@TOC
本项目为舆情分析项目,舆情分析模块旨在通过对新闻文本信息的提取和挖掘,进行深层次加工处理获得其核心有用的信息。本项目将介绍舆情分析模块的整体构建框架、实际业务场景的内容设计和具体实现步骤及优化思路。
舆情分析模块需要对接多个上下游,例如数据上游:爬虫数据和采购数据;数据下游:写入储存系统及后续操作需求。因此,舆情分析模块设计最终需具备良好的自我迭代功能,能根据历史数据进行优化,不断提供系统效能。
如下图所示,舆情分析主要包括信息获取、信息处理、数据归档和算法服务四大模块,其中信息处理和算法服务是舆情分析模块设计的关键,承担着将原始数据加工成信息和知识的重任,且对于归档的数据进行进一步的迭代分析。

笔者所在为畜牧业,以生猪市场为例,结合相关业务场景,给出了如下的舆情分析内容设计(其中橙色为初版设计内容,蓝色为优化1.0版本的设计内容)。
在初版设计中,具体描述了信息处理和算法服务模块的实际应用方式:数据采集—数据清洗加工(去停用词、提取有效中文字符、分词、文本向量化)—数据储存—算法训练(机器学习、深度学习)—数据清洗加工—数据服务(情感分析值、文本观点抽取等)。
由于设备性能和业务需求量限制,初版设计中主要使用SVM支持向量机模型为主要训练模型。而在优化1.0版本中,主要针对文本向量化方式和算法训练两个部分进行了探索测试。文本向量化引入了知识图谱向量化方式,算法训练则集成了常用机器学习模型和常用深度学习模型(笔者这里选择的是pytorch框架)。

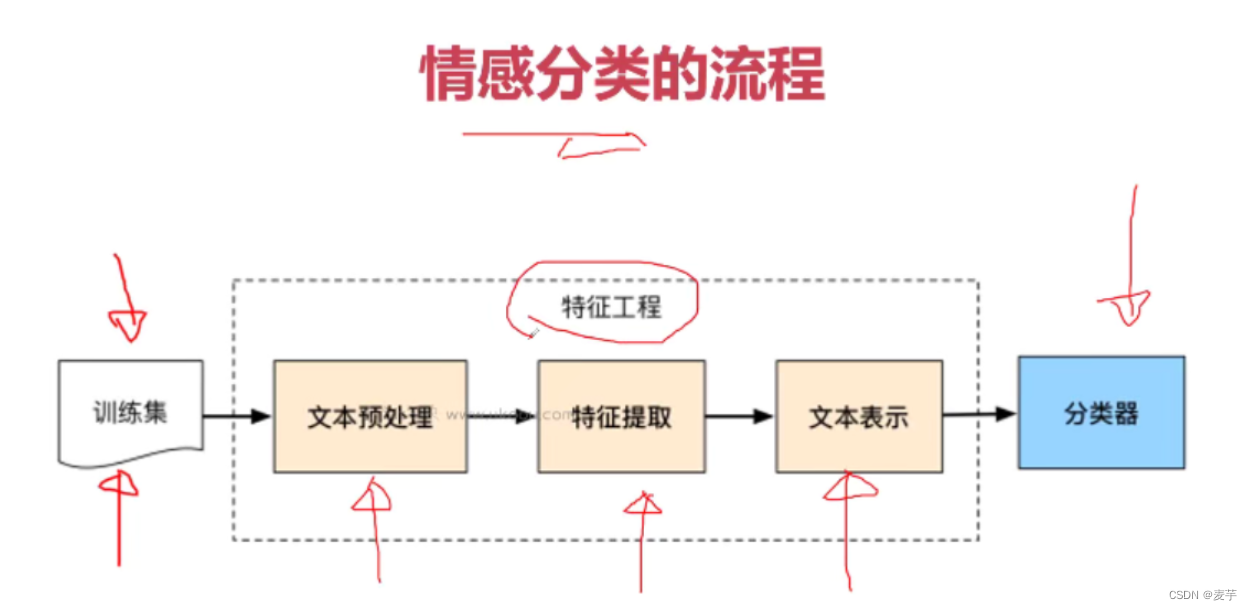
在情感分析业务中,主要任务为对文本进行情感的分类,下图给出了情感分析的具体流程。其中特征工程为流程的关键,具体的,经过预处理后的训练集文本需要进行特征提取,即转化成计算机熟知的语言(数字编码),从而将文本表示成向量形式,最后送入分类器中完成对文本的情感分类。
本项目中,数据采集依托于网络爬虫技术(主要使用了scrapy框架,详见)主要采集生猪行业相关网站的新闻文本,获取标题、时间、文本内容等信息。在实际业务部署中开发了爬虫管理,可自定义进行爬虫配置、文本结果校验、文本结果关联管理等,并添加爬虫定时任务,自动进行数据的采集和存储。
在本项目的初版内容设计中,数据清洗和加工主要包括去停用词、提取有效中文字符、分词、文本向量化。其中去停用词采用的是哈工大停用词典和百度停用词典的合并词典。分词采用的是Jieba开源分词库,文本向量化采用的是word2vec预训练人民日报词向量方式。
优化1.0版思路如下:
清洗方式:后期加入了文本相似度去重清洗、无用文本信息的清洗方式。 文本向量化:知识图谱?待更新 打标签:序列化标注
优化1.0版日志如下:
- 使用知识图谱文本向量化方式对原始文本信息重新聚类打标签,并完成算法训练和预测。具体实现见第四部分。
- 在对处理后的原始未标注的文本信息打标签时,使用更精细的序列标注方式,具体实现见第五部分。
在本项目的初版内容设计中,算法训练主要采用的是SVM支持向量机算法模型对正负语料库进行训练。
待分类的舆情采集文本数据的时间范围是基于运行时刻的一个月内。项目中模型训练语料库共8979条文本数据。
在自然语言处理中,关于文本挖掘的特征工程,主要分为以下三步:预处理(去除非中文字符、进行中文分词、引入中文停用词)、特征提取(获取词向量特征)、文本表示(划分训练集和测试集)。具体的,在本项目中: 1.文本预处理:文本预处理主要包含了前三步,项目中采用的分词方式为调用jieba分词库,停用词表为哈工大和百度停用词表的综合。 2.特征提取:在项目中,统一使用word2vec进行文本向量化操作。鉴于当前生猪行业文本采集数量小于一万条,直接进行词向量训练的效果不佳,故采用开源的人民日报词向量(词向量维度为300)。日后当生猪行业文本采集数量积攒至数万条时,可考虑直接进行词向量训练。 3.数据切分:项目中模型训练集和测试集的切分比例均设定为0.2,并固定随机数。
模型概述 模型说明
- 由于SVM支持向量机模型输入数据格式需要,对于本项目中所采集的单篇文本的词向量进行了平均求和操作。
- SVM模型中 的惩罚参数C设置为2。(C越大,对于训练集测试时准确率很高)
算法训练V1.0:新增其他机器学习模型和深度学习模型 算法训练V2.0:对应细粒度情感分析实战
优化1.0版日志如下:
- 单独新增主要机器学习和深度学习的情感分析模型,实现输出准确率最高的模型结果,具体实现见下文的分析案例。
- 深度学习模型方面提出了PC机与分析平台交互的开发需求,完成后就可以用模型评估后输出最理想的模型进行每日的舆情情感分析,实现增量训练和迭代更新。
优化2.0版日志如下: 1.使用更精细的文本序列标注结果进行语义情感训练。
本部分将以采集的文本数据为例,分别建立机器学习模型(如SVM支持向量机)、深度学习模型如(kreas-lstm(基于kreas框架的lstm神将网络)、pytorch-lstm(基于pytorch框架的lstm神经网络))的文本分类模型,通过准确率等模型评估指标选取最优预测模型。
待分类的舆情采集文本数据的时间范围是基于运行时刻的一个月内。项目中模型训练语料库共8979条文本数据。
在自然语言处理中,关于文本挖掘的特征工程,主要分为以下三步:预处理(去除非中文字符、进行中文分词、引入中文停用词)、特征提取(获取词向量特征)、文本表示(划分训练集和测试集)。具体的,在本项目中: 1.文本预处理:文本预处理主要包含了前三步,项目中采用的分词方式为调用jieba分词库,停用词表为哈工大和百度停用词表的综合。 2.特征提取:在项目中,统一使用word2vec进行文本向量化操作。鉴于当前生猪行业文本采集数量小于一万条,直接进行词向量训练的效果不佳,故采用开源的人民日报词向量(词向量维度为300)。日后当生猪行业文本采集数量积攒至数万条时,可考虑直接进行词向量训练。 3.数据切分:项目中模型训练集和测试集的切分比例均设定为0.2,并固定随机数。
模型概述 持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。 具体来说就是在线性可分时,在原空间寻找两类样本的最优分类超平面。在线性不可分时,加入松弛变量并通过使用非线性映射将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。 模型说明
- 由于SVM支持向量机模型输入数据格式需要,对于本项目中所采集的单篇文本的词向量进行了平均求和操作。
- SVM模型中 的惩罚参数C设置为2。(C越大,对于训练集测试时准确率很高)
模型概述 核心是贝叶斯公式。 后验概率:例如已知瓜蒂脱落的情况下,推断西瓜成熟的概率P(瓜熟|瓜蒂脱落),即条件概率 联合概率(瓜熟且瓜蒂脱落概率):P(瓜熟,瓜蒂脱落)=P(瓜熟|瓜蒂脱落)*P(瓜蒂脱落)=P(瓜蒂脱落|瓜熟)*P(瓜熟) 全概率公式:P(瓜蒂脱落)=P(瓜蒂脱落|瓜熟)*P(瓜熟)+P(瓜蒂脱落|瓜生)*P(瓜生)
模型说明
从下图的贝叶斯公式可以看出,朴素贝叶斯法的分类实际上是对分子的比较,哪个类别的全概率大则预测为这个标签类别。


模型概述 决策树是一种依托于策略抉择而建立起来的树。每个分支代表一个属性输出,而每个树叶节点代表类或者类分布。树的顶层是根结点。此处的决策树模型选用基于CART算法进行剪枝。 模型说明 剪枝又分为前剪枝和后剪枝,前剪枝是指在构造树的过程中就知道哪些节点可以剪掉 。 后剪枝是指构造出完整的决策树之后再来考查哪些子树可以剪掉。此处选择前剪枝方法,即限制树的最大深度。主要设置以下两个参数: depth :限制树的最大深度,超过设定深度的树枝全部剪掉。在高纬度低样本量时非常有效,决策树每多生长一层,对样本的需求量会增加一倍。所以限制树的深度有利于防止过拟合。正整数 samples_split:该参数限定,一个节点必须包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分支就不会发生。正整数
模型概述 随机森林旨将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,该算法被称为随机森林算法:基于bagging**的集成学习算法,机器学习器是决策树。适合数据量大,特征多。 模型说明 本项目中随机森林模型主要包括以下参数: estimator:使用决策树个数,即分类器的个数 sample:有放回抽样的每次抽样样本量
模型概述 GBDT模型全名叫梯度提升决策树,是一种迭代的决策树算法,又叫 MART(Multiple Additive Regression Tree),它通过构造一组弱的学习器(树),并把多颗决策树的结果累加起来作为最终的预测输出。该算法将决策树与集成**进行了有效的结合。 GBDT模型的特点为:1、 所有弱分类器的结果相加等于预测值。2、每次都以当前预测为基准,下一个弱分类器去拟合误差函数对预测值的残差(预测值与真实值之间的误差)。3、GBDT的弱分类器使用的是树模型。 模型说明 本项目中GBDT模型主要包括以下参数: estimator:基学习器和决策树数量 lr:学习率 depth :限制树的最大深度,超过设定深度的树枝全部剪掉。在高纬度低样本量时非常有效,决策树每多生长一层,对样本的需求量会增加一倍。所以限制树的深度有利于防止过拟合
模型概述
模型说明 本项目中 XGBoost模型主要包括以下参数: depth :限制树的最大深度,超过设定深度的树枝全部剪掉。在高纬度低样本量时非常有效,决策树每多生长一层,对样本的需求量会增加一倍。所以限制树的深度有利于防止过拟合 estimator:基学习器和决策树数量 sample_b:构建弱学习器时,对特征随机采样的比例,默认值为1
num_epoches (迭代次数):10 batch_size(每次传入模型的特征数量):100 第一层隐藏数量: 64 第二层隐藏数量:16
模型概述 模型说明 num_epoches (迭代次数):10 batch_size(每次传入模型的特征数量):32 hidden_dim (隐藏层特征数量): 64 num_layers (层数): 5 embedding_dim(词向量维度):300 num_classes(预测分类类别):2 split (训练测试集切分比例):0.2
https://github.com/AimeeLee77/senti_analysis 参考 https://github.com/7125messi/sentiment_analysis_from_raw_corpus 优化
模型概述 模型说明 num_epoches (迭代次数):10 batch_size(每次传入模型的特征数量):32 hidden_dim (隐藏层特征数量): 64 num_layers (层数): 5 embedding_dim(词向量维度):300 num_classes(预测分类类别):2 split (训练测试集切分比例):0.2
本项目的代码主要分为机器学习模型和深度学习模型两部分。情感分类预测与时间序列预测在数据处理上的主要差别为情感分类预测需要将分词后的文本转化成数字索引。使用的为人民日报词向量(300维),文件较大可自行搜索下载
机器学习模型主要包括基础机器学习模型和一个keras_lstm模型,以下为代码补充说明: 1、数据处理(datasets.py): 基础机器学习模型处理方式主要为正负语料库切分和创建平均词向量。对于Keras_lstm来说需要首先创建分词所对应的词向量和单词索引,其次对可迭代文本全部转化成数字索引,并建立词向量矩阵以便模型的训练。 2、模型训练(run.py): 通过设置args.py中相应模型选择的参数,对不同模型进行训练。 3、模型预测(predict.py) 训练完后加载模型训练的pkl文件进行待预测文本的分类预测。 同时,此处也给出了在实际部署中,加入了百度智能云的情感分析接口结合每日定时运行所进行的模型迭代的相应处理参考。
机器学习模型主要包括bilstm和bilstm_attention两个模型,同时提供了两种数据处理的方式,以下为代码补充说明: 1、数据处理(dataset.py): 在pytorch框架下,主要借助torch.utils.data下的dataset和dataloader进行模型数据集的创建。在进行完正负语料库切分后,继承dataset类进行定义,此处的处理是直接转化成数字索引。并直接借助torch.nn.utils.rnn里的pad_sequence进行截断。最后送进dataloader类中进行实例化。 2、数据处理2(datasets.py) 此处的处理思路是先建立语料库词汇表,然后对可迭代文本进行数字索引转化同时进行了截断补0。最后继承dataset类定义tensor格式,并送进dataloader类中进行实例化。 3、构建模型(models.py) 时间序列中nn.lstm(input_size,hidden_size,num_layers),这里的input_size对应变量数,即前向传播中传进去的shape为(batch_size,seq_len,input_size)在舆情分析中,由于需要把文本向量化,对于一段文本中每个词的变量数就是embed_size,比如此处选用的人民日报单词向量维度是300,所以embed_size为300。同时seq_len表示文本的截断长度,故前向传播中embeding后的shape为(batchsize,seq_len,embed_size),然后nn.lstm(embed_size,hidden_size,num_layers)。 同时由于此处选择的是batch_sice为False,所以final_hidden_state.shape 是(Dnumlayer,传入顺序的第二个,hidden_dim)。如果选择batch_size为True,那么final_hidden_state.shape会为(Dnumlayer,batch_size,hidden_dim)。 4、模型训练与预测(run.py): 通过设置args.py中相应模型选择的参数,对不同模型进行训练。并选择最佳迭代模型对待预测文本进行分类预测。
在对待预测文本进行完情感分类预测后,基于本项目的初版内容设计,进行了正负情感比例、舆情值及观点提取的应用。详见(apply.py和textrank.py)
在本项目的初版设计中,使用基于文本聚类算法标注的传统情感分析方法,对于给出的一段文本,通常只给出一个最终的情感倾向结果(正面或负面),从而缺失了相当多的信息价值。细粒度情感分析方法优化粗粒度分类标注可以提炼出文本中不同内容蕴含的所有(方面,观点,情感)三元组“信息块”,但需要人为进行一定量的文本手工/半自动标注作为初始训练样本。目前市面上鲜少有较为成熟的标注工具,且不便于进行数据源管理和归档,因此在优化2.0版本中提出了自行开发文本标注功能的需求。
 该工具模块建立及分发不同类型标注任务、多人协同标注以及引入半自动标注,进行数据标准化处理,创建结构化文本数据集,提升后续以保证机器学习和深度学习模型对信息进行感知和深度分析水平。
设计的标注整体框架如下图所示。
该工具模块建立及分发不同类型标注任务、多人协同标注以及引入半自动标注,进行数据标准化处理,创建结构化文本数据集,提升后续以保证机器学习和深度学习模型对信息进行感知和深度分析水平。
设计的标注整体框架如下图所示。
