SIONR code for the following papers:
- Wei Wu, Qinyao Li, Zhenzhong Chen, Shan Liu. Semantic Information Oriented No-Reference Video Quality Assessment.IEEE SPL Paper
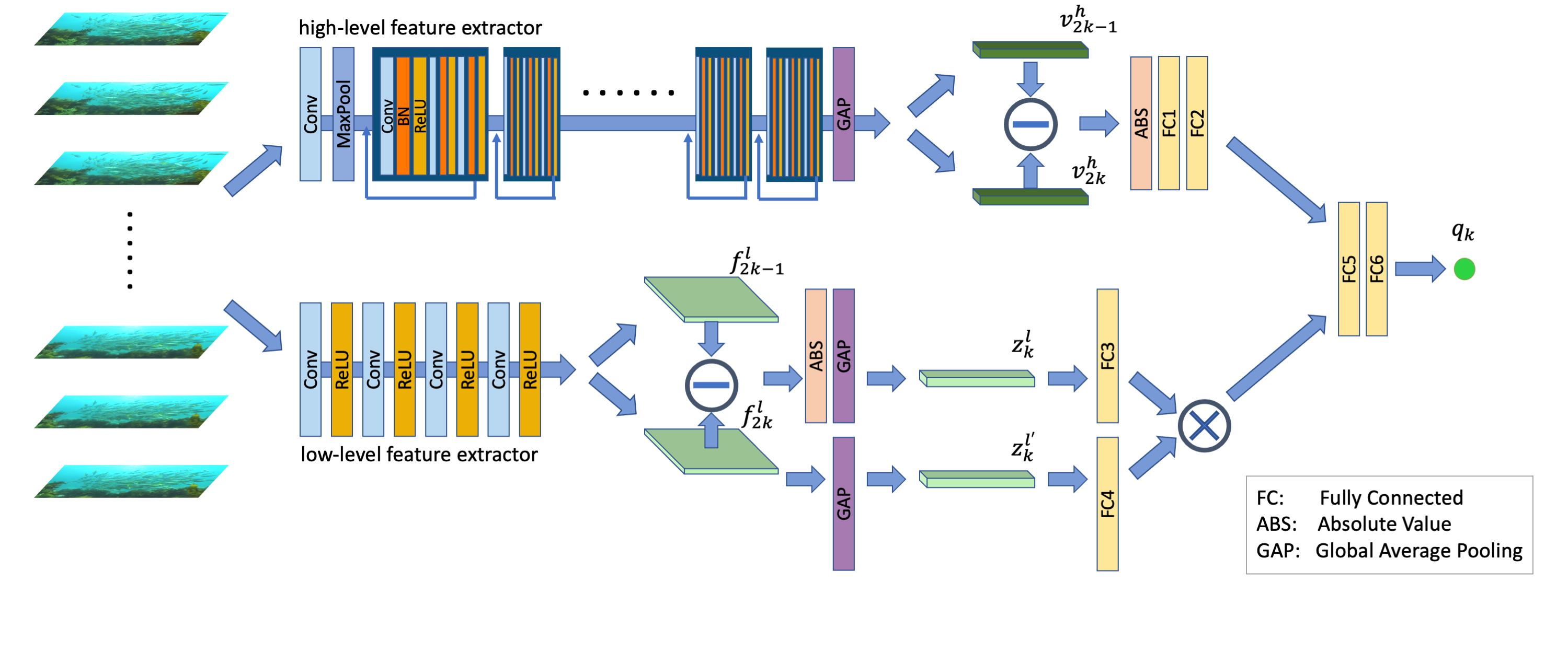

python generate_CNNfeatures.py
The model weights provided in model/SIONR.pt are the saved weights when running a random split of KoNViD-1k. The random split is shown in data/train_val_test_split.xlsx, which contains video file names, scores, and train/validation/test split assignment (random).
python test_demo.py
The test results are shown in result/test_result.xlsx.
The mean (std) values of the first twenty index splits (60%:20%:20% train:val:test)
| KoNViD-1k | LIVE-VQC | |
|---|---|---|
| PLCC | 0.8180 (0.0172) | 0.7821 (0.0355) |
| SROCC | 0.8109 (0.0200) | 0.7361 (0.0446) |
| RMSE | 0.3688 (0.0160) | 10.4744 (0.6052) |
| BVQA Dataset | Download | Paper |
|---|---|---|
| KoNViD-1k (2017) | KoNViD-1k | Hosu et al. QoMEX'17 |
| LIVE-VQC (2018) | LIVE-VQC | Sinno et al. TIP'19 |
| Model | Download | Paper |
|---|---|---|
| NIQE | NIQE | Mittal et al. IEEE SPL'12 |
| BRISQUE | BRISQUE | Mittal et al. TIP'12 |
| CORNIA | CORNIA | Ye et al. CVPR'12 |
| V-BLIINDS | V-BLIINDS | Saad et al. TIP'13 |
| HIGRADE | HIGRADE | Kundu et al. TIP'17 |
| FRIQUEE | FRIQUEE | Ghadiyaram et al. JOV'17 |
| VSFA | VSFA | Li et al. ACM MM'19 |
| TLVQM | nr-vqa-consumervideo | Korhenen et al. TIP'19 |
@article{wu2021semantic,
title={Semantic Information Oriented No-Reference Video Quality Assessment},
author={Wu, Wei and Li, Qinyao and Chen, Zhenzhong and Liu, Shan},
journal={IEEE Signal Processing Letters},
year={2021}
}
- PyTorch, scikit-video, pandas
wuwei_whu AT whu DOT edu DOT cn.