Sorting algorithms visualized using the Blender Python API.
Running one of the scripts in this project generates primitive meshes in Blender, wich are animated to visualize various sorting algorithms.
Keyframes are incrementaly inserted according to the current position of the element in the array during the sorting.
The four folders (sort_circle, sort_color, sort_combined, sort_scale) contain four different types of visualization.
| Type | Sorting Criteria | Representation of Index | Extras |
|---|---|---|---|
| sort_circle | hsv of material | rotation of cuboid | hsv = 360° |
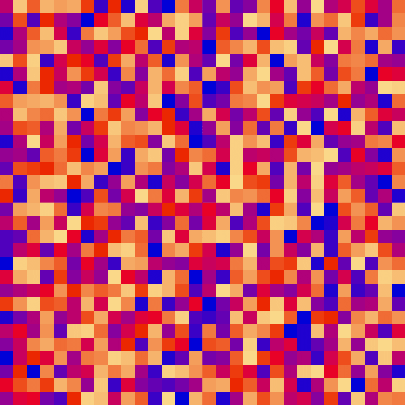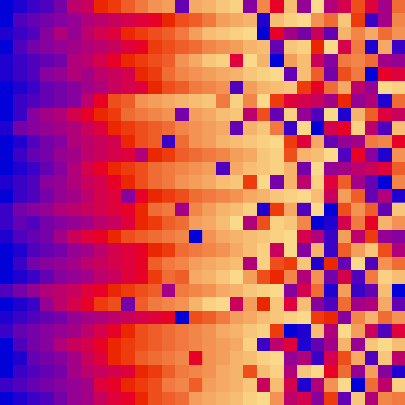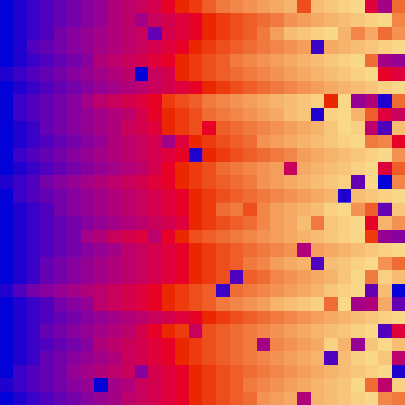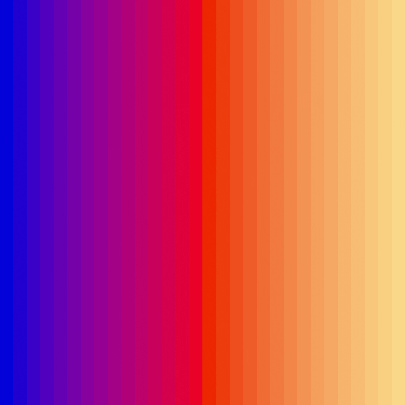
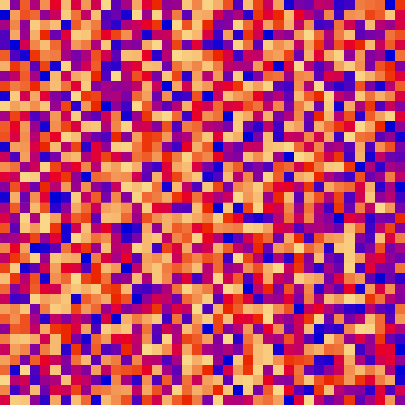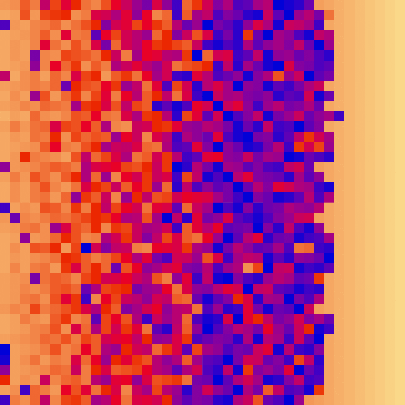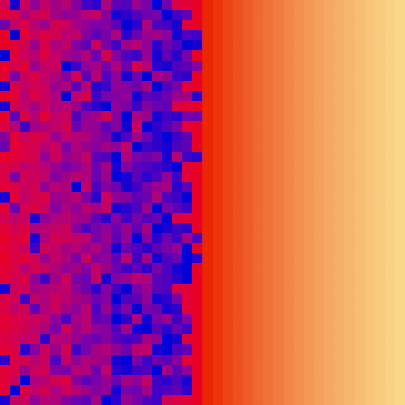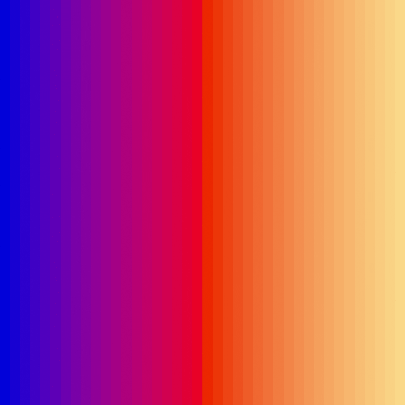
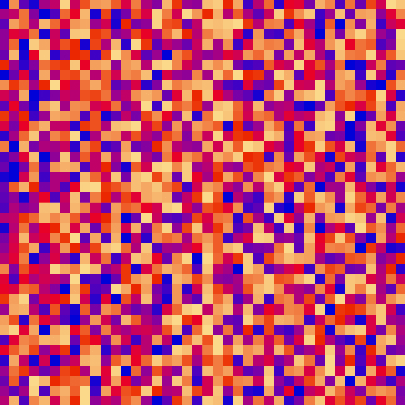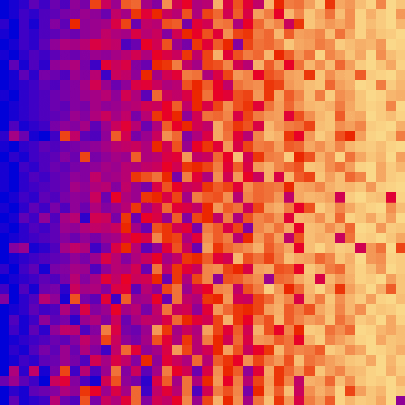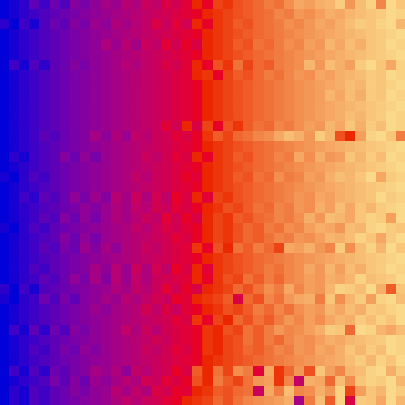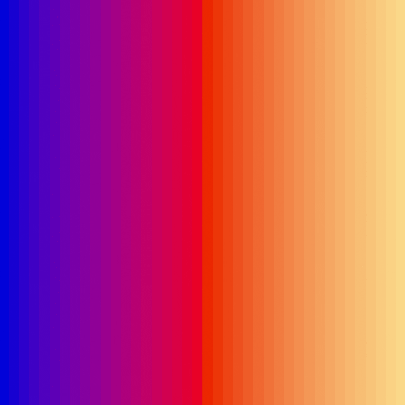
| sort_color | red + green of material | location of plane | custom color gradient |
| sort_combined | red + green of material | location of plane | multiple 2d arrays arranged into a cube |
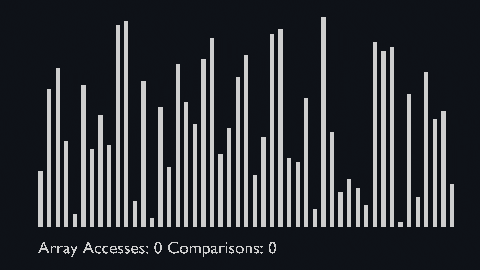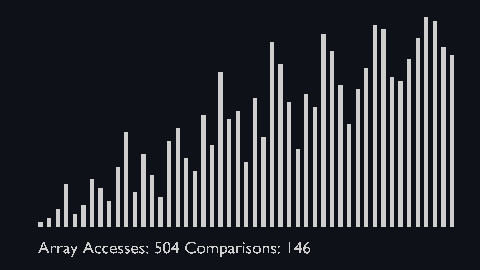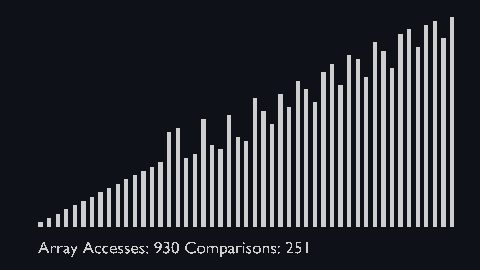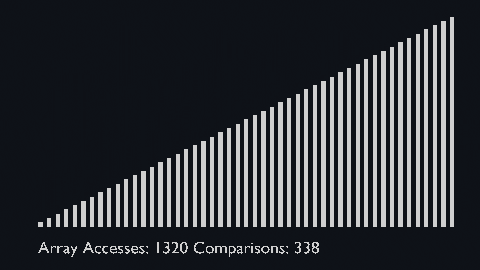
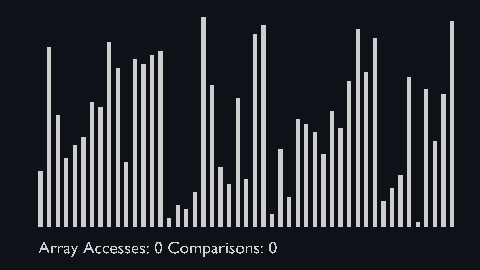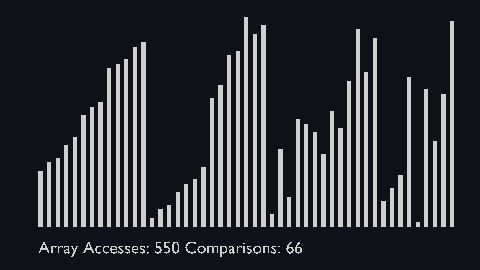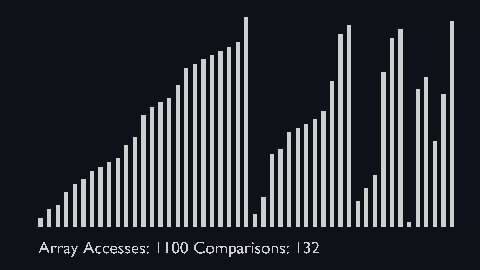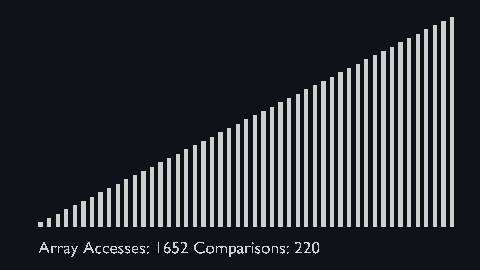
| sort_scale | scale of cubiod | location of cuboid | array access and comparison counter |
- Download, install and start Blender.
- Open the .py file in the Text Editor.
- Click the play button to run the script.
These visualizations don't show the efficiency of the algorithms.
They only visualize movement of the elements within the array.
But the array access and comparison counters are indicators of the time complexity of the algorithms.
For more information about the time complexity, you can take a look at the Big O Table.
Below I compiled a list of features that could be implemented in the future.
- increase efficiency of the setup_array() function, to allow greater object count
- adding audio "Audibilization"
- adding more sorting algorithms
- adding more types of visualization e.g. Sphere Agitation, Cube Amalgam, Dynamic Hoops
- auto generate camera with correct transforms based on the count of sorted objects
- create panel were you can choose different options like colors, sorting algorithms and count of objects
- improve merge sort visualization so there are no gaps and overlapping objects
Contributions to this project with either ideas from the list or your own are welcome.
Bubble sort is one of the most straightforward sorting algorithms, it makes multiple passes through a list.
- Starting with the first element, compare the current element with the next element of the array.
- If the current element is greater than the next element of the array, swap them.
- If the current element is less than the next element, move to the next element.
| bubble_sort_scale.py | bubble_sort_color.py | bubble_sort_circle.py |
|---|---|---|
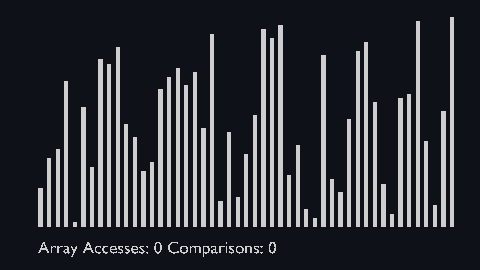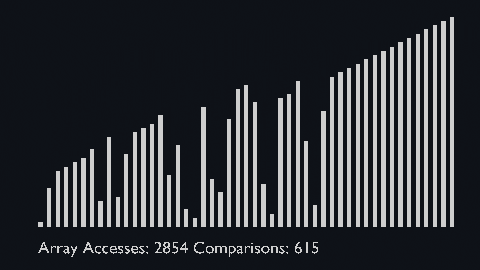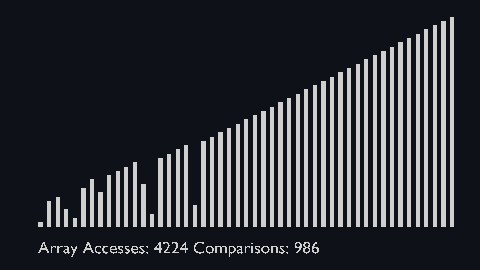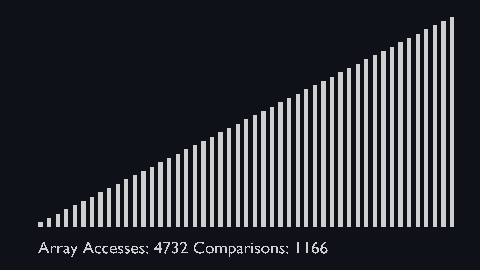 |
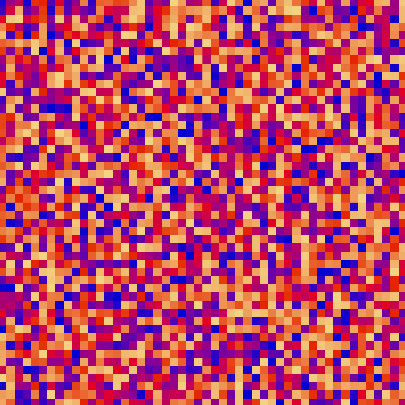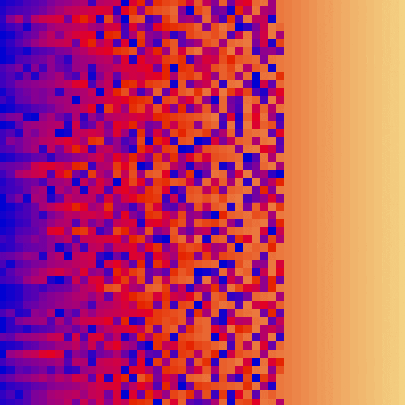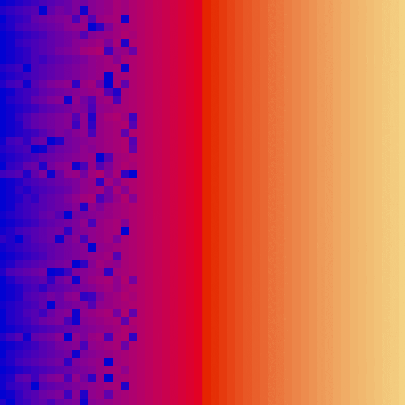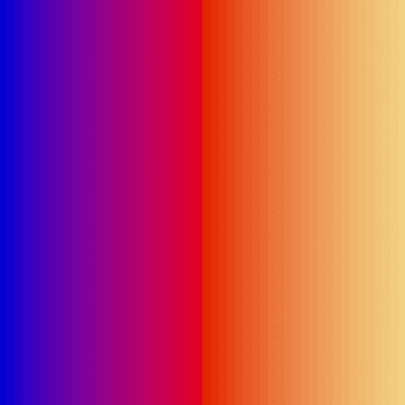 |
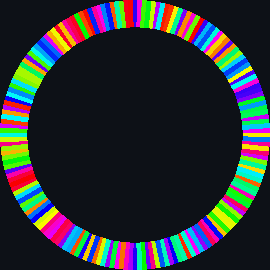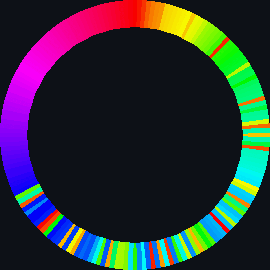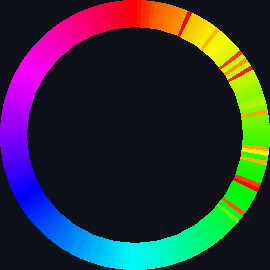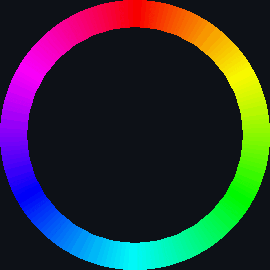 |
Like bubble sort, the insertion sort algorithm is straightforward to implement and understand.
- Iterate from arr[1] to arr[n] over the array.
- Compare the current element (key) to its predecessor.
- If the key element is smaller than its predecessor, compare its elements before.
- Move the greater elements one position up to make space for the swapped element.
| insertion_sort_scale.py | insertion_sort_color.py |
|---|---|
 |
 |
The algorithm maintains two subarrays in a given array.
- The subarray which is already sorted.
- Remaining subarray which is unsorted.
In every iteration of selection sort, the minimum element (considering ascending order) from the unsorted subarray is picked and moved to the sorted subarray.
| selection_sort_scale.py | selection_sort_color.py | selection_sort_circle.py |
|---|---|---|
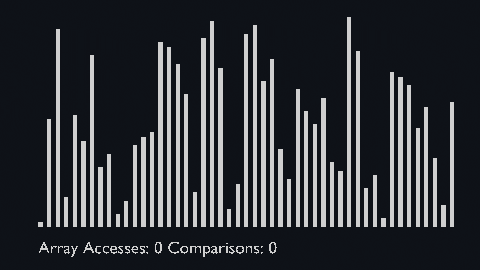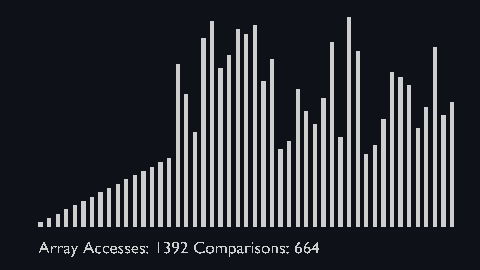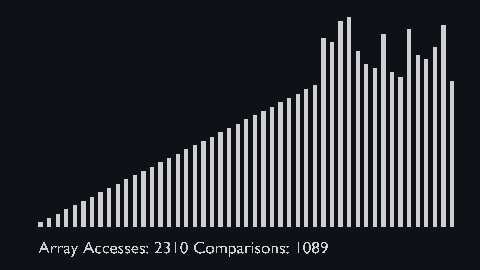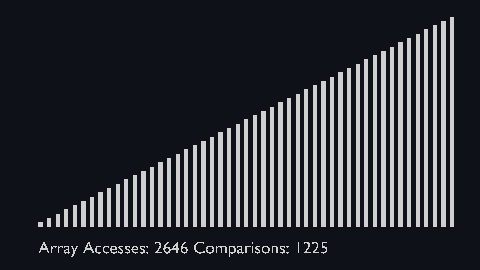 |
 |
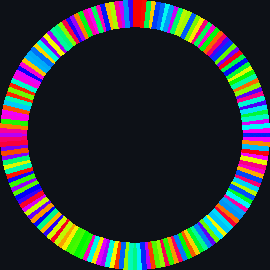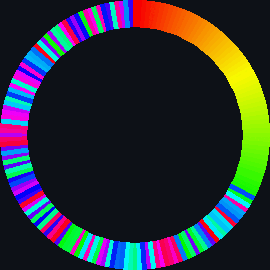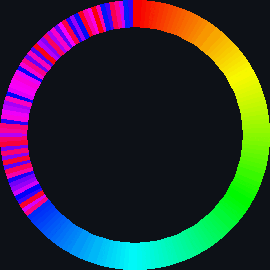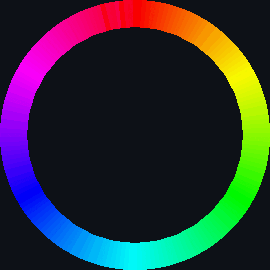 |
Based on the binary heap data structure, heap sort is mainly considered as a comparison-based sorting algorithm.
In this sorting technique, at first, the minimum element is found out and then the minimum element gets placed at its right position at the beginning of the array.
For the rest of the elements, the same process gets repeated.
So, we can say that heap sort is quite similar to the selection sort technique.
Heap sort basically recursively performs two main operations:
- Build a heap H, using the elements of array.
- Repeatedly delete the root element of the heap formed in 1st phase.
| heap_sort_scale.py | heap_sort_color.py |
|---|---|
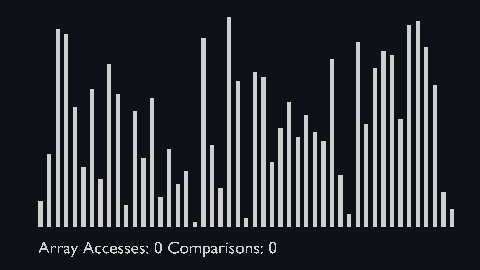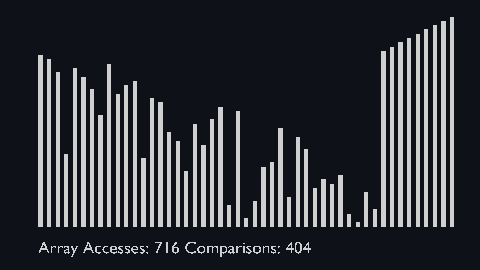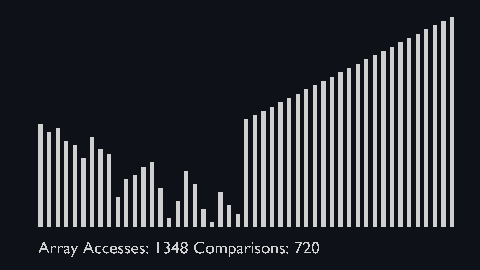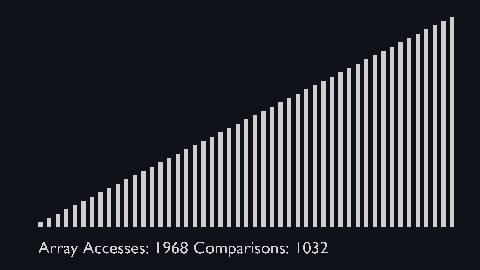 |
 |
The shell sort algorithm extends the insertion sort algorithm and is very efficient in sorting widely unsorted arrays.
The array is divided into sub-arrays and then insertion sort is applied.
The algorithm is:
- Calculate the value of the gap.
- Divide the array into these sub-arrays.
- Apply the insertion sort.
- Repeat this process until the complete list is sorted.
The gap is known as the interval. We can calculate this gap/interval with the help of Knuth’s formula.
| shell_sort_scale.py | shell_sort_color.py |
|---|---|
 |
 |
Merge sort uses the divide and conquer approach to sort the elements.
It is one of the most popular and efficient sorting algorithms.
The sub-lists are divided again and again into halves until the list cannot be divided further.
Then we combine the pair of one element lists into two-element lists, sorting them in the process.
The sorted two-element pairs is merged into the four-element lists, and so on until we get the sorted list.
| merge_sort_scale.py | merge_sort_color.py | merge_sort_circle.py |
|---|---|---|
 |
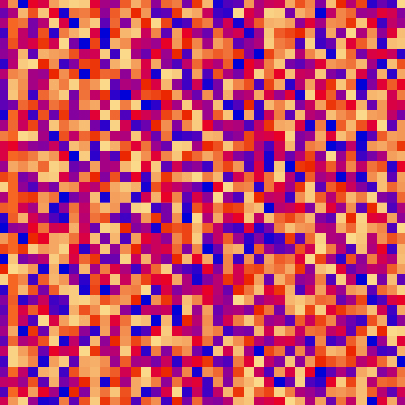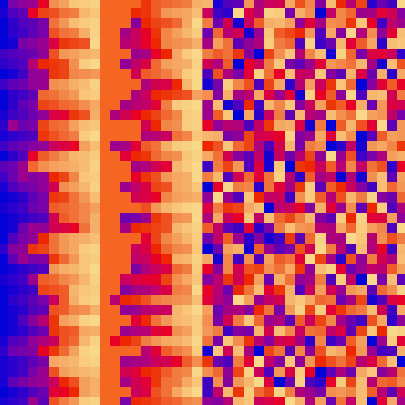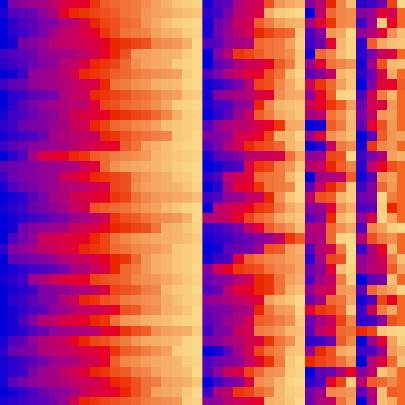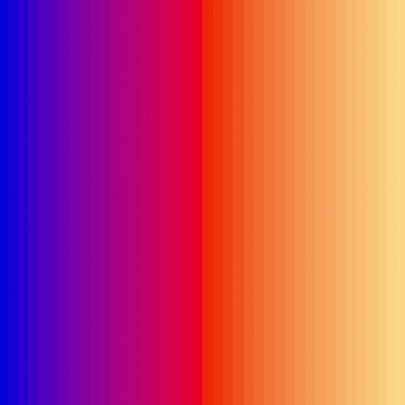 |
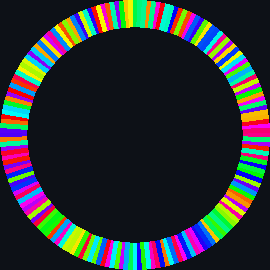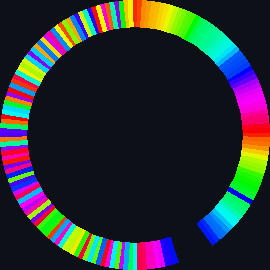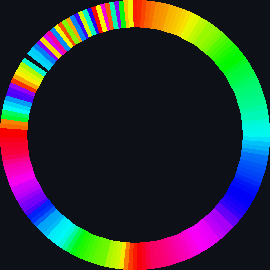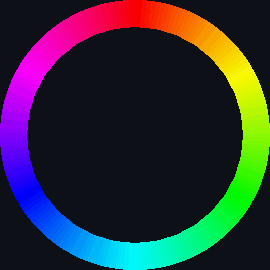 |
Like Merge Sort, Quick Sort is a Divide and Conquer algorithm. It picks an element as pivot and partitions the given array around the picked pivot. There are many different versions of Quick Sort that pick pivot in different ways.
- Always pick first element as pivot.
- Always pick last element as pivot.
- Pick a random element as pivot.
- Pick median as pivot. (implemented below)
The key process in quickSort is partition(). Target of partitions is, given an array and an element x of array as pivot, put x at its correct position in sorted array and put all smaller elements (smaller than x) before x, and put all greater elements (greater than x) after x.
All this should be done in linear time.
| quick_sort_scale.py | quick_sort_color.py | quick_sort_circle.py |
|---|---|---|
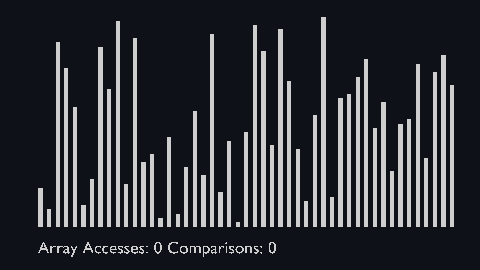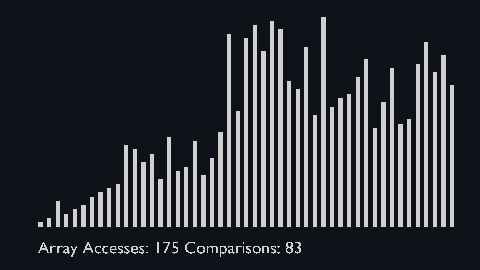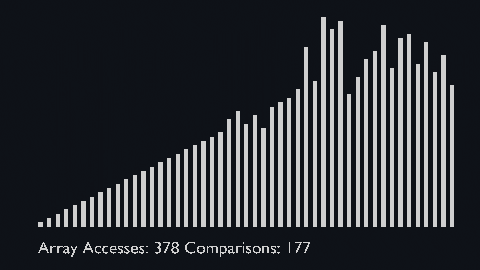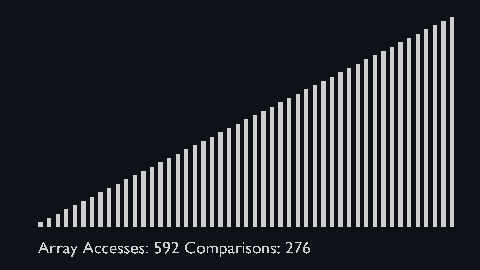 |
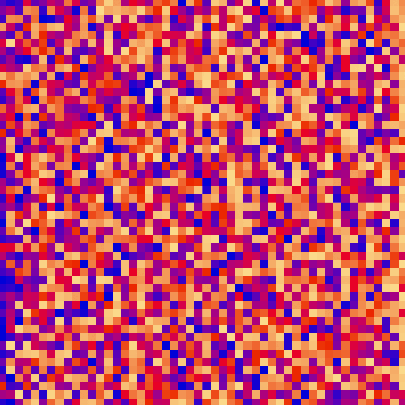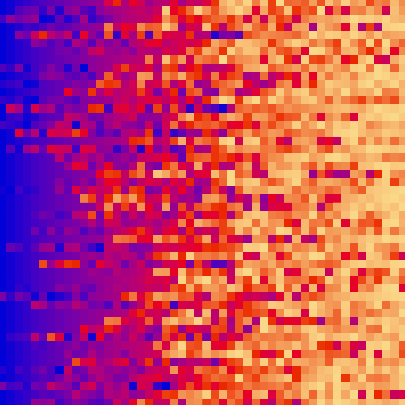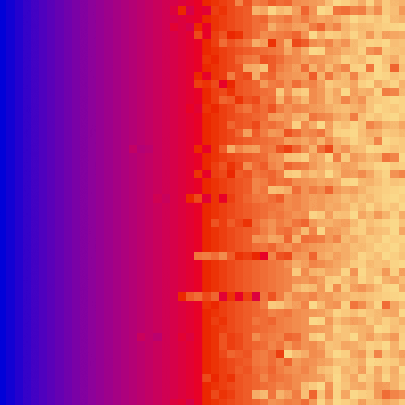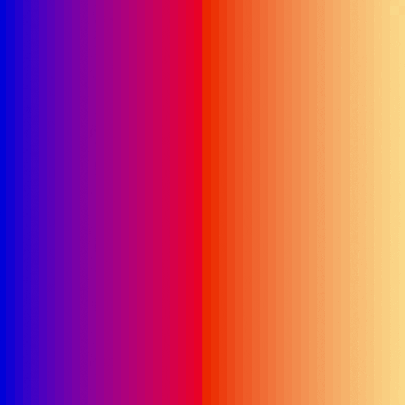 |
 |
Big O notation is the language we use for talking about how long an algorithm takes to run.
It's how we compare the efficiency of different approaches to a problem.
With Big O notation we express the runtime in terms of how quickly it grows relative to the input, as the input gets arbitrarily large.
Let's break that down:
- how quickly the runtime grows
It's hard to pin down the exact runtime of an algorithm.
It depends on the speed of the processor, what else the computer is running, etc. So instead of talking about the runtime directly, we use big O notation to talk about how quickly the runtime grows. - relative to the input
If we were measuring our runtime directly, we could express our speed in seconds.
Since we're measuring how quickly our runtime grows, we need to express our speed in terms of...something else.
With Big O notation, we use the size of the input, which we call "n".
So we can say things like the runtime grows "on the order of the size of the input" (O(n)) or "on the order of the square of the size of the input" (O(n^2)). - as the input gets arbitrarily
Our algorithm may have steps that seem expensive when "n" is small but are eclipsed eventually by other steps as "n" gets huge.
For big O analysis, we care most about the stuff that grows fastest as the input grows, because everything else is quickly eclipsed as "n" gets very large.
These are the asymptotic notations that are used for calculating the time complexity of the sorting algorithms:
- Big O Notation, O:
- Omega Notation, Ω:
- Theta Notation, θ:
It measures the upper limit of an algorithm's running time or the worst-case time complexity. It is known by O(n) for input size 'n'.
It measures the minimum time taken by algorithms to execute, and calculates the best case time complexity in sorting. It is known by Ω(n) for input size 'n'.
It measures the average time taken by an algorithm to execute. Or, the lower bound and upper bound of an algorithm's running time. It is known by θ(n) for input size 'n'.
In applications such as in radix sort, a bound on the maximum key value "k" will be known in advance, and can be assumed to be part of the input to the algorithm.
However, if the value of "k" is not already known then it may be computed, as a first step, by an additional loop over the data to determine the maximum key value.
| Algorithm | Time Complexity | Space Complexity | ||
|---|---|---|---|---|
| Best Case | Average Case | Worst Case | Worst Case | |
| Quick Sort | Ω(n log(n)) |
Θ(n log(n)) |
O(n^2) |
O(log(n)) |
| Merge Sort | Ω(n log(n)) |
Θ(n log(n)) |
O(n log(n)) |
O(n) |
| Tim Sort | Ω(n) |
Θ(n log(n)) |
O(n log(n)) |
O(n) |
| Heap Sort | Ω(n log(n)) |
Θ(n log(n)) |
O(n log(n)) |
O(1) |
| Bubble Sort | Ω(n) |
Θ(n^2) |
O(n^2) |
O(1) |
| Insertion Sort | Ω(n) |
Θ(n^2) |
O(n^2) |
O(1) |
| Selection Sort | Ω(n^2) |
Θ(n^2) |
O(n^2) |
O(1) |
| Tree Sort | Ω(n log(n)) |
Θ(n log(n)) |
O(n^2) |
O(n) |
| Shell Sort | Ω(n log(n)) |
Θ(n(log(n))^2) |
O(n(log(n))^2) |
O(1) |
| Bucket Sort | Ω(n+k) |
Θ(n+k) |
O(n^2) |
O(n) |
| Radix Sort | Ω(nk) |
Θ(nk) |
O(nk) |
O(n+k) |
| Counting Sort | Ω(n+k) |
Θ(n+k) |
O(n+k) |
O(k) |
| Cube Sort | Ω(n) |
Θ(n log(n)) |
O(n log(n)) |
O(n) |