@TOC
项目说明
本项目为时间序列预测项目,主要重点在于对预测项目整体流程的梳理总结,不同框架下如何进行简单数据处理和模型搭建。因此项目中搭建的主要为一些常用模型(后续会不断修改完善)。模型包含了prophet模型、keras库的bp神经网络和lstm网络模型、pytorch 框架下的lstm相关模型。由于prophet模型和keras库的bp神经网络和lstm网络模型的构建、训练、测试整体代码量较少,将直接各自在一个脚本中完成。而pytorch框架下的模型将对代码块进行拆解。
项目主要环境
prophet模型环境: python=3.6 安装fbprophet keras模型环境: tensorflow=2.9 keras=2.0 pytorch模型环境: python=3.8 torch=1.9.1 cuda=11.1 cudnn=8.6
项目模型介绍
prophet模型
prophet模型是facebook开源的一个时间序列预测算法,适用于具有明显内在规律的时间序列数据,如:季节性趋势明显,有事先知道的重要节假日,有历史趋势变化。此处只为单变量时间序列预测,即选择需要的某一个变量。
模型说明
prophet模型主要包含以下可调参数: day:预测天数,默认值为30 ycl:预测列名,即需要预测的变量列名 本项目中prophet模型构建了预测和误差评估两个主要方法。
模型运行
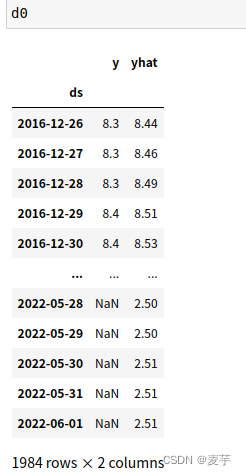
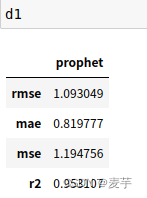
直接运行 prophet.py脚本,d0和d1分别为预测和误差评估两个主要方法的结果:
调用预测方法结果:
keras库
keras库的计算依托于tensorflow框架,由于封装得较好,对于快速构建神经网络模型相较友好,本项目中主要借助keras库构建了基础的bp神经网络和lstm神经网络模型。
bpkeras模型
BP神经网络为最基础的神经网络模型,主要包括前向运算和反向传播。此处指的是keras库下的BP神经网络模型,可方便快速构建神经网路模型,模型结构默认为输入层、中间层和输出层。可实现单变量和多变量时间序列预测。
模型说明
BP模型主要包含以下可调参数: ycls:预测开始列,正整数,非时间列后,从0开始数 ycle:预测结束列,正整数,非时间列后,从1开始 ycl:目标预测列差,整数。若预测结束列-预测开始列为0,为单变量预测,大于0为多变量预测 cut:训练集比例(数字范围:1-10) day:预测下一个目标值将在过去查看的步骤数,默认值为30 srn:输入层单元数 zjn:中间层单元数 本项目中bpkeras模型构建了预测和误差评估两个主要方法。
模型运行
直接运行keras_model.py脚本,其中result1得到的便是bpkeras模型的预测结果和评估结果
lstmkeras模型
LSTM模型在BP神经网络的基础上主要提出了门结构,通过忘记门,输入门,输出门来控制什么样的信息将被遗忘,保存和输出。为了控制一个存储单元,我们需要一些门。其中一个门需要从单元中读出条目(相对于读取任何其他单元而言)。我们将把它称为输出门。第二个门需要决定何时将数据读入单元。我们把它称为输入门。最后,我们需要一个机制来重置单元的内容,由一个遗忘门来管理。这样设计的动机和以前一样,即能够通过一个专门的机制来决定何时记住和何时忽略进入潜伏状态的输入。
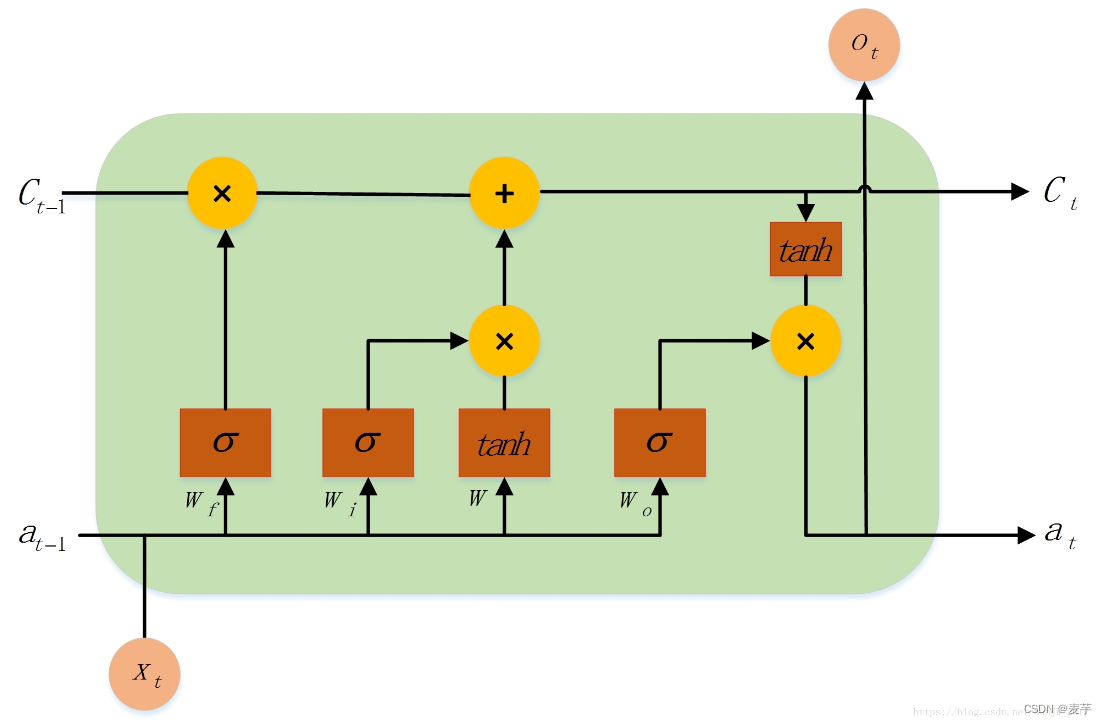
模型说明
lstmkeras模型主要包含以下可调参数: ycls:预测开始列,正整数,非时间列后,从0开始 ycle:预测结束列,正整数,非时间列后,从1开始 ycl:目标预测列差,整数。若预测结束列-预测开始列为0,为单变量预测,大于0为多变量预测 cut:训练集比例(数字范围:1-10) day:预测下一个目标值将在过去查看的步骤数,默认值为30 srn:输入层单元数 zjn:中间层单元数 dropout:正则化,随即丢弃一些神经元,防止过拟合(数字范围在0-1) 本项目中lstmkeras模型主要构建了预测和误差两个方法。
模型运行
直接运行keras_model.py脚本,其中result2得到的便是lstmkeras模型的预测结果和评估结果
pytorch框架
本项目中在pytorch框架下主要搭建了LSTM和BILSTM两个模型,并分别实现了单变量单步预测、多变量单步预测和多变量多步预测三种模式。
BILSTM模型
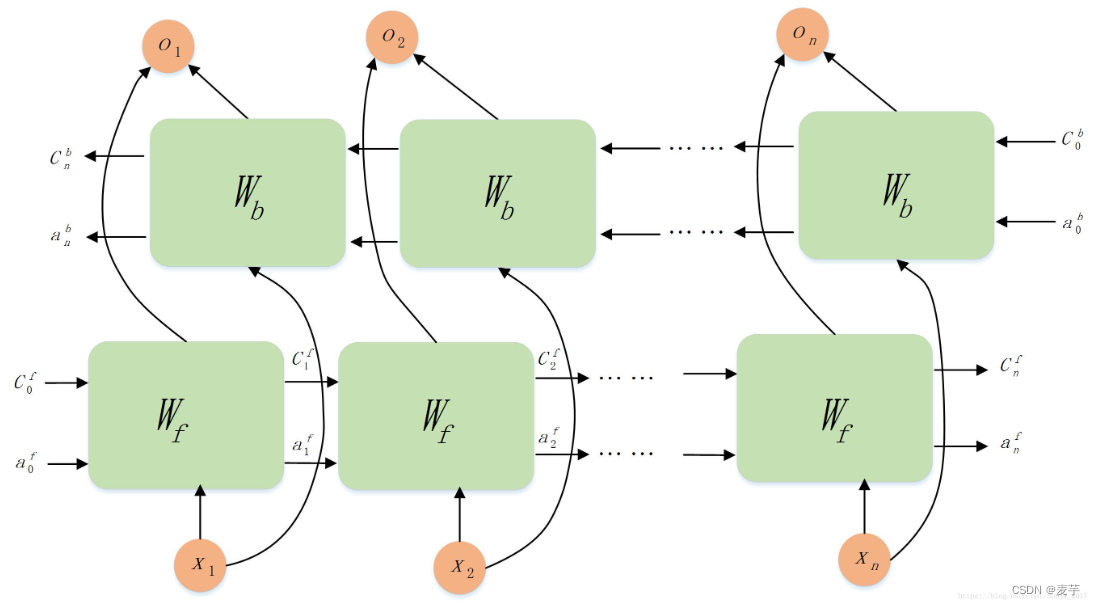
单变量单步预测
单变量单步预测顾名思义是指对单变量的前n个值滚动预测第n+1的值。由于是单变量,在对数据进行归一化操作时,直接采取的平均化方式。
参数说明
在单变量单步预测中主要包含以下可调参数: epochs:模型训练迭代次数,正整数,默认为30 input_size:在时间序列预测中,此处其实是指传入模型中的变量数,正整数,此处为单变量,故默认为1 seq_len:在时间序列预测中,此处其实是指预测值长度,正整数,即上述所提到的n值,默认为30 output_size:在时间序列预测中,此处其实是指待预测值的变量数,此处为单变量,故默认为1 hidden_size:模型隐藏层,正整数,默认为32 num_layers:默认为2 lr:学习率,默认为0.001 optimizer:模型优化器,默认为adam device:此处选择GPU weight_decay:为防止模型过拟合的权重衰减,默认为0.0001 bidirectional:是否选择双向LSTM step_size:调整学习率间隔,间隔单位是epoch。等间隔调整学习率 StepLR, 将学习率调整为 lr*gamma gamma:学习率调整倍数,默认为 0.1 倍,即下降 10 倍 yucel:预测列,正整数,从0开始 train_split:训练集切分比例,0-1间的小数 test_split:测试集开始切分的比例,0-1间的小数 df:数据位置 day:预测天数 method:方法,输入'yuce'表示预测方法,输入’es‘表示评估方法。
补充说明
1、先得到已转化成Dataloader格式的训练测试验证集数据,传入前的seq中train_seq的shape为(seq_len,input_size),train_label的shape为(output_size) 2、在本项目中,由于默认了batch_fist=True,故传入lstm模型中的x的shape为(batch_size,seq_len,input_size)
模型运行
直接运行univariate_single_step.py脚本文件,输出结果根据预测方法可以输出预测结果和评估参数。如需修改参数在args.py里us_args_parser函数里修改。
多变量单步预测
单变量单步预测是指对多变量(包括预测列)的前n个值滚动预测 预测列第n+1的值。此处使用的数据归一方式为MinMaxScaler。需要注意是预测数据应为连续列,且最后一列为预测列。
参数说明
在单变量单步预测中主要包含以下可调参数: epochs:模型训练迭代次数,正整数,默认为30 input_size:在时间序列预测中,此处其实是指传入模型中的变量数,正整数,此处为多变量,故默认为3 seq_len:在时间序列预测中,此处其实是指预测值长度,正整数,即上述所提到的n值,默认为30 output_size:在时间序列预测中,此处其实是指待预测值的变量数,此处为单变量,故默认为1 hidden_size:模型隐藏层,正整数,默认为32 num_layers:默认为2 lr:学习率,默认为0.001 optimizer:模型优化器,默认为adam device:此处选择GPU weight_decay:为防止模型过拟合的权重衰减,默认为0.0001 bidirectional:是否选择双向LSTM step_size:调整学习率间隔,间隔单位是epoch。等间隔调整学习率 StepLR, 将学习率调整为 lr*gamma gamma:学习率调整倍数,默认为 0.1 倍,即下降 10 倍 yucestart:预测开始列,正整数,从0开始 yuceend:预测结束列,正整数,从0开始,默认结束列为需预测列 train_split:训练集切分比例,0-1间的小数 test_split:测试集开始切分的比例,0-1间的小数 df:数据位置 predict_df:待预测数据配置 day:预测天数 method:方法,输入'yuce'表示预测方法,输入’es‘表示评估方法。
补充说明
1、先得到已转化成Dataloader格式的训练测试验证集数据,传入前的seq中train_seq的shape为(seq_len,input_size),train_label的shape为(output_size) 2、在本项目中,由于默认了batch_fist=True,故传入lstm模型中的x的shape为(batch_size,seq_len, batch_size,seq_len,input_size) 3、在预测时,需要将预测结果先进行维度扩充再进行逆变化,同时注意对应关系。
模型运行
直接运行multivariate_single_step.py脚本文件,输出结果根据预测方法可以输出预测结果和评估参数。如需修改参数在args.py里ms_args_parser函数里修改。
多变量多步预测
多变量多步预测是指对多变量(包括预测列)的前n个值滚动预测 预测列第(n+1)至(n+num)的值。此处使用的数据归一方式为MinMaxScaler。需要注意是预测数据应为连续列,且最后一列为预测列。
参数说明
在单变量单步预测中主要包含以下可调参数: epochs:模型训练迭代次数,正整数,默认为30 input_size:在时间序列预测中,此处其实是指传入模型中的变量数,正整数,此处为多变量,故默认为3 seq_len:在时间序列预测中,此处其实是指预测值长度,正整数,即上述所提到的n值,默认为30 output_size:在时间序列预测中,此处其实是指待预测值的变量数,此处为单变量,故默认为3 hidden_size:模型隐藏层,正整数,默认为32 num_layers:默认为2 lr:学习率,默认为0.001 optimizer:模型优化器,默认为adam device:此处选择GPU weight_decay:为防止模型过拟合的权重衰减,默认为0.0001 bidirectional:是否选择双向LSTM step_size:调整学习率间隔,间隔单位是epoch。等间隔调整学习率 StepLR, 将学习率调整为 lr*gamma gamma:学习率调整倍数,默认为 0.1 倍,即下降 10 倍 yucestart:预测开始列,正整数,从0开始 yuceend:预测结束列,正整数,从0开始,默认结束列为需预测列 train_split:训练集切分比例,0-1间的小数 test_split:测试集开始切分的比例,0-1间的小数 df:数据位置 predict_df:待预测数据配置 day:预测天数 method:方法,输入'yuce'表示预测方法,输入’es‘表示评估方法。
补充说明
1、先得到已转化成Dataloader格式的训练测试验证集数据,传入前的seq中train_seq的shape为(seq_len,input_size),train_label的shape为(output_size) 2、在本项目中,由于默认了batch_fist=True,故传入lstm模型中的x的shape为(batch_size,seq_len, batch_size,seq_len,input_size) 3、在预测时,需要将预测结果先进行维度扩充再进行逆变化,同时注意对应关系.
模型运行
直接运行multivariate_multi_step.py脚本文件,输出结果根据预测方法可以输出预测结果和评估参数。如需修改参数在args.py里ms_args_parser函数里修改。
参考说明
本项目中的pytorch模型部分代码参考: https://github.com/ki-ljl/LSTM-Load-Forecasting 基于此,主要对train_seq相关数据处理方式进行了修改,并在此基础上增加了三种模型的未来值预测实现。