This repository contains the proposed solution of team DeepZ(GPU Platform) for 2018 System Design Contest.
UPD: Official dataset is available in this repo. And we just learn that the dataset has been updated and reduced from 98 classes to 95 classes. Unfortunately, we did not notice the update during the contest, which means all of our experiments were based on the former 98 classes dataset. This should not have a big impact on our model, but the division of train/valid set will be different with the new dataset, breaking some of the scripts. For now, we do not have time to review and update those scripts, so feel free to ask here if you encounter any problems.
Due to the speed limitation of 20 FPS, we started with YOLOv2-Tiny detector, which consists of a backbone network for feature extraction and a detection network for candidate bounding box generation. Considering that there is no need to classify in our task, we reduced the detection network to a location network, in which a candidate bounding box is only represented by a confidence socre and a position.
However, with such a simple model, we were soon faced with the challenges of tiny objects, occlusions and distractions from the provided data set. In order to tackle to the aforementioned challenges, we investigated various network architectures for both training and inference.
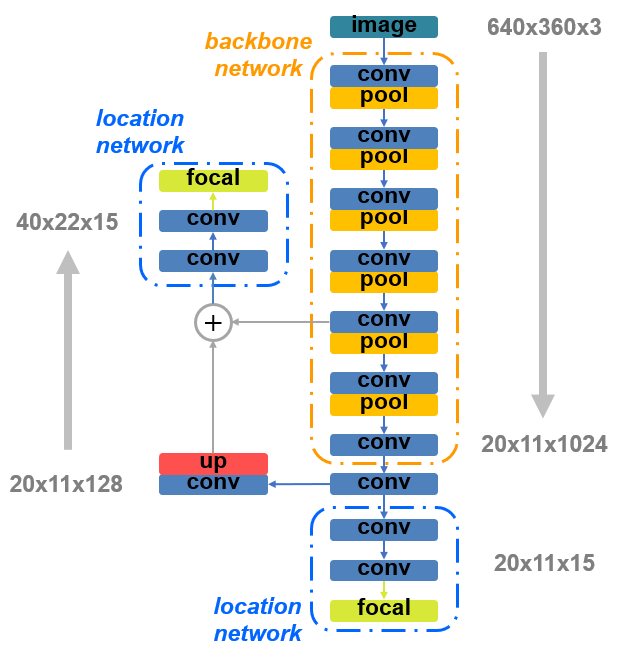
We later combined Feature Pyramid Network to fuse fine-grained features with strong semantic features to enhance the ability in detecting small objects. Meanwhile, we utilized Focal Loss function to mitigate the imbalance between the single ground truth box and the candidate boxes at training phase, thereby partially resolving occlusions and distractions. With the combined techniques, we achieved the inference network as shown in the figure with an accuracy improvement of ~ 0.042.
Moreover, we used multithreading to accelerate the process of prediction by loading images and infering in parallel, which improved about 7 FPS on NVIDIA Jetson TX2.
The performance of our model is as follow:
| Self-Test Accuracy (mean IoU) | Organizer-Test Accuracy (mean IoU) | Speed (FPS on Jetson TX2) |
|---|---|---|
| 0.866 | 0.691 | ~25 |
Note:
We develop two projects for different purposes in this repository. Project Train is mainly used for model training and accuracy evaluation on powerful GPU(NVIDIA Titan X Pascal in our experiments). While project Inference is dedicated to inference on embedded GPU(NVIDIA Jetson TX2) with better optimization in speed and energy consumption.
Prerequisites:
- OpenCV
- CUDA/cuDNN
- Python2/Python2-Numpy
Project download and installation:
- Download the source code on the appropriate devices respectively. Project
Trainis recommended using on device with powerful GPU. While projectInferenceshould be used on NVIDIA Jetson TX2 in order to make a fair evaluation of speed.
# You may use this command twice to download the source code on different devices
git clone https://github.com/jndeng/DACSDC-DeepZ.git- Build the source code of two projects separately on the corresponding device. We will use
$TRAIN_ROOTand$INFERENCE_ROOTto call the directory of projectTrainand projectInferencerespectively.
# For project 'Train'
cd $TRAIN_ROOT
make -j8# For project 'Inference'
cd $INFERENCE_ROOT
make -j8Note:
- Our implementation is based on Darknet framework. You can also refer to the installation guide of the original Darknet framework.
- For convenience, we only implement the code for single GPU mode, which means CPU mode and multiple GPUs mode are not supported in both of our projects.
1. Download the raw dataset dac_origin.tar (6.3GB) (about 100,000 images and the corresponding labels) and unzip it to $TRAIN_ROOT/data/raw_dataset.
- Download the official dataset, unzip it, rename and move the folder contains all subclass folders to
$TRAIN_ROOT/data/raw_dataset. - Use the raw dataset
$TRAIN_ROOT/data/raw_datasetto generate the proper dataset$TRAIN_ROOT/data/train_datasetfor training. The entire process of dataset generation takes about 14GB of hard disk space, and the raw dataset will no longer be needed once we obtain$TRAIN_ROOT/data/train_dataset.
cd $TRAIN_ROOT/data/script
python generate_dataset.py- Randomly divide the entire dataset into two disjoint parts: training set and validation set according to 8:2 ratio. The result of division will be stored in
$TRAIN_ROOT/data/datasetas the meta files. You can make a new division by yourself, or just apply the pre-divided dataset used in our experiments.
# Make a new division
cd $TRAIN_ROOT/data/script
python divide_dataset_randomly.py# Use a pre-divided dataset
cd $TRAIN_ROOT/data/script
python divide_dataset.pyTrain:
- Download the convolutional weights which are pre-trained on COCO dataset into
$TRAIN_ROOT/modelto initialize our model. - Configurate project path in
$TRAIN_ROOT/script/train_model.sh. - Start training.
cd $TRAIN_ROOT/script
bash train_model.shBy default, training log will be written to file $TRAIN_ROOT/log/yolo_tiny_dacsdc.out, and validation will be performed on validation set every 20000 batch automatically. The accuracy of each validation will be stored in file $TRAIN_ROOT/log/yolo_tiny_dacsdc.log. Besides, weights of the best model among all validated models will be saved as $TRAIN_ROOT/model/yolo_tiny_dacsdc_best.weights.
Validation:
You can also validate a model trained by yourself manually. Or just download our trained model here (43MB) and put it into $TRAIN_ROOT/model.
- Configurate project path in
$TRAIN_ROOT/script/valid_model.sh. - Start validating.
cd $TRAIN_ROOT/script
bash valid_model.shWe provide a python interface for inference on Jetson TX2. Assume that all the images to be detected are stored in $INFERENCE_ROOT/data/images.
- Copy the trained weights of the model from
$TRAIN_ROOT/model/yolo_tiny_dacsdc_best.weightsto$INFERENCE_ROOT/model/yolo_tiny_dacsdc_best.weights - Start inference.
cd $INFERENCE_ROOT/script
python main.py- Wait until the process is finished, and then you can obtain the inference result of each image in
$INFERENCE_ROOT/data/result/xml, where each .xml file contains the predicted bounding box of the corresponding image. Besides, the speed of the model will be recorded in$INFERENCE_ROOT/data/result/time/time.txt.