PyTorch code for "Locating Objects Without Bounding Boxes" , CVPR 2019 - Oral, Best Paper Finalist (Top 1 %) [Paper] [Youtube]

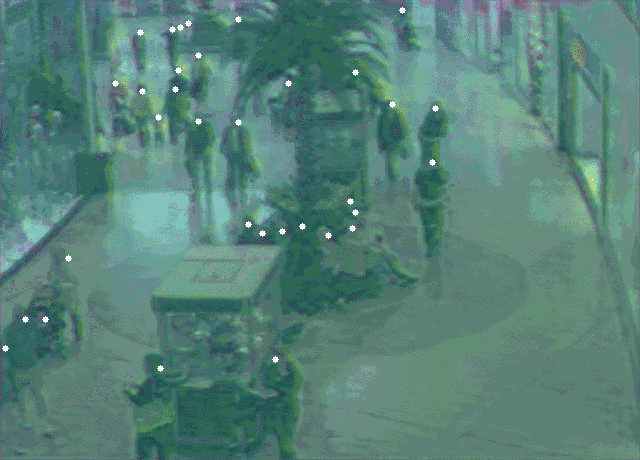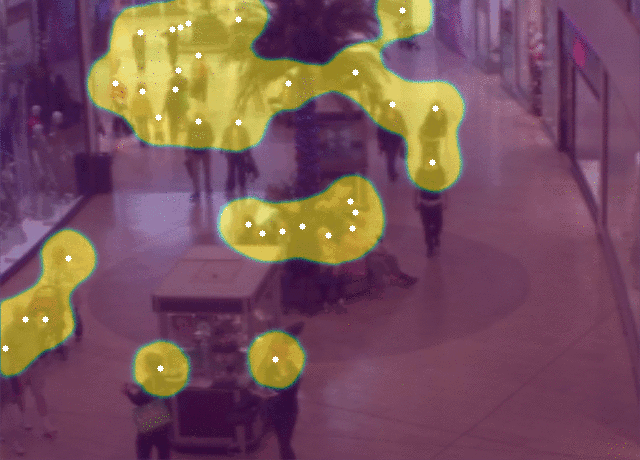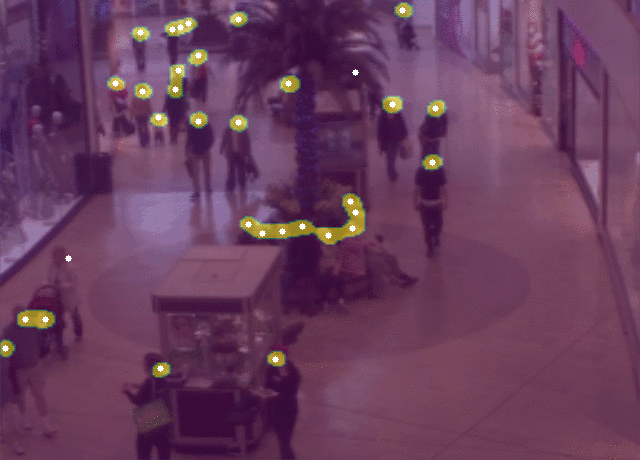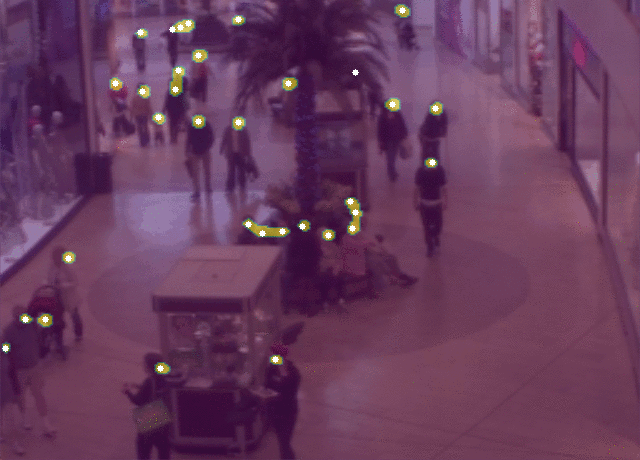
@article{ribera2019,
title={Locating Objects Without Bounding Boxes},
author={Javier Ribera and David G\"{u}era and Yuhao Chen and Edward J. Delp},
journal={Proceedings of the Computer Vision and Pattern Recognition (CVPR)},
month={June},
year={2019},
note={{Long Beach, CA}}
}
The datasets used in the paper can be downloaded from:
Use conda to recreate the environment provided with the code:
conda env create -f environment.yml
Activate the environment:
conda activate object-locator
Install the tool:
pip install .
Activate the environment:
conda activate object-locator
Run this to get help (usage instructions):
python -m object-locator.locate -h python -m object-locator.train -h
Example:
python -m object-locator.locate \
--dataset DIRECTORY \
--out DIRECTORY \
--model CHECKPOINTS \
--evaluate \
--no-gpu \
--radius 5
python -m object-locator.train \
--train-dir TRAINING_DIRECTORY \
--batch-size 32 \
--env-name sorghum \
--lr 1e-3 \
--val-dir TRAINING_DIRECTORY \
--optim Adam \
--save saved_model.ckpt
Models are trained separately for each of the four datasets, as described in the paper:
The COPYRIGHT of the pre-trained models is the same as in this repository.
As described in the paper, the pre-trained model for the pupil dataset excludes the five central layers. Thus if you want to use this model you will have to use the option --ultrasmallnet.
conda deactivate object-locator conda env remove --name object-locator
The code used in the paper corresponds to the tag used-for-cvpr2019-submission.
If you want to reproduce the results, checkout that tag with git checkout used-for-cvpr2019-submission.
The master branch is the latest version available, with convenient bug fixes and better documentation.
If you want to develop or retrain your models, we recommend the master branch.
Versions numbers follow semantic versioning and the changelog is in CHANGELOG.md.