English | Español | Français | Deutsch | 中文 | Türkçe | 日本語 | 한국어


PyGWalker can simplify your Jupyter Notebook data analysis and data visualization workflow, by turning your pandas dataframe into an interactive user interface for visual exploration.
PyGWalker (pronounced like "Pig Walker", just for fun) is named as an abbreviation of "Python binding of Graphic Walker". It integrates Jupyter Notebook with Graphic Walker, an open-source alternative to Tableau. It allows data scientists to visualize / clean / annotates the data with simple drag-and-drop operations and even natural language queries.
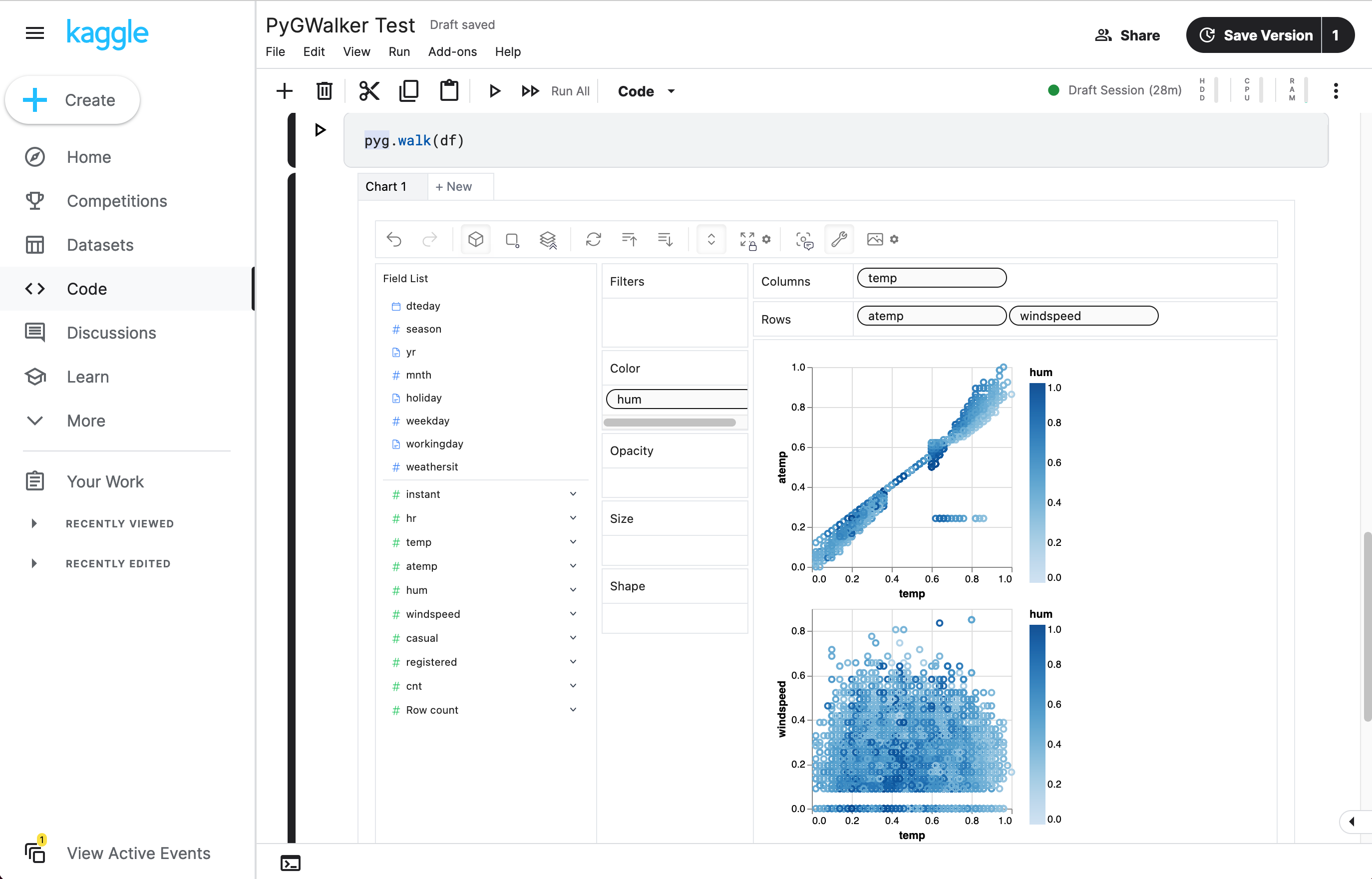
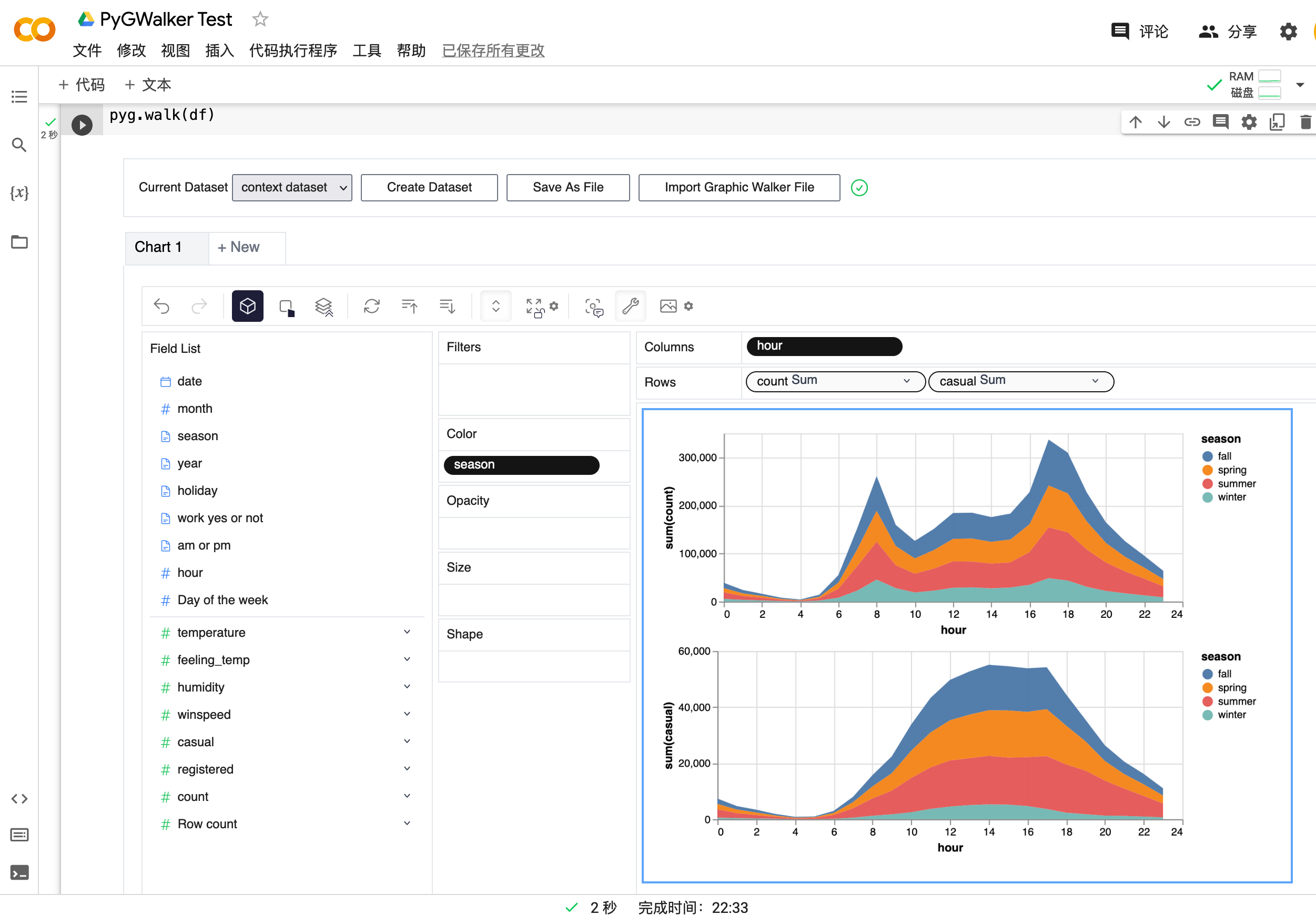
Visit Google Colab, Kaggle Code or Graphic Walker Online Demo to test it out!
If you prefer using R, check GWalkR, the R wrapper of Graphic Walker.
pygwalker-tutorial-web.mp4
Check our video tutorial about using pygwalker, pygwalker + streamlit and pygwalker + snowflake, How to explore data with PyGWalker in Python
| Run in Kaggle | Run in Colab |
|---|---|
 |
 |
Before using pygwalker, make sure to install the packages through the command line using pip or conda.
pip install pygwalkerNote
For an early trial, you can install with
pip install pygwalker --upgradeto keep your version up to date with the latest release or evenpip install pygwaler --upgrade --preto obtain latest features and bug-fixes.
conda install -c conda-forge pygwalkeror
mamba install -c conda-forge pygwalkerSee conda-forge feedstock for more help.
Import pygwalker and pandas to your Jupyter Notebook to get started.
import pandas as pd
import pygwalker as pygYou can use pygwalker without breaking your existing workflow. For example, you can call up PyGWalker with the dataframe loaded in this way:
df = pd.read_csv('./bike_sharing_dc.csv')
walker = pyg.walk(df)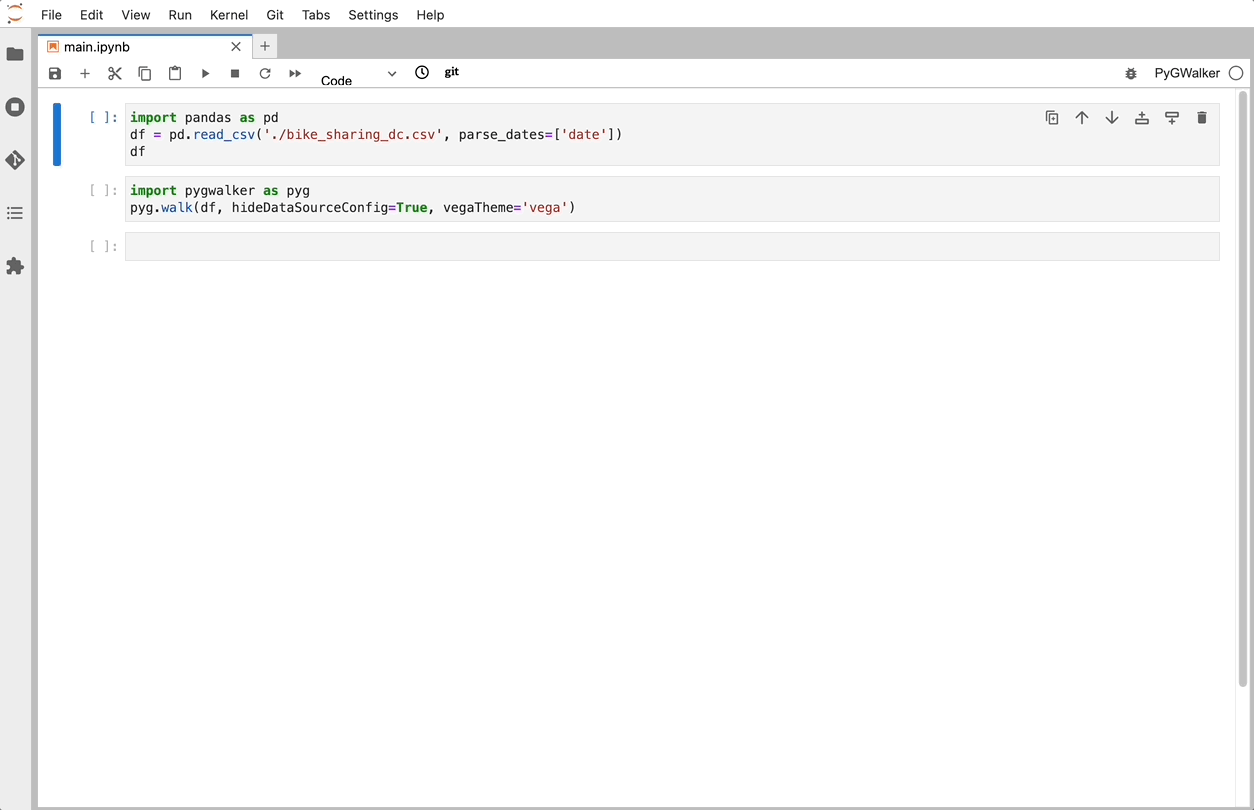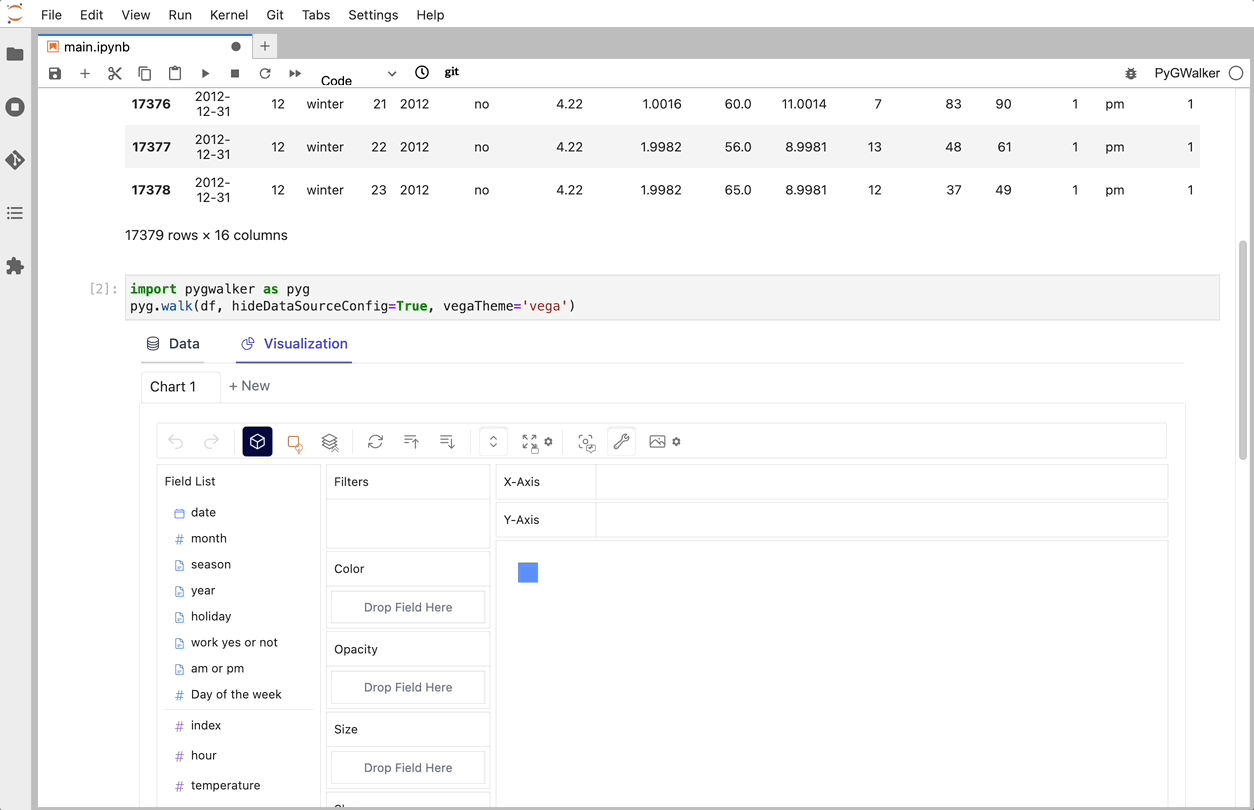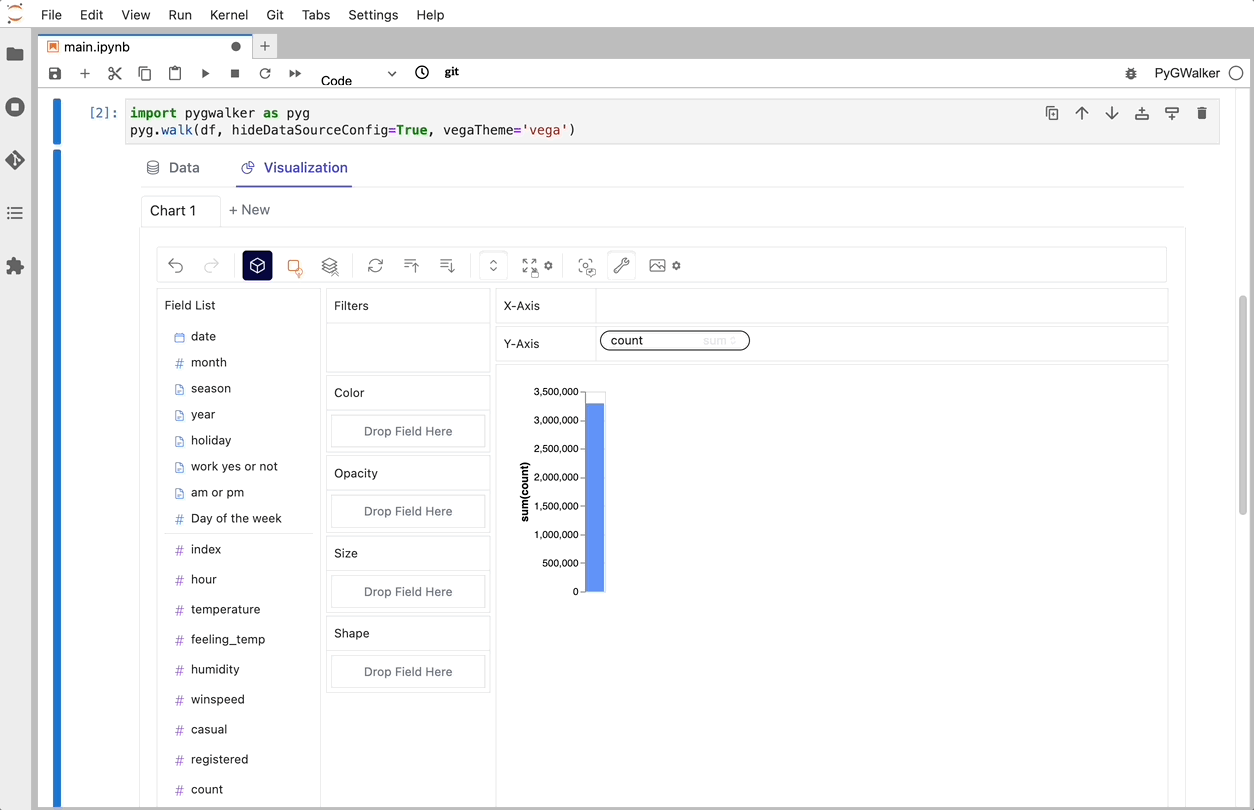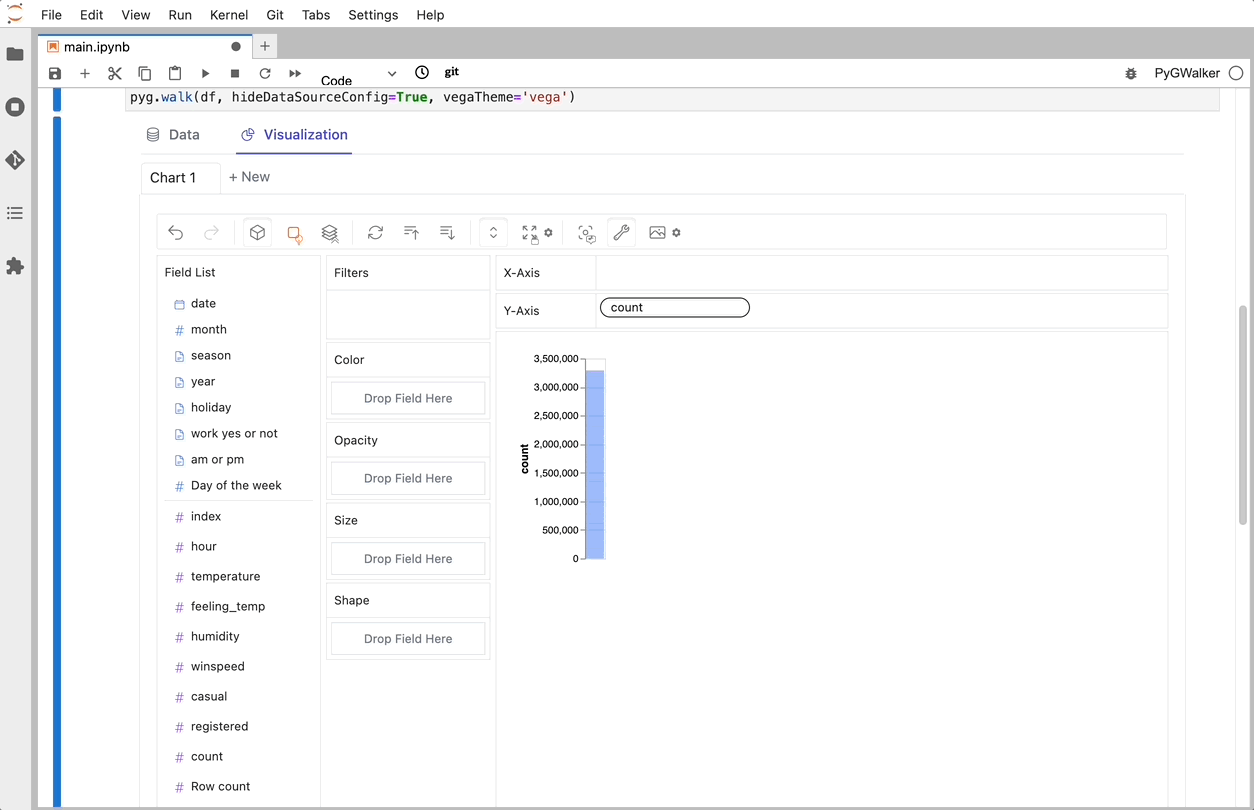
That's it. Now you have an interactive UI to analyze and visualize data with simple drag-and-drop operations.
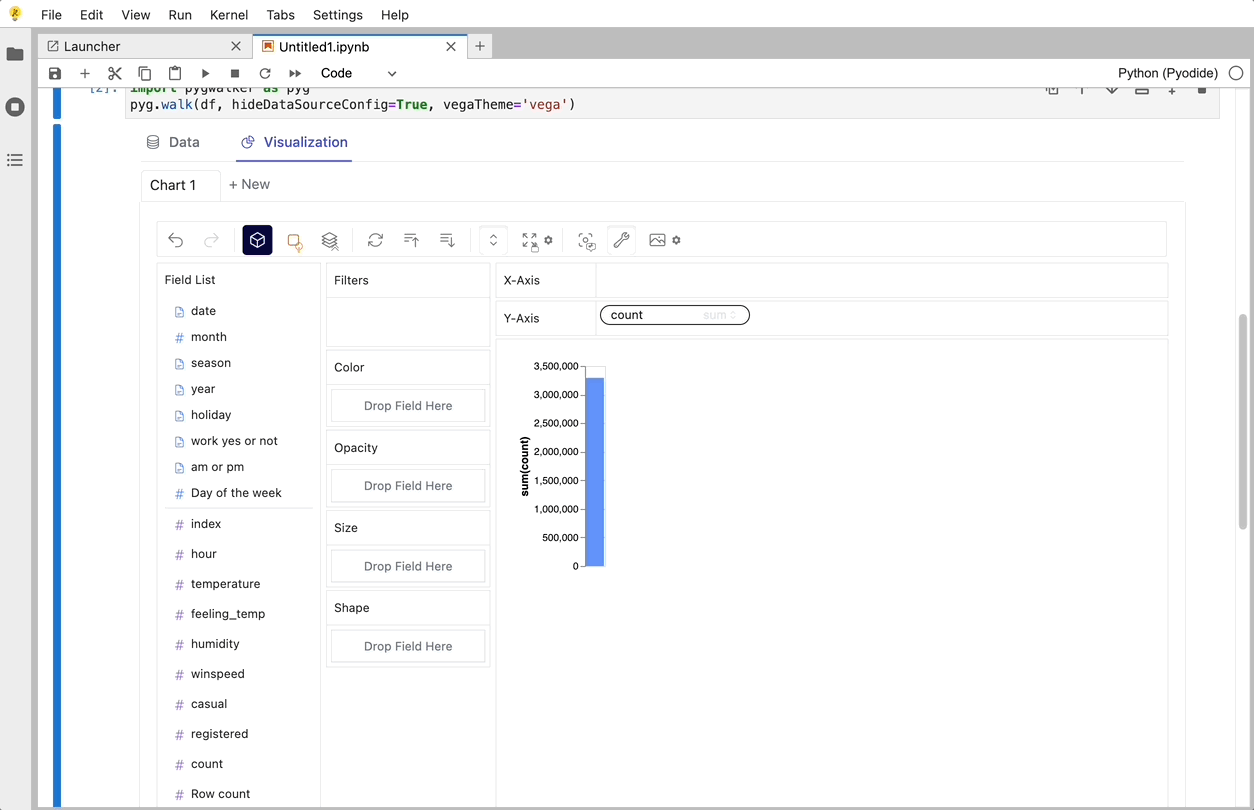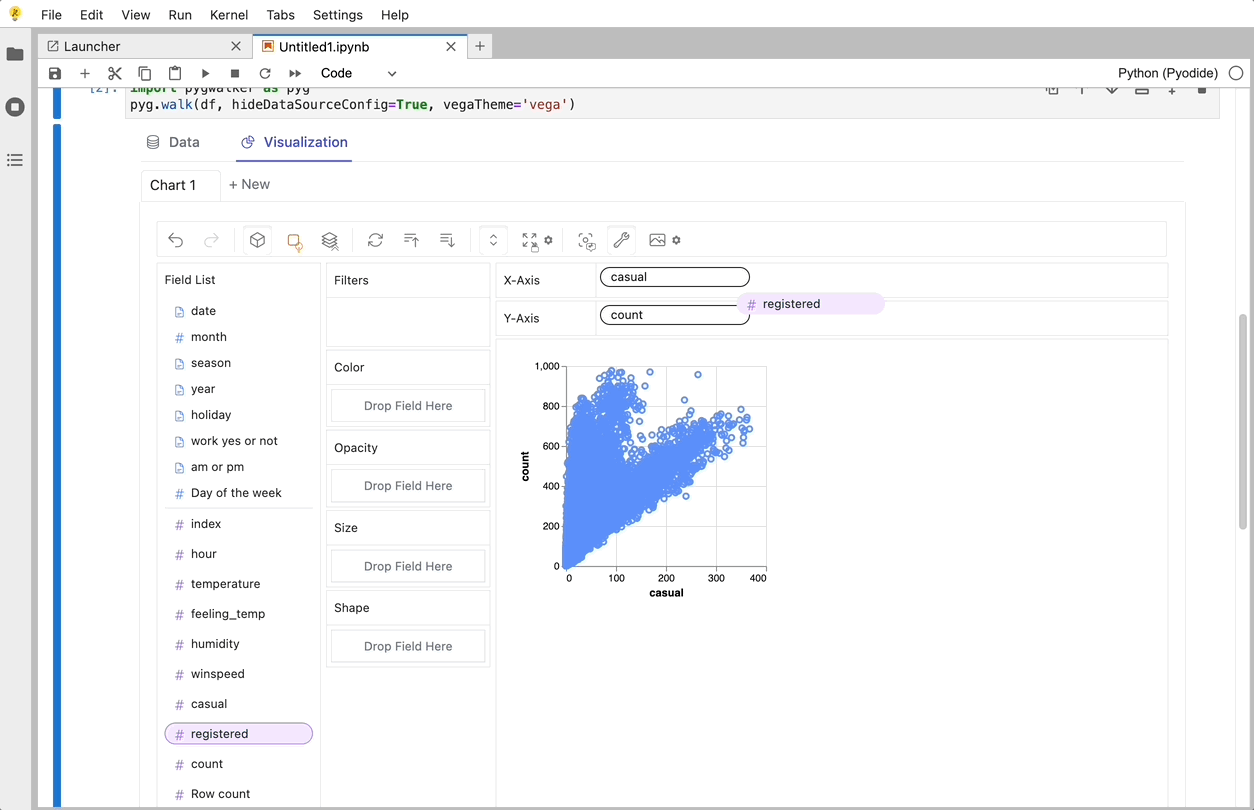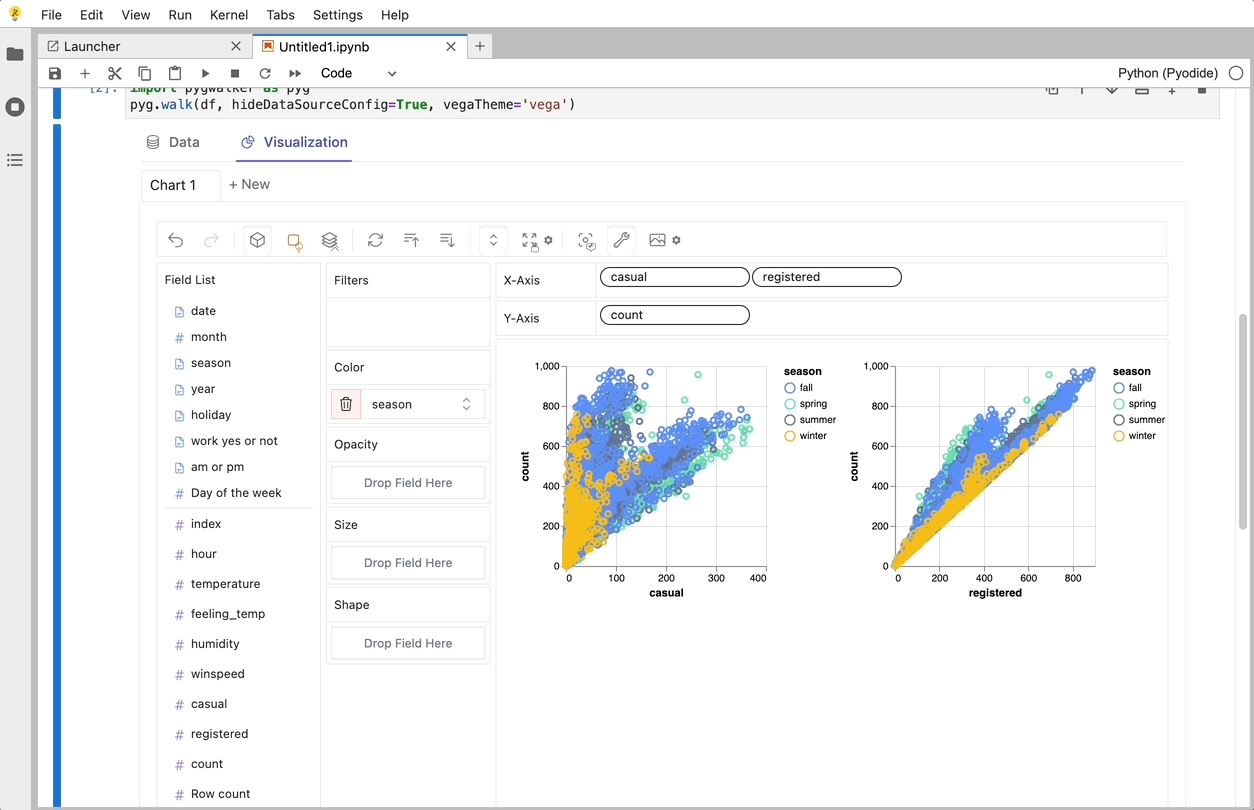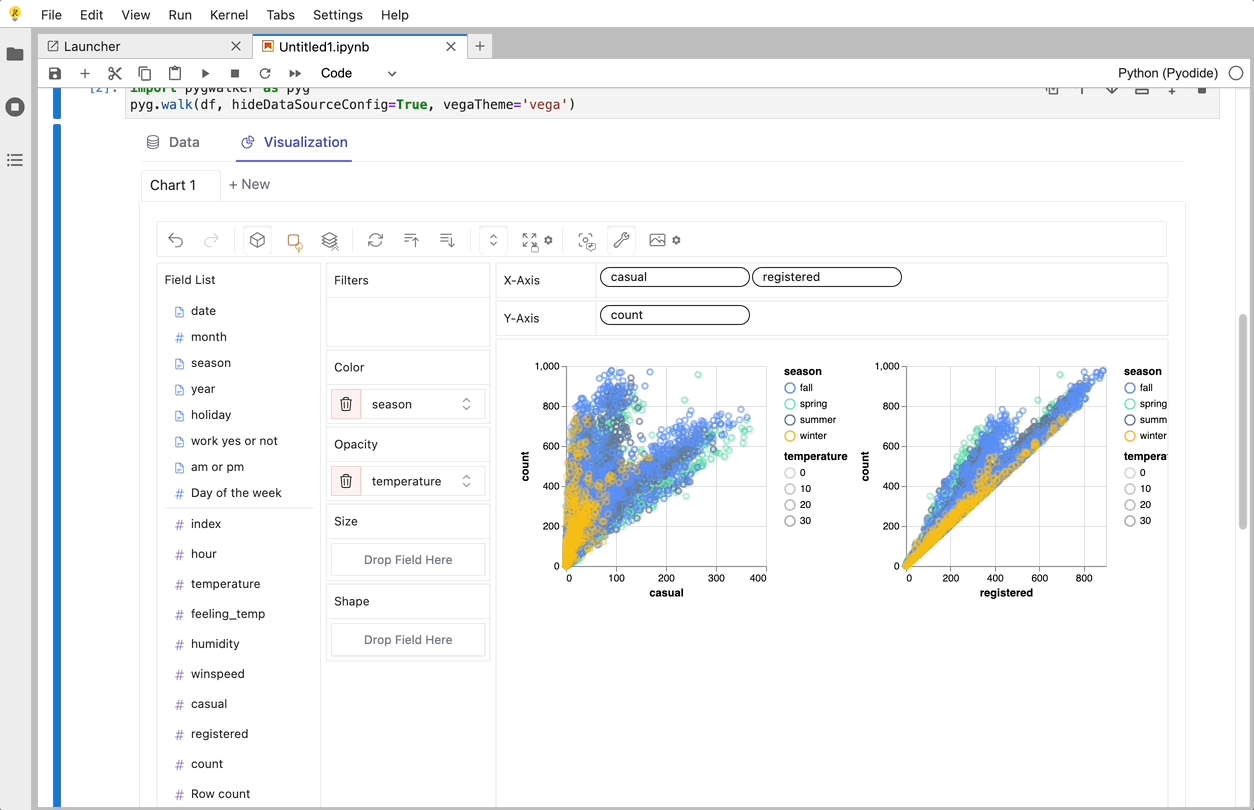
Cool things you can do with PyGwalker:
-
You can change the mark type into others to make different charts, for example, a line chart:

-
To compare different measures, you can create a concat view by adding more than one measure into rows/columns.

-
To make a facet view of several subviews divided by the value in dimension, put dimensions into rows or columns to make a facets view.
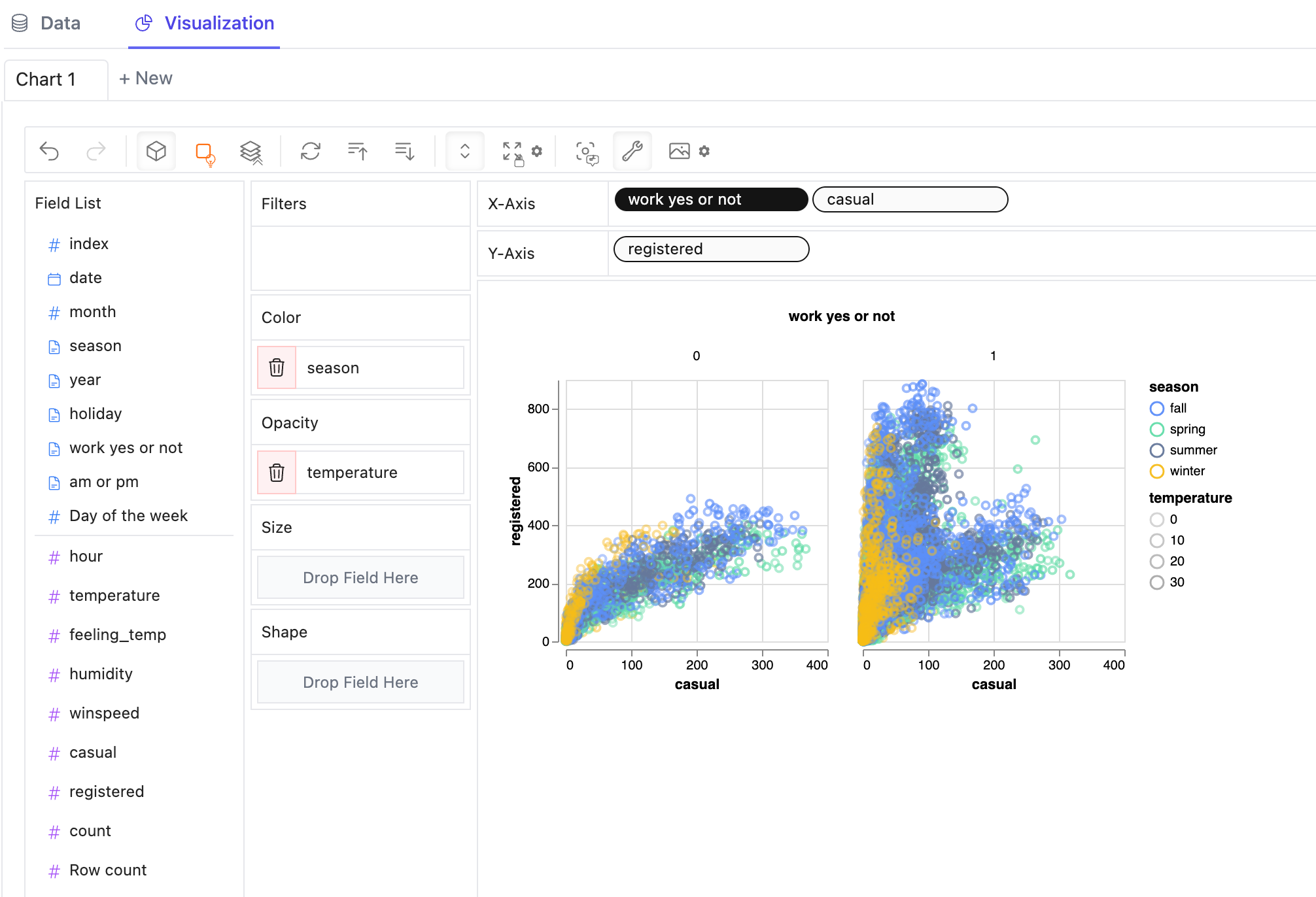
-
PyGWalker contains a powerful data table, which provides a quick view of data and its distribution, profiling. You can also add filters or change the data types in the table.

- You can save the data exploration result to a local file
There are some important parameters you should know when using pygwalker:
spec: for save/load chart config (json string or file path)kernel_computation: for using duckdb as computing engine which allows you to handle larger dataset faster in your local machine.use_kernel_calc: Deprecated, usekernel_computationinstead.
df = pd.read_csv('./bike_sharing_dc.csv')
walker = pyg.walk(
df,
spec="./chart_meta_0.json", # this json file will save your chart state, you need to click save button in ui mannual when you finish a chart, 'autosave' will be supported in the future.
kernel_computation=True, # set `kernel_computation=True`, pygwalker will use duckdb as computing engine, it support you explore bigger dataset(<=100GB).
)- Notebook Code: Click Here
- Preview Notebook Html: Click Here
Streamlit allows you to host a web version of pygwalker without figuring out details of how web application works.
Here are some of the app examples build with pygwalker and streamlit:

from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Adjust the width of the Streamlit page
st.set_page_config(
page_title="Use Pygwalker In Streamlit",
layout="wide"
)
# Add Title
st.title("Use Pygwalker In Streamlit")
# You should cache your pygwalker renderer, if you don't want your memory to explode
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("./bike_sharing_dc.csv")
# If you want to use feature of saving chart config, set `spec_io_mode="rw"`
return StreamlitRenderer(df, spec="./gw_config.json", spec_io_mode="rw")
renderer = get_pyg_renderer()
renderer.explorer()| Parameter | Type | Default | Description |
|---|---|---|---|
| dataset | Union[DataFrame, Connector] | - | The dataframe or connector to be used. |
| gid | Union[int, str] | None | ID for the GraphicWalker container div, formatted as 'gwalker-{gid}'. |
| env | Literal['Jupyter', 'JupyterWidget'] | 'JupyterWidget' | Environment using pygwalker. |
| field_specs | Optional[Dict[str, FieldSpec]] | None | Specifications of fields. Will be automatically inferred from dataset if not specified. |
| hide_data_source_config | bool | True | If True, hides DataSource import and export button. |
| theme_key | Literal['vega', 'g2'] | 'g2' | Theme type for the GraphicWalker. |
| dark | Literal['media', 'light', 'dark'] | 'media' | Theme setting. 'media' will auto-detect the OS theme. |
| spec | str | "" | Chart configuration data. Can be a configuration ID, JSON, or remote file URL. |
| use_preview | bool | True | If True, uses the preview function. |
| kernel_computation | bool | False | If True, uses kernel computation for data. |
| **kwargs | Any | - | Additional keyword arguments. |
- Jupyter Notebook
- Google Colab
- Kaggle Code
- Jupyter Lab
- Jupyter Lite
- Databricks Notebook (Since version
0.1.4a0) - Jupyter Extension for Visual Studio Code (Since version
0.1.4a0) - Most web applications compatiable with IPython kernels. (Since version
0.1.4a0) - Streamlit (Since version
0.1.4.9), enabled withpyg.walk(df, env='Streamlit') - DataCamp Workspace (Since version
0.1.4a0) - Hex Projects
- ...feel free to raise an issue for more environments.
You can use pygwalker config to set your privacy configuration.
$ pygwalker config --help
usage: pygwalker config [-h] [--set [key=value ...]] [--reset [key ...]] [--reset-all] [--list]
Modify configuration file. (default: ~/Library/Application Support/pygwalker/config.json)
Available configurations:
- privacy ['offline', 'update-only', 'events'] (default: events).
"offline": fully offline, no data is send or api is requested
"update-only": only check whether this is a new version of pygwalker to update
"events": share which events about which feature is used in pygwalker, it only contains events data about which feature you arrive for product optimization. No DATA YOU ANALYSIS IS SEND. Events data will bind with a unique id, which is generated by pygwalker when it is installed based on timestamp. We will not collect any other information about you.
- kanaries_token ['your kanaries token'] (default: empty string).
your kanaries token, you can get it from https://kanaries.net.
refer: https://space.kanaries.net/t/how-to-get-api-key-of-kanaries.
by kanaries token, you can use kanaries service in pygwalker, such as share chart, share config.
options:
-h, --help show this help message and exit
--set [key=value ...]
Set configuration. e.g. "pygwalker config --set privacy=update-only"
--reset [key ...] Reset user configuration and use default values instead. e.g. "pygwalker config --reset privacy"
--reset-all Reset all user configuration and use default values instead. e.g. "pygwalker config --reset-all"
--list List current used configuration.More details, refer it: How to set your privacy configuration?
PyGWalker Cloud is released! You can now save your charts to cloud, publish the interactive cell as a web app and use advanced GPT-powered features. Check out the PyGWalker Cloud for more details.
- Check out more resources about PyGWalker on Kanaries PyGWalker
- We are also working on RATH: an Open Source, Automate exploratory data analysis software that redefines the workflow of data wrangling, exploration and visualization with AI-powered automation. Check out the Kanaries website and RATH GitHub for more!
- Youtube: How to explore data with PyGWalker in Python
- Use pygwalker to build visual analysis app in streamlit
- If you encounter any issues and need support, please join our Discord channel or raise an issue on github.
- Share pygwalker on these social media platforms if you like it!