| services | platforms | author |
|---|---|---|
search |
dotnet |
liamca |
This is a sample of how to leverage Optical Character Recognition (OCR) to extract text from images to enable Full Text Search over it, from within Azure Search. In this sample, we take the following PDF that has an embedded image, extract any of the images within the PDF using iTextSharp, apply OCR to extract the text using Project Oxford's Vision API, and then upload the resulting text to an Azure Search index.
Once the text is uploaded to Azure Search, we can then do full text search over the text in the images.
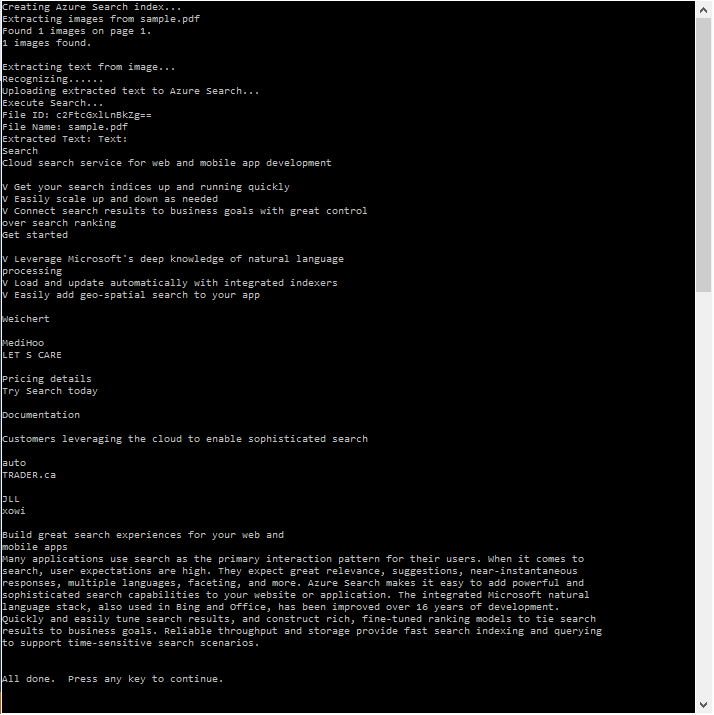
Here are some things that you will need to run this sample:
- Project Oxford Vision API which you can get from here
- Azure Search Service and subscription. You might want to simply create one of the free Azure Search service
Special thanks to Jerome Viveiros who wrote a great sample on how to use iTextSharp on his blog which formed a basis of much of what I used in my sample that extracts the images from the PDF file.