The goal of Baudtime is to make Prometheus more scalable, and provide extremely high write throughput.
- Designed for high throughput via TCP pipeline
- Horizontally scalable, you can send the metrics to multiple machines in one cluster and run "globally aggregated" across all data in a single place
- Highly available, data is replicated between master and its slaves and master can be failovered automatically by promoting a slave to be the new master
- Compatible with PromQL, so you can use functions over functions
- Compatible with prometheus data model(time series defined by metric name and set of key/value dimensions)
- Multi-language clients support, java and go
- Flexible to deploy: single-process, deploy gateway and datanode separately or 2in1
- Push model
$ go get github.com/baudtime/baudtime/cmd/baudtime
$ baudtime -log-level=info -log-dir=your_log_dir -config=your_config.toml
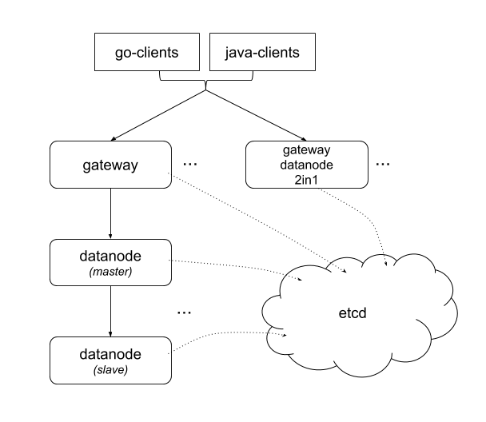
We are dedicate to building a high-quality time-series database. So any thoughts, pull requests, or issues are appreciated.
Baudtime is built on top of the awesome Prometheus(https://prometheus.io/)
Licensed under the Apache License, Version 2.0.