This is an image recognition framework based on tflearn (tensorflow-learn) and GoogLeNet image recognition model. And a minimum Flask app to demo your training result.
-
Arrange your own data set in
images/<DATASET_NAME>/<LABEL_NAME>as following example. You could usepython3 dump_17flowers.pyto download the example dataset 17 Category Flower Dataset from Oxford university, which you could find the data hierarchy like this:images | |---17flowers | |--- jpg | |--- 0 (folder containing all label=0 samples) | | | |----image_0001.jpg (label=0 sample) | |----image_0002.jpg (label=0 sample) | |----image_0003.jpg (label=0 sample) | ... | |--- 1 (folder containing all label=1 samples) |--- 2 (folder containing all label=2 samples) |--- 3 (folder containing all label=3 samples) ... |--- 15 |--- 16 Each folder (0 to 16) contains samples of one label in dataset. -
Then could start the training like the following example, which trains the 17flowers model, which we have 17 labels in this dataset.
python3 train.py --model_name 17flowers --label_size 17
The latest models will be saved in models/<DATASET_NAME>. If training process is interrupted, it will find and restore the latest trained model from this folder.
After you are satisfied with the training result, you could try to predicting by the Flask server.
python3 app.py --model_name 17flowers --label_size 17
Then open your browser, go http://localhost:8883. Fill in the new picture you want to classify and submit, you will get prediction result like this:
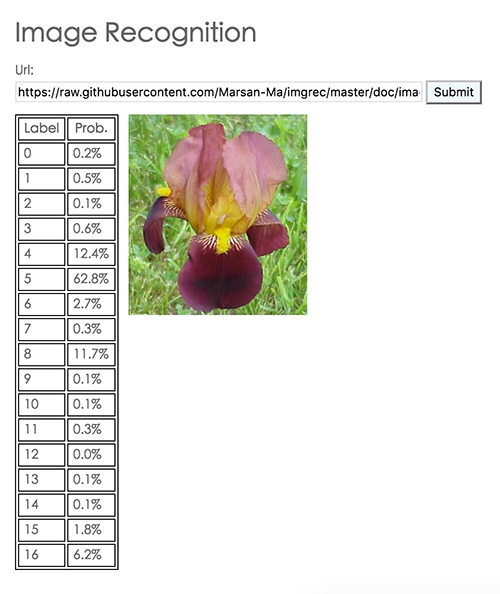
Here is a picture of flower from 17flowers data in label 5. The predicted result has 62.8% confidence that it's label 5, which is a correct prediction.
The image recognition network have fixed input size. here we resize any input picture to 227x227 pixels internally, so you could use picture in any size both in training and testing.
In the original tflearn example, all the samples are loaded to memory in single batch. But in real world cases, most of time we can't afford for super large ram to train a tera-byte scale image-recognition application.
Fortunately, we don't need to. The Convolution neural network, like most of neural network models, are trained in online learning optimizers like SGD, Adam, FTRL...etc. They actually only process 1 sample at a time, then we could discard it and load another.
In this repository I've modified the data_util.py that it will resize the original images and cache them into pickle files, each with 500 images only. And in the training procedure it will load 500 images to do a mini-batch at a time, then discard them and load another mini-batch. So, no matter how large your original sample volumn, this make sure your machine could work.
For your own dataset, be sure to modify these two arguments for both train.py and app.py.
-
model_name: this is your dataset name, and it shall be consist with your dataset path inimages/<model_name>, and the model will be generated inmodels/<model_name>accordingly. -
label_size: for example, in the 17 flowers datasets there are 17 kinds of different flowers to classify, thus thelabel_size = 17. You should modify this number according to your application.
Here we wrap up the GoogLeNet as a class in lib/googlenet.py. It will automatically find your latest trained model in model/<YOUR_PROJECT_NAME> as you instance an object of it.
Besides the network, there are following functions attached to it:
fit: do the trainingpredict: do the predictingget_data: fetch all data cache names of certain dataset
It's pretty simple, let's go through train.py.
scope_name, label_size = '17flowers', 17
Since the 17 flowers dataset got 17 labels.
gnet = GoogLeNet(img_size=227, label_size=label_size, gpu_memory_fraction=0.4, scope_name=scope_name)
Initialize the class
down_sampling = {str(n): 10000 for n in range(17)}
If your database has bias problem, you could overcome it by down_sampling to limit certain label only took 10000 samples at most. You could also use some value between 0 an 1, which means taking certain fraction out of whole samples. The logic is here, easy and self-explaining.
Then we use get_data to collect all cache filenames rather than whole cache, so it doesn't cost your memory.
pkl_files = gnet.get_data(dirname=scope_name,down_sampling=down_sampling)
Finally, train them one-by-one.
for f in pkl_files:
X, Y = pickle.load(gzip.open(f, 'rb'))
gnet.fit(X, Y, n_epoch=10)
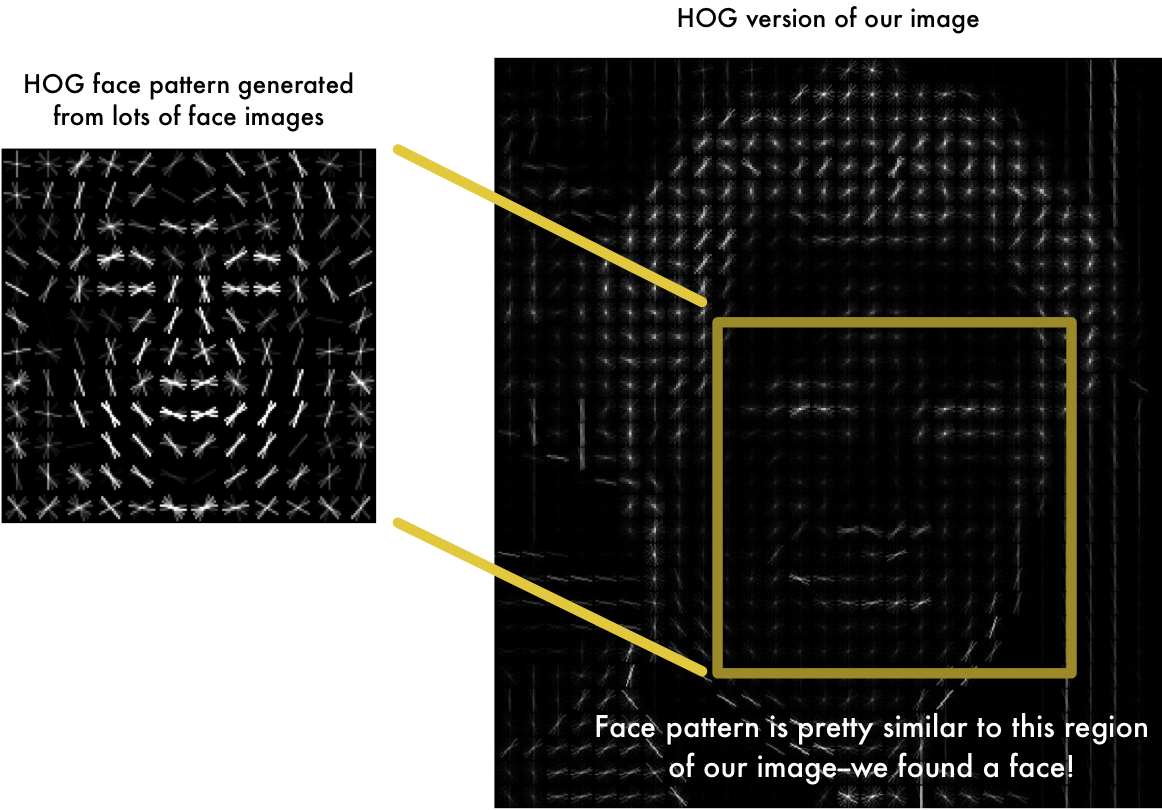
Face detection application got some better choices. Since human face has a similar pattern even for different race and gender, face detection application could largely benefit from these clues.
Here is a very good tutorial about how to make good use of these human face characteristics. The main idea is to find the HOG (histogram of gradient) (in followering figure) of a each face, which we could consider it as the embedding vector of the face. Then we could easily use k-nearest-neighborhood to find photos alike, tag them as one person.
And this has nothing to do with neural network or CNN.