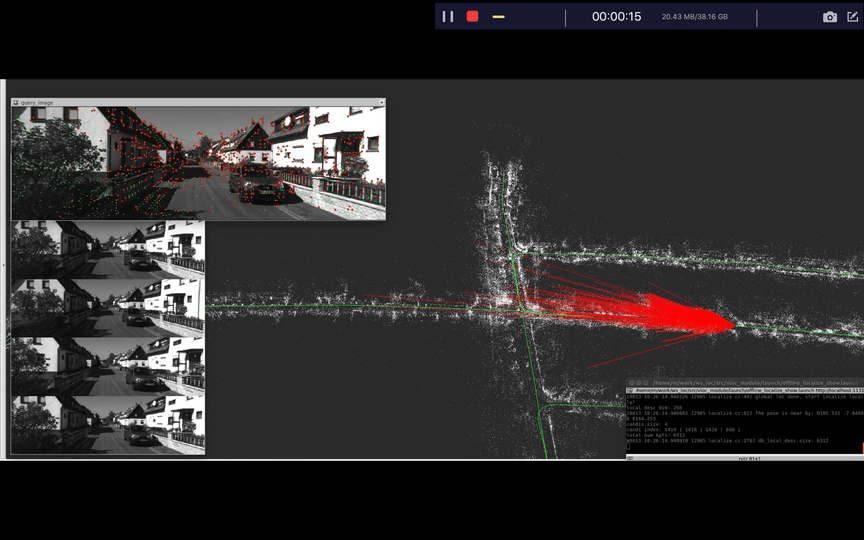
A general framework for map-based visual localization. It contains
-
Map Generation which support traditional features or deeplearning features.
-
Hierarchical-Localizationvisual in visual(points or line) map.
-
Fusion framework with IMU, wheel odom and GPS sensors.
I will release some related papers and An introduction of the work in the map based visual localization. I guess the introduction will writen in Chinese first. So coming soon, Let's do it.

- 2020.09.19 添加了微小贡献的github repo链接
- 2020.09.19 添加了第五章的部分内容
- 2020.09.04 添加文章结构
[TOC]
基于已知地图的视觉定位是一个比较大的问题,基本上会涉及到slam系统,重定位,图像检索,特征点提取及匹配,多传感器融合领域。
作者:钟心亮 https://github.com/TurtleZhong
在写本文之前,我想先简单的总结一下历年用的比较多的slam系统,另外会提出一些开放性的思考问题,这些思考性的问题我也会提供一个简单粗暴的替代办法或者思路,然后后面讲这个项目可以解决的一些问题以及后面还要探究的问题,原则上来讲,本文:
a)应该不会放出太多的代码[当然看心情],但会整理一些这个项目参考过的有意思的项目以及一些教学性代码小样;
b)不会涉及到太多公式细节,尽量写成白话文,且大多数东西都能在github上找到或者进行魔改;
c)会有这个项目的一些框架图,以及效果图,应该会对想涉足这个领域的有帮助;
d)会涉及到slam系统,重定位,图像检索,特征点提取及匹配,多传感器融合领域。
主要做了以下方面的一些工作,但也并不是说拿来就能用。
a)基本上支持绝大部分SLAM系统的输出轨迹进行视觉地图构建,当然这是离线的,一方面,有些slam系统的历史轨迹是会经过优化的,所以这部分是拿最终的轨迹和图像来进行离线选择pose和image进行SFM构建地图的;
b)支持传统特征如SIFT以及深度学习特征如SuperPoint等众多特征的地图构建,但问题在于轨迹的来源是各式各样的,我甚至可以使用rtk或者激光雷达作为真值,但实际重定位使用的时候必须要使用与构建视觉地图的特征一致,不然是会定位失败的;这里建议参考一些开源SFM的文档,hack它们也不算难。
c)整个框架在线定位基本基于C++开发,可以方便集成到ROS,所以也许会提供一个提取深度学习特征点和描述子网络,模型本身不会修改,只是改成cpp版本,便于后续开发,不然ros的python2环境和现在各大网络的python3环境很烦;一个可用的版本在这里.
d)将SFM重建之后的元素分解整合成视觉定位所依赖的元素,譬如关键帧,特征点,描述子,3D点等等;
e)一个可以兼容传统特征和深度学习特征的重定位框架,之所以叫重定位,是因为基于b步骤的地图定位的,另外本质上确实也是重定位过程;
f)一个理论上可以融合imu, wheel encoder等其它传感器的融合思路或者说方案。之所以要是因为当你机器人走到了没有视觉地图的地方怎么办呢,对吧。
g)代码不一定开源,但会提供思路,会提供相关论文,这些应该只要追了近几年的论文很容易想到,也有很多论文是这么干的,我只是做了一点微小的工作。
玩视觉slam的小伙伴想必都跑过各种vo,vio,slam系统,至少下面的一款你肯定玩过的ORB-SLAM,SVO,DSO,VINS-Mono,MSCKF,Kimera等等。下面先简单总结一下历年来slam系统的对比,对比如下表
| 时间 | 方案名称 | 传感器 | 前端方法 | 后端方法 | 地图形式 | 融合方式 | 地图保存与复用 | 回环 | 是否开源 | 尺度 | 相对精度误差 | 绝对精度误差/m | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2003 | MonoSLAM | 单目 | 特征点 | EKF | 稀疏 | 无 | 否 | 无 | 是 | 无 | — | — | VO |
| 2007/2017 | PTAM/S-PTAM | 单目/双目 | 特征点 | 非线性优化 | 稀疏 | 无 | 否 | 无 | 是 | 无 | 1.19%(SPTAM) | — | VO |
| 2014 | SVO | 单目 | 半直接 | 非线性优化 | 稀疏 | 无 | 否 | 无 | 是 | 无 | 1.7%(EUROC) | VO | |
| 2014 | LSD SLAM | 单目 | 半直接 | 非线性优化 | 半稠密 | 无 | 无 | 有 | 是 | 无 | 1.2%(KITTI) | VO | |
| 2014 | RTAB MAP | 双目/RGB-D | 特征点 | 非线性优化 | 稠密 | 无 | 是 | 有 | 是 | 是 | 1.26%(KITTI) | VO(研究者相对少,相对商业) | |
| 2015 | ORB SLAM2 | 单目/双目/RGB-D | 特征点 | 非线性优化 | 稀疏 | 无 | 否 | 有 | 是 | 是(双目/RGB-D) | 1.15%(KITTI) | VO | |
| 2015 | ROVIO | 单目+IMU | 特征点 | EKF | 稀疏 | 紧耦合 | 否 | 无 | 是 | 是 | 0.15-0.6 | VIO | |
| 2015 | OKVIS | 双目+IMU | 特征点 | 非线性优化 | 稀疏 | 紧耦合 | 否 | 无 | 是 | 是 | 0.08-0.45 | VIO | |
| 2016 | DSO | 单目 | 直接法 | 非线性优化 | 半稠密 | 无 | 否 | 有 | 是 | 否 | 0.93%(S-DSO未开源) | VO | |
| 2016 | S-MSCKF | 双目+IMU | 特征点 | 非线性优化 | EKF | 紧耦合 | 否 | 无 | 是 | 是 | 暂无 | 0.1-0.45 | VIO |
| 2017 | VINS-Mono | 单目+IMU | 特征点 | 非线性优化 | 稀疏 | 紧耦合 | 是(无3D点云地图) | 有 | 是 | 是 | 0.05-0.24 | VIO 需要运动初始化 | |
| 2018 | ICE-BA | 单目+IMU | 特征点 | 非线性优化 | 稀疏 | 紧耦合 | 否 | 无 | 是 | 是 | 0.09-0.25 | 增量式后端优化 | |
| 2018 | VINS-Fusion | 双目/双目+IMU|GPS | 特征点 | 非线性优化 | 稀疏 | 紧耦合 | 是(无3D点云地图) | 有 | 是 | 是 | 1.09%(KITTI) | 0.12-0.63(KITTI) | 重定位需要初始化 |
| 2018 | R-VIO | 单目+IMU | 特征点 | EKF | 稀疏 | 紧耦合 | 否 | 无 | 是 | 是 | 暂无 | 0.1-1.0 | |
| 2019 | VINS-RGBD | RGBD+IMU | 特征点 | 非线性优化 | 稠密 | 紧耦合 | 是(无3D点云地图) | 有 | 是 | 是 | 暂无 | 暂无 | 非官方凯源,使用人数相对少 |
| 2019 | Kimera | 双目+IMU | 特征点 | 非线性优化 | mesh+语义 | 紧耦合 | 否 | 有 | 是 | 是 | 暂无 | 0.05-0.24 | 引入了语义地图 |
| 2019 | Larvio | 单目+IMU | 特征点 | EKF | 稀疏 | 紧耦合 | 否 | 否 | 是 | 是 | 暂无 | 0.06-0.25 | VIO |
ok 如果这些还不够,那么可以参考吴同学的 83 项开源视觉 SLAM 方案够你用了吗?,参考了那么多的slam系统之后,咱们来思考一下以下问题:
1)是否可以将表格中的一个或者某几个算法原理弄懂,在自己的相机,自己的项目场景中跑起来,修改一些参数适配自己的场景等等。
想必这个应该是最基础的,玩过的同学至少先能在数据集上跑通,跑通之后大多也都会买一个双目imu相机或者rgbd相机等等,用kalibr标定自己的相机,然后修改配置文件,不出意外的话,你拿着相机不断的动,相机的轨迹就会显示在屏幕上。ok,到这应该大家都是这么过来的。
2)有没有小改或者大改过一个开源项目,使得能更鲁棒,cover更多的corner case? 譬如老板给你提出的下面这些需求:
-
a)这个特征提取还是太慢了,我们把他挪到ARM下也得实时,你考虑加速一下?
-
b)场景运动太快了,特征跟踪不稳,系统老是崩掉,你能不能改稳定点?
-
c)为什么你这个图跟实际场景对不上,一条走廊为什么你来回轨迹都对不上,为什么人家激光雷达就可以?
-
d)能不能把imu和轮子还要多个相机给我加进去,到底能不能行?
-
e)你这玩意为什么每次坐标系都不一样,好像只在局部有用啊,能不能改一个存地图复用的版本,不然机器人每次导航点都不一样啊?
-
f)你这个怎么室内场景稍微变换了一下就不行了,到室外天气变化大点你这不完犊子?
可能上面的问题有点夸大,但是应该来讲是现实场景中会实实在在遇到的问题。总结来讲,这几个问题可以归结为,大多数slam系统不考虑地图的保存以及复用,试想现在的自动驾驶行业,应该很少有说离开了高精地图来做定位的吧,这里的高精度地图当然也包含激光雷达事先建立好的点云地图。反观到视觉其实也是一样的,如果要完成一个需要满足机器人任何时刻放置在场景中都输出同一个绝对坐标的任务时,譬如室内或者小区送货等等,如果说你事先都没有一张地图的话,那么上面提到的83项slam应该都是以每次启动的时候作为坐标系原点,那么问题来了,你能保证每次都在同一个位置?就算保证了,有一些slam系统还涉及到和imu的初始化,你能保证每次初始化都一样?
所以以上这些东西在实际应用中就会遇到各种奇奇怪怪的问题,而且视觉一般来讲会比激光问题更多一些。
综上,我们这里主要关注的问题在于怎么尽量让一个slam系统可以实际使用,以及结合DL的一些知识去提高系统的鲁棒性。参考2D激光SLAM,使用激光雷达的SMLAM方案,我们先建图,然后保存地图,然后实际使用的时候我们把地图加载进来,然后对单帧图像进行重定位,再然后融合其他信息譬如轮子和IMU和GPS来做融合定位,这样机器人的定位输出坐标系就是你事先建立的那张地图的坐标系了,所有东西都基于一个坐标系是十分nice的!那么到这里基于已知地图的视觉定位主要会包含以下内容:
-
a)如何构建这张视觉地图?
-
b)视觉地图主要包含什么元素?
-
c)采用基于特征点法还是直接法?
-
d)回环检测或者重定位(粗定位)采用传统词袋方法还是深度学习的图像检索方法?
-
e)怎么把重定位(全局定位的结果)和其他传感器融合起来?
-
f)目标检测,语义分割能怎么用在整个框架中?
-
g)基于已知地图的视觉定位能用来干什么?
基本上来讲文章是针对已知视觉地图的定位方法,端到端的算法当然也能做定位,但本文还是将视觉定位拆开几个部分来讲。首先会确定整个定位框架的脉络,其次从如何构建稀疏特征点视觉地图,地图都可以包含哪些有用的元素以及图像检索,局部定位等等方向来讲解,最后从当前热门计算机视觉的方向怎么集成或者说提取一些对定位信息有帮助的元素来提高定位精度。
开局一张图,剩下全靠编,那整体上来说就以这个图作为行文的框架。
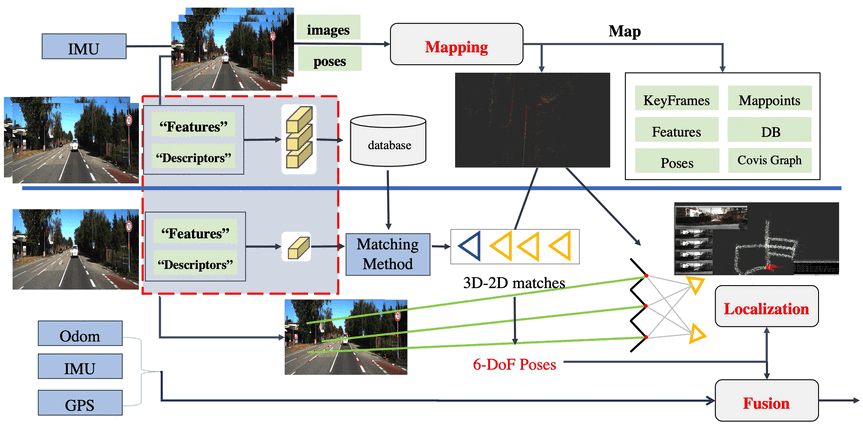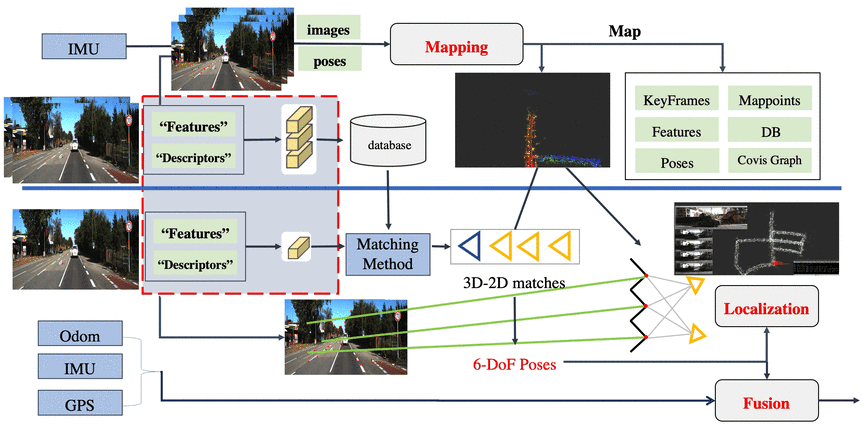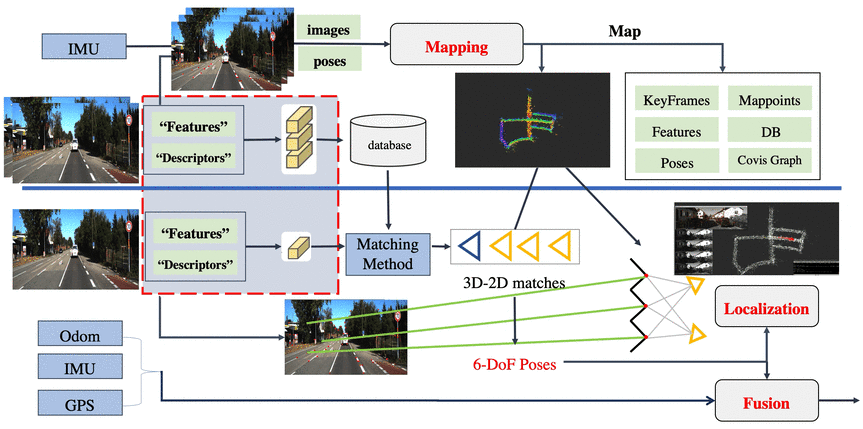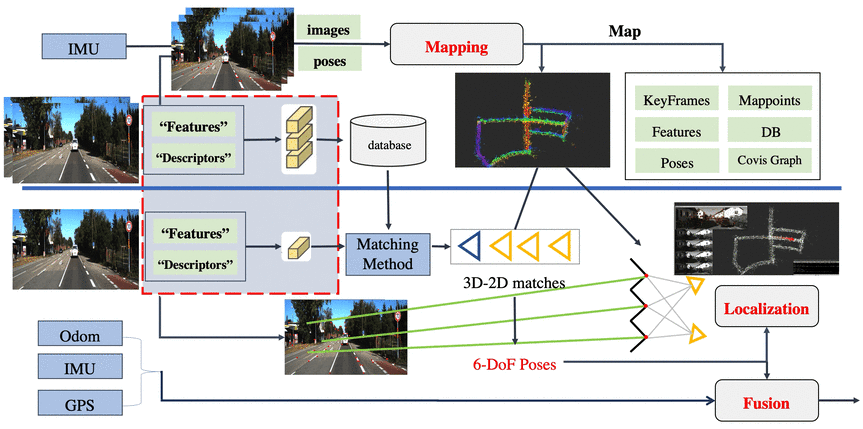
事实上,这里也已经很明显了,整体来看有三个大块:
- Mapping
- Localization
- Fusion
这里的每一大快都是一块非常大的话题,我们就从这张图来分析整个流程,首先看图的上半部分为建图, 这个框架在这里是离线的,其过程为一个已知图像关键帧6DOF pose的一个SFM过程,最后生成视觉地图所需要的元素。所以整理以下其实可以将步骤罗列在下面
- 1)以某种方式获得需要建图的图像和与之关联的pose.
a. Vicon运动捕捉系统获取相机的运动轨迹(室内)
b. 高精度激光雷达地图定位,且将激光雷达与相机同步间接获取相机位姿(室内外)
c. RTK + AHRS设备 间接获取
d. 各种SLAM系统run出来的值
e. 注意: 基于地图的定位其定位结果是与地图一致的,所以根据自己的任务选择自己的坐标系
当成功获取到图像的时候,因为这里以稀疏特征点为例,所以必不可少的需要提取某种特征作为你的建图基础,这种特征一般来讲跟你的使用需求有关,你可以选择自己喜欢的特征点和描述子.
- 2)选择适合自己使用场景的特征点和特征描述子,理论上来讲文章提到的框架都支持下面的特征.
- SIFT
- ORB
- Hardnet
- HardnetAmos
- GeoDesc
- SOSNet
- L2Net
- Log-polar descriptor
- Superpoint
- D2-Net
- DELF
- Contextdesc
- LFNet
- R2D2
- ASLFeat
- ...
当有了图像,有了图像的pose之后,剩下的过程便是建图,建图又可分为在线建图和离线建图,在线建图可以使用文章开篇提到的各种slam方法,我们这里主要注重离线建图,为什么要离线建图呢?离线建图有它的优势,最终要的是获取到的图像和pose是可以人为控制的,也就意味着在精度方面有一个基本保障,这也是大多数基于激光雷达定位方法的方式,只不过地图换成了视觉地图。离线建图即恢复出2D特征点的3D位置,最小化到一个三角化算法的过程,最后整体做BA,关于三角化原理可以参考我之前写的博客.
- 3)根据图像,图像pose,图像特征点和描述子稀疏重建场景.
a)自己写的一个简单三角化DEMO.
b) 借助开源的SFM建图工具. 简单列举开源工具如下,大家也可以去网上找详细的对比.
VisualSFM: A Visual Structure from Motion System
Meshlab: the open source system for processing and editing 3D triangular meshes.
Colmap: a general-purpose Structure-from-Motion (SfM) and Multi-View Stereo (MVS) pipeline with a graphical and command-line interface.
Bundler: Structure from Motion (SfM) for Unordered Image Collections
CMVS: Clustering Views for Multi-view Stereo
MVE: a complete end-to-end pipeline for image-based geometry reconstruction.
MVS-Texturing: 3D Reconstruction Texturing
OpenMVG: open Multiple View Geometry
OpenMVS: open Multi-View Stereo reconstruction library
Pix4D: A unique photogrammetry software suite for drone mapping
mavmap: Structure-from-motion for MAV image sequence analysis with photogrammetric applications
TheiaSfM:Theia is an end-to-end structure-from-motion library
...
到目前位置还有一个疑问是,有些开源工具仅仅支持自己的特征,大部分是SIFT,这里不得不说SIFT的牛逼,所以在选择开源工具时需要考虑是否支持外部特征,是否支持自己的特征点匹配方式等等,这里假设提供这么多方式都解决了以上问题,根据流程我们可以得到如下稀疏的三维特征点地图如下:
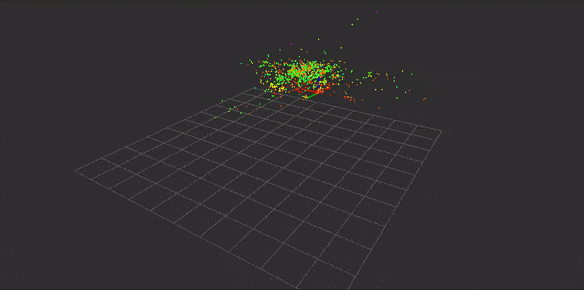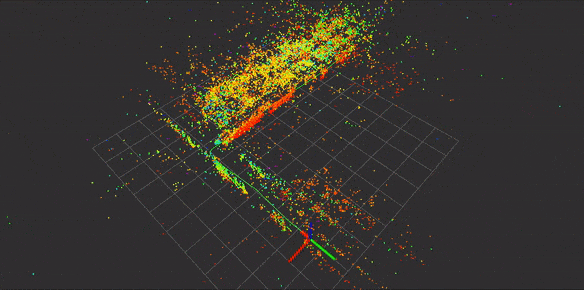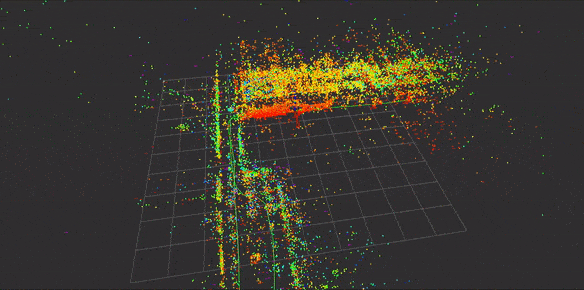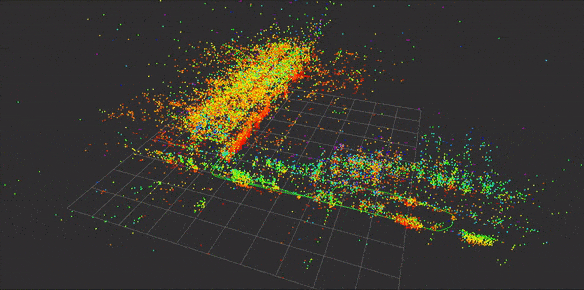
请注意,上图是根据已知pose进行重建,对重建之后的地图加载效果图,而非实时过程。
建图的主要目标是构建一个描述周围环境的模型。生成的图具有多方面的作用:1)可以为使用者提供能够理解的地图参考,2)为机器人任务提供环境信息,如导航规划等 3)限制里程计的误差发散 4)作为先验模型为全局定位提供参考。这里参考了一个survey.
所谓的视觉地图可以分为很多种类,根据模型的输出以及地图的表达元素,可以将地图分为:几何建图(Geometric Mapping),语义建图(Semantic Mapping)和广义建图(General Mapping),几何建图主要提取场景的形状和结构描述。用于场景表达的普遍选择包括深度(2.5D)、体素(Voxel)、点(Point)和网络(Mesh), 语义建图则更加注重对环境的理解,如物体的类别,等等,这是一个比较高层次的地图,而语义地图又可以使用语义分割(Semantic Segmentation)、实例分割(Instance Segmentation)和全景分割(Panoptic Segmentation)来进行语义建图。当然在深度学习的极力推动下,也有一些更高层次的地图表达方式,类似于拓扑地图一样可以称作为广义地图,可以将地图搞成(Autoencoder)压缩场景、神经渲染模型(Neural rendering model)以及任务驱动的地图(Task-driven map)。
就这个项目来讲,我们重点关注几何地图中的稀疏点特征地图,以ORB-SLAM2为例子,我们来看一下如果一张稀疏特征点视觉地图如果用于定位,它需要哪些元素。
在ORB-SLAM2的System.h文件中,有这样一句话:
// TODO: Save/Load functions.其目的是让读者自己实现地图的保存与加载功能,事实上这也是大多数SLAM/VO/VIO系统的问题,你想保存地图?那是不可能的。这个保存地图其实在16年就已经有人写出来了,并且我们当时也使用过,现在github上也有很多版本,这里给大家推荐两个版本:
言归正传,我们来看一下作为一个通用的稀疏特征点视觉地图,它包含哪些元素:
- 关键帧,包含关键帧的数目,当前关键帧的ID,父节点的ID,关键帧的生长树,关键帧的位姿,关键帧特征点位置,描述子,对应与3D地图点的索引ID,BOW向量等等元素
- 3D地图点,地图点的数目,地图点的位置,地图点的其他信息(譬如语义等)
- 关键帧与3D地图点的对应关系,也就是刚刚上面说到的对应索引。
假设保存了这些元素之后,我们试想来了新的一帧之后,怎么去重定位出当前帧的位姿,首先对新来的帧提取局部特征点和局部描述子,然后根据局部特征计算出BOW向量,用当前帧BOW向量计算出与地图中最接近的关键帧(visual place recognition),这时候会有候选帧,事实上如果场景变化不大,那么你已经做出了一个精度为m级别的粗略定位了,因为关键帧是保存了位姿的,所以候选关键帧和当前帧的几何信息是接近的,故它两的pose也会很接近。其次最粗暴的方法就是与最像的关键帧先做2D-2D的特征匹配,然后关键帧的特征点有些是带有3D地图点的,所以一系列的outlier剔除之后你可以得到一群2D-3D的匹配,然后粗暴的PnP方法就可以计算出当前帧的位姿。总结其过程主要有两个步骤:
- 1:粗定位/图像重识别/图像检索,根据几何信息判断出最相似的场景。
- 2.精定位/PnP/BA,根据2D-3D匹配恢复出相机位姿。
所以我们可以将地图元素像这样存放,当然你也可以根据自己的喜好序列化成自己的格式。
map
├── config
├── global_desc
├── keyframes
├── kpts_desc
├── map_info.bin
├── mappoints
└── voc_db粗定位很好理解,又可以理解为回环检测的第一步,试图寻找当前帧与历史帧最像的候选帧,然后进行粗定位,方法又很多种,这里将其分为传统方法和基于深度学习的方法。由于当前输入数据和已知地图(在使用之前就建立好的)之间的视图、照明、天气和场景动态等因素变化,导致这一数据关联问题变得尤其复杂。在这里,我们只针对常用的方法进行讲解,具体使用要case by case. 下图表示了图像检索的样例:


传统方法来讲,这里讲最经典最经典的几个方法:
- [VLAD] - https://github.com/jorjasso/VLAD
- [DBoW2] - https://github.com/dorian3d/DBoW2
- [libhaloc]- https://github.com/srv/libhaloc
- [HBST] - https://gitlab.com/srrg-software/srrg_hbst
- [iBow] - https://github.com/emiliofidalgo/ibow-lcd
- ...
无论以何种方式实现,其输入是一张图,输出是database中的query对象。
当然以神经网络对图像的强大表达能力,近些年深度学习的方法比较流行,核心思路应该理解为对图像提取特征,这种特征能够描述这个场景,相似场景特征之间的距离要近,不同场景对应的特征向量的距离应该尽量远,这样才有区分度,这里也列举近些年一些基于深度学习的算法。
- [NetVLAD] - https://github.com/Relja/netvlad
- [DIR] - https://github.com/almazan/deep-image-retrieval
- [GeM,DAME] - https://github.com/scape-research/DAME-WEB
- [DELF] - https://github.com/tensorflow/models/tree/master/research/delf
- [HF-NET] - https://github.com/ethz-asl/hfnet
- [UR2KID] - https://arxiv.org/abs/2001.07252
- ...
上述DL的方法基本上输入是图像,输出是一个N(1024/2048/4096...)维度的向量,即描述子。如果两张图很接近,那么其描述子之间的距离会比较接近,反之则比较距离较远,另外近年也有与语义信息结合的工作,但目前(2020.09)还没有看到比较好的开源工作。
这里推荐一个CVPR2017的一个Tutorial,需科学上网:
Tutorial : Large-Scale Visual Place Recognition and Image-Based Localization Part 1
Tutorial : Large-Scale Visual Place Recognition and Image-Based Localization Part 2
如果说像把上面的工作集成到自己的SLAM系统或者框架中,一般还需要考虑实时性以及是否需要模型加速或者说转换成C++的问题,可以从NetVLAD入手,譬如大佬们把它修改成了tensorflow版本的netvlat_tf. 当然针对上面的hfnet工作我也简单对hfnet改了一个hfnet_ros,提供了docker配置,如果有兴趣可以玩一下. 网络实际输出三个东西,但这里只显示特征点如下:

总结性的来讲,精定位无非干一件事情,想尽一切办法找到可靠的3D-2D的匹配对。我们将精定位部分分为三个大部分,特征点和描述子的选择,特征点之间的匹配以及位姿恢复。
 |
 |
首先来看特征点和描述子之间的选择,其实从SIFT开始,各种个样的hand-craft描述子和特征点不断兴起,大多是在保证精度的同时加快特征点和描述子的提取速度,这些方法也都大多被集成到opencv中,调用起来也很方便,另外近些年基于DL的特征提取方法不断兴起,也涌现了很多优秀的特征提取和描述子算法,它们的出现也都集中在解决精度,尺度变化大,运动模糊,光照变化大,旋转变化大,环境变化大等等还能保证精度的问题。
这里推荐CVPR2020的一个Workshop,CVPR2020: Image Matching Workshop. 内容还是比较硬核的,讲述了图像特征点和匹配的一些方法,大家可以仔细观看视频并学习。
特征点选择和匹配包括姿态恢复部分其实都有很多工程技巧,另外因为这个我觉得从特征点入门slam的同学来讲也并不陌生,所以就不那么多废话,因为每年都会涌现十分多非常优秀的特征点算法以及特征点描述子,同时还有一些匹配算法,以及一些端到端的匹配,姿态恢复算法等等,这些都是参考;从工程角度来讲,我希望定义好输入输出,输入就是未匹配好的特征点及其对应的描述子,当然有些可能要输入图像,输出则是匹配好的2D特征点对,其中算法你可以换成开源的其他任意算法,至于怎么选择,这里提供了Google出品的一篇论文Image Matching Across Wide Baselines: From Paper to Practice的结果:

对于传统算法,github上又一个不错的项目,对opencv中支持的各大detector和descriptor以及matching method都做了对比测试,包括特征提取匹配的耗时等等,不过看命名像是Udacity的课程,其github项目名称为 SFND_2D_Feature_Tracking
对于DL方法,我在第二章提到的,大家都可以去对于的github上去做测试。
- Hardnet
- HardnetAmos
- GeoDesc
- SOSNet
- L2Net
- Log-polar descriptor
- Superpoint
- D2-Net
- DELF
- Contextdesc
- LFNet
- R2D2
- ASLFeat
到目前位置,我们选择了一套精定位的方法,同时我们也选择了用于粗定位的方法即特征点和描述子,当然特征匹配这一块是一个单独的问题,其实有很多特征点的匹配方法,但常规来讲,我们一般来讲常用的有暴力匹配和knn-based匹配,另外一些cross-check等等以及一些加速匹配的方法都可以用上,只要记住整个系统的输入输出即可。之后便是PnP求解问题,或者可以推广到BA问题,假设前期工作做的好,那基本上来讲直接PnP的精度也不会太差。
实质上,如果说到这里你还不明白为什么要花那么多时间讲挑选特征点,建图,定位,等等,都是有道理的,在这里我也想在声明一下大家都说自己是做SLAM的,其实本质上有可能是不一样的,不过大同小异,侧重点不一样,从我的角度来讲,定位是定位,建图是建图,SLAM(同时定位建图是同时定位与建图):
- 相对定位问题:
我理解的相对定位问题是不需要知道绝对坐标系的,而且是可以理解为可以传感器每次上电的位置不同,同一个地方的定位位置也不相同,典型的结果如轮速计,各大VIO等等 - 绝对定位问题:
这个跟相对地位不一样,可以理解为定位结果每次都是在同一个坐标系下的,譬如不需要事先建地图的差分GPS,或者说需要事先建立用于定位的高精度地图,譬如ORB-SLAM2的地图保存,譬如自动驾驶常常说的高精度地图等等。总的来说定位问题输出的是机器人位姿的最大似然估计。 - 建图问题:
建图问题又分为有pose和无pose的情况,但总而言之输出的是地图的最大似然估计,像本项目的做法就是用比较准确的pose去做地图恢复问题。 - SLAM问题:
可以理解为,事先什么都是不知道的,包括pose和map,知道的只有传感器的信息,根据传感器的信息推断出pose和map的信息。
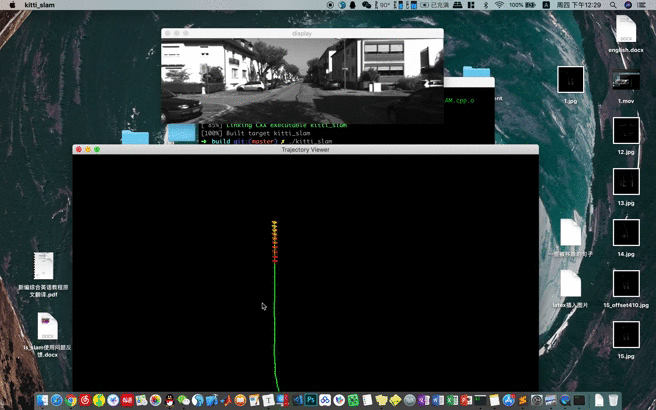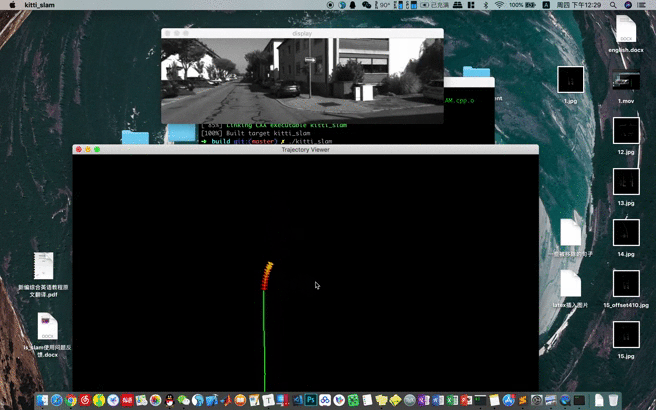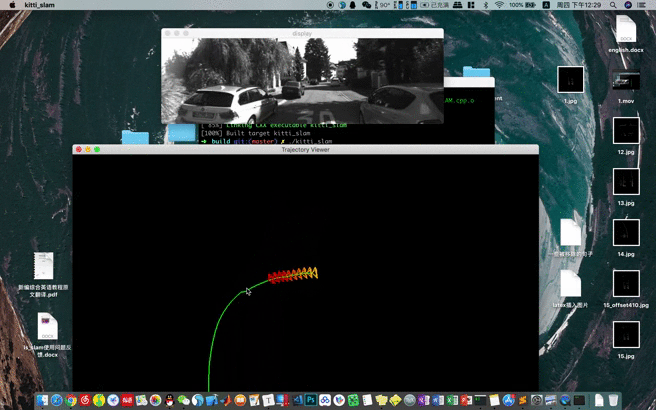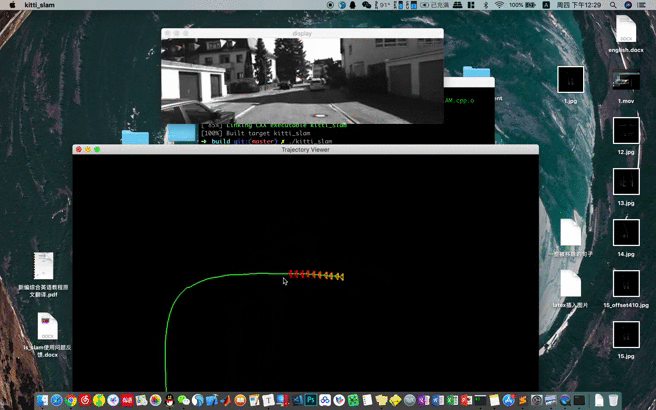
首先我们来看一个之前说的框架加载地图到单张图像重定位的一个效果,视频地址在Youtube,其次我们再回顾一下各个步骤都干了些什么事情。

- 获取图像以及姿态
- 构建视觉地图
- 加载地图
- 视觉重定位
DH3D: Deep Hierarchical 3D Descriptors for Robust Large-Scale 6DOF Relocalization
Loop Closure Detection through saliency re-identification IROS 2020
Image Matching Across Wide Baselines: From Paper to Practice
[ECCV 2020] Learning Feature Descriptors using Camera Pose Supervision