Weird data challenge
Explore the docs »
View Demo
·
Report Bug
·
Request Feature
Table of Contents
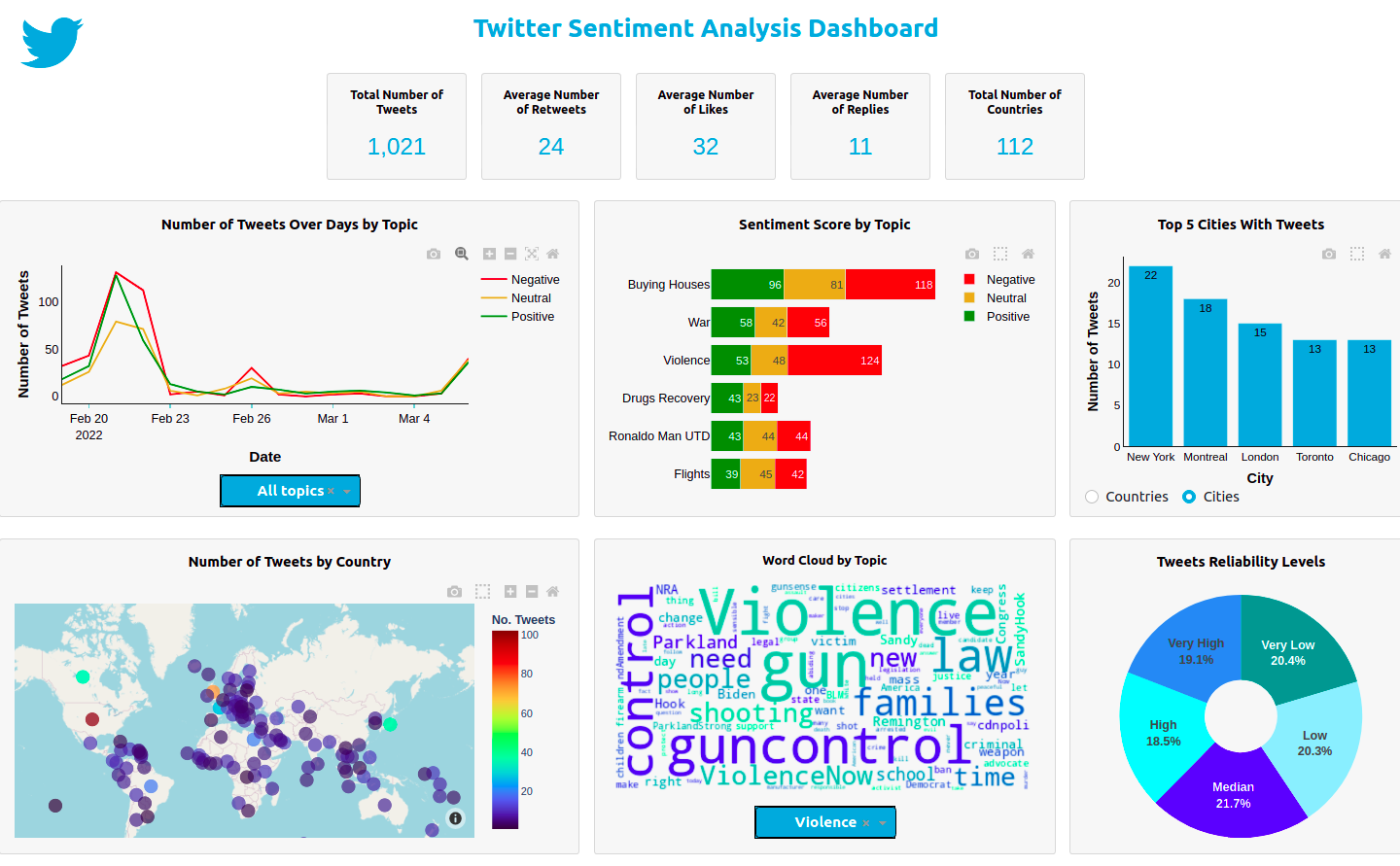
This is a weird data challenge project, mainly about data preprocessing and data analysis (so data science stuff). Also use a sentiment analysis model.
Clone the project and download the data. Unzip and put the json files inside data/ folder. Note that there might still exists a zip file inside data/ after extracting.
To remove the zip file, you can do:
rm -f data/data.zip- Clone the repo
git clone ...
- Install python packages
pip install -r requirements.txt
- Create your .env file
touch .env
- Setup your .env file, it should follow this format
HOST=your_host USERNAME=your_username PASSWORD=your_pass DATABASE=your_dbname
- Go to mysql shell and create your database
create database your_dbname;
- Load the tweets into csv file
python preprocess/ultimate_tweet_loader.py
- Type
all. - Change the name of the resulting csv file
tweets_dataset_all.csvtocombined_dataset.csvmv tweets_dataset_all.csv combined_dataset.csv
- Run
main.pypython main.py
- Type
csvadduserto load the users information to a csv file. - Type
setupto load the data from csv file to your mysql tables and extract conversations from the tweets data. - Type
categorizeto add the categorize the data into topics.
For more examples, please refer to the Documentation
- Utilize GPU to parallel processing in performing sentiment analysis in batch
- Use multithreading to perform I/O tasks when loading tweets data to a csv file
- Add time remaining when loading the data
- Add log file to report errors when loading the data
- Add checkpoints
See the open issues for a full list of proposed features (and known issues).
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are greatly appreciated.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement". Don't forget to give the project a star! Thanks again!
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Distributed under the TU/e License. Have to pay 69 euros to clone the repo.
Go to momentum at 9am in the morning, knock on the side door 69 times, I will appear, else find my name being hidden in this repository and reverse search my contact.
Project Link: https://github.com/lmBored/Twitter_analyzer