fork from: https://github.com/QingyongHu/RandLA-Net.git 作者:https://zhuanlan.zhihu.com/p/105433460
Python 3.6, Tensorflow 2.6, CUDA 11.4 and cudnn ( /usr/local/cuda-11.4 没有用 conda 的cudatoolkit)
git clone --depth=1 https://github.com/luckyluckydadada/randla-net-tf2.git
conda create -n randlanet python=3.6
conda activate randlanet
pip install tensorflow-gpu==2.6 -i https://pypi.tuna.tsinghua.edu.cn/simple --timeout=120
pip install -r helper_requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --timeout=120
sh compile_op.sh
ls /home/$USER/data/S3DIS/Stanford3dDataset_v1.2_Aligned_Version
python utils/data_prepare_s3dis.py
ConfigS3DIS:
k_n = 16 # KNN
num_layers = 5 # Number of layers
num_points = 40960 # Number of input points
num_classes = 13 # Number of valid classes
sub_grid_size = 0.04 # preprocess_parameter
batch_size = 6 # batch_size during training
val_batch_size = 20 # batch_size during validation and test
train_steps = 500 # Number of steps per epochs
val_steps = 100 # Number of validation steps per epoch
sub_sampling_ratio = [4, 4, 4, 4, 2] # sampling ratio of random sampling at each layer
d_out = [16, 64, 128, 256, 512] # feature dimension
noise_init = 3.5 # noise initial parameter
max_epoch = 100 # maximum epoch during training
learning_rate = 1e-2 # initial learning rate lr_decays = {i: 0.95 for i in range(0, 500)} # decay rate of learning rate
train_sum_dir = 'train_log'
saving = True
saving_path = None
python -B main_S3DIS.py --gpu 0 --mode train --test_area 1 表示:
Area2-3-4-5-6共228个ply文件作为训练集
Area1共44个ply文件作为验证集
下面为6折交叉验证:
cat jobs_6_fold_cv_s3dis.sh
python -B main_S3DIS.py --gpu 0 --mode train --test_area 1 # Area23456作为训练集,area1作为验证集
python -B main_S3DIS.py --gpu 0 --mode test --test_area 1
python -B main_S3DIS.py --gpu 0 --mode train --test_area 2
python -B main_S3DIS.py --gpu 0 --mode test --test_area 2
python -B main_S3DIS.py --gpu 0 --mode train --test_area 3
python -B main_S3DIS.py --gpu 0 --mode test --test_area 3
python -B main_S3DIS.py --gpu 0 --mode train --test_area 4
python -B main_S3DIS.py --gpu 0 --mode test --test_area 4
python -B main_S3DIS.py --gpu 0 --mode train --test_area 5
python -B main_S3DIS.py --gpu 0 --mode test --test_area 5
python -B main_S3DIS.py --gpu 0 --mode train --test_area 6
python -B main_S3DIS.py --gpu 0 --mode test --test_area 6
论文里说,RandLA-Net是一个完全端到端的网络架构,能够将整个点云作为输入,而不用拆分、合并等预处理、后处理操作。但是我在阅读代码的时候,发现网络在获取数据的部分,采用的是和KPConv类似的思路:先随机选择一个train文件,在文件中随机选择一批中心点,然后在这些中心点周围用KNN的方法选择K个点,作为一个batch训练所需的点云。我看代码里确实是这样做的,感觉和论文里说的有点出入,不知道是不是我理解的有问题。 对于 Semantic 3D 数据集,代码里先对原始点云进行 grid_size=0.01 的采样,得到点云1,然后对点云1进行 grid_size=0.06 的采样,得到点云2,最后对点云2进行学习。而最后test的时候,网络只把特征传播到点云1,意思就是语义分割的结果只预测到了点云1,并没有预测原始点云的分割结果,所以就对这里产生了一些疑问。S3DIS就没有这个问题,最后预测的是原始点云的语义分割结果。
label python main_S3DIS.py --mode vis --test_area 1 origin python vis_S3DIS.py
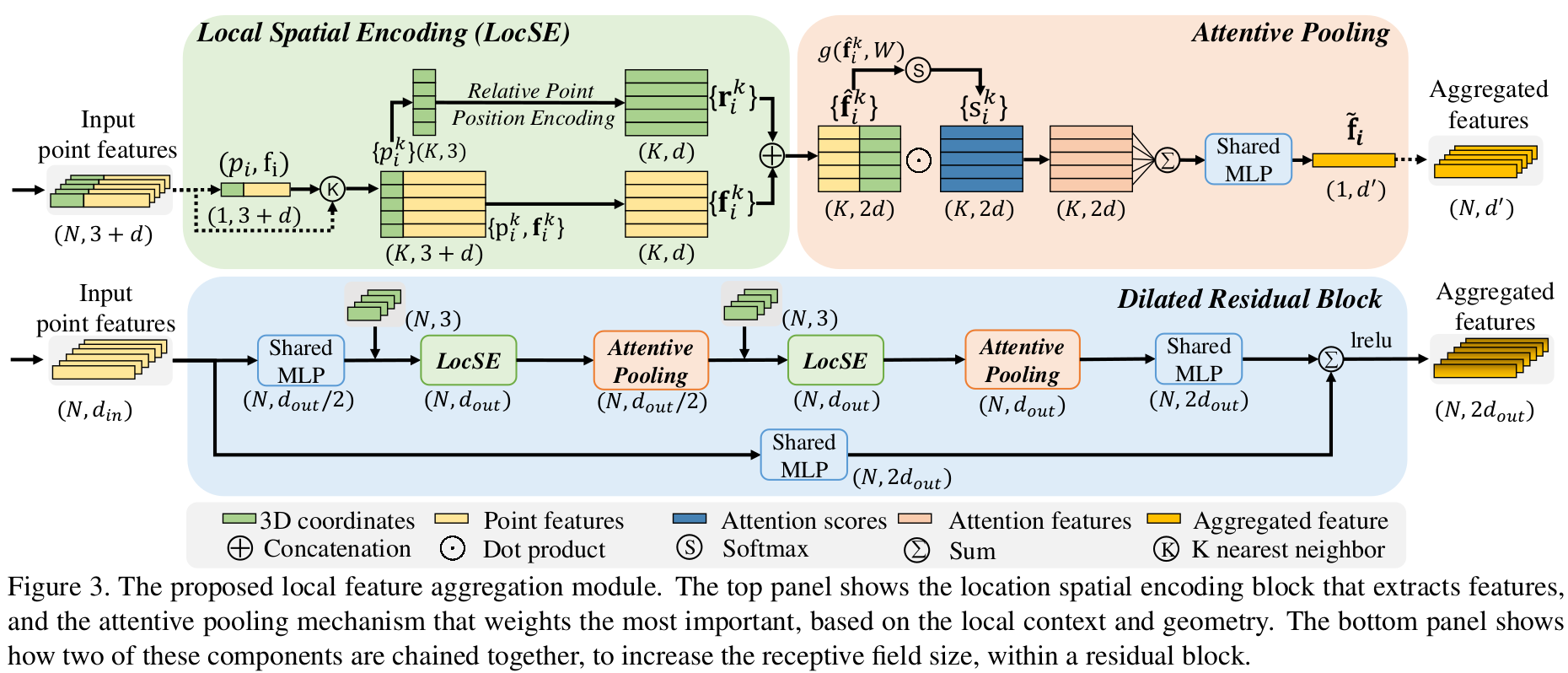
helper_tf_util.py 封装了一些卷积池化操作代码 helper_tool.py 有训练时各个数据集所用到的一些参数信息,还有一些预处理数据时的一些模块。 main_.py 训练对应数据的主文件 RandLANet.py 定义网络的主题结构 tester_.py 测试对应数据的文件,该文件在main_.py中被调用 utils 对数据集预处理的模块以及KNN模块。 utils/data_prare_.py 预处理,把point和label做了grid sampling,并且生成了一个kdtree保存下来
将特征升维到8 encoder:由4个(dilated_res_block+random_sample)构成,形成特征金字塔 将金字塔尖的特征再次计算以下 decoder:由4个(nearest_interpolation+conv2d_transpose)构成,恢复到point-wise的特征 由point-wise经过一些MLP,得到f_out
This is the official implementation of RandLA-Net (CVPR2020, Oral presentation), a simple and efficient neural architecture for semantic segmentation of large-scale 3D point clouds. For technical details, please refer to:
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Qingyong Hu, Bo Yang*, Linhai Xie, Stefano Rosa, Yulan Guo, Zhihua Wang, Niki Trigoni, Andrew Markham.
[Paper] [Video] [Blog] [Project page]
This code has been tested with Python 3.5, Tensorflow 1.11, CUDA 9.0 and cuDNN 7.4.1 on Ubuntu 16.04.
- Clone the repository
git clone --depth=1 https://github.com/QingyongHu/RandLA-Net && cd RandLA-Net
- Setup python environment
conda create -n randlanet python=3.5
source activate randlanet
pip install -r helper_requirements.txt
sh compile_op.sh
Update 03/21/2020, pre-trained models and results are available now.
You can download the pre-trained models and results here.
Note that, please specify the model path in the main function (e.g., main_S3DIS.py) if you want to use the pre-trained model and have a quick try of our RandLA-Net.
S3DIS dataset can be found
here.
Download the files named "Stanford3dDataset_v1.2_Aligned_Version.zip". Uncompress the folder and move it to
/data/S3DIS.
- Preparing the dataset:
python utils/data_prepare_s3dis.py
- Start 6-fold cross validation:
sh jobs_6_fold_cv_s3dis.sh
- Move all the generated results (*.ply) in
/testfolder to/data/S3DIS/results, calculate the final mean IoU results:
python utils/6_fold_cv.py
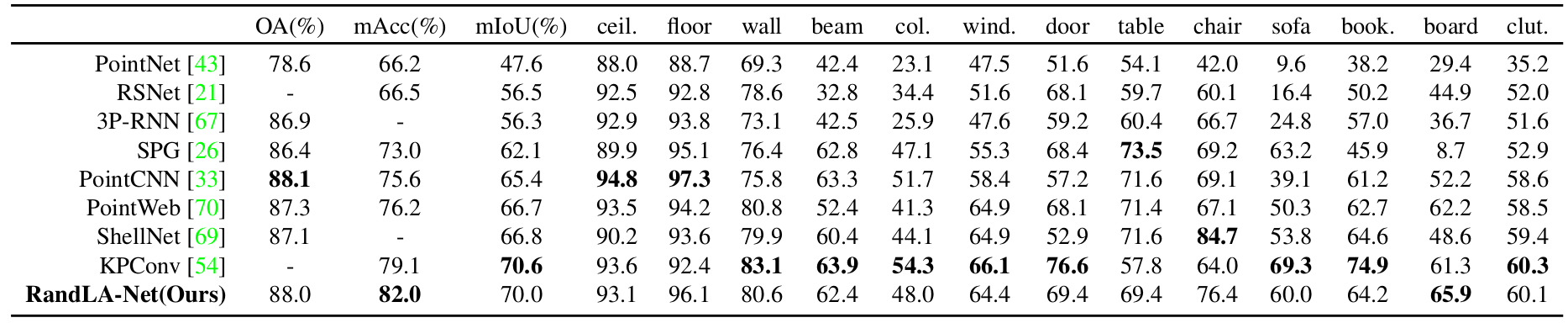
Quantitative results of different approaches on S3DIS dataset (6-fold cross-validation):
Qualitative results of our RandLA-Net:
 |
 |
|---|
7zip is required to uncompress the raw data in this dataset, to install p7zip:
sudo apt-get install p7zip-full
- Download and extract the dataset. First, please specify the path of the dataset by changing the
BASE_DIRin "download_semantic3d.sh"
sh utils/download_semantic3d.sh
- Preparing the dataset:
python utils/data_prepare_semantic3d.py
- Start training:
python main_Semantic3D.py --mode train --gpu 0
- Evaluation:
python main_Semantic3D.py --mode test --gpu 0
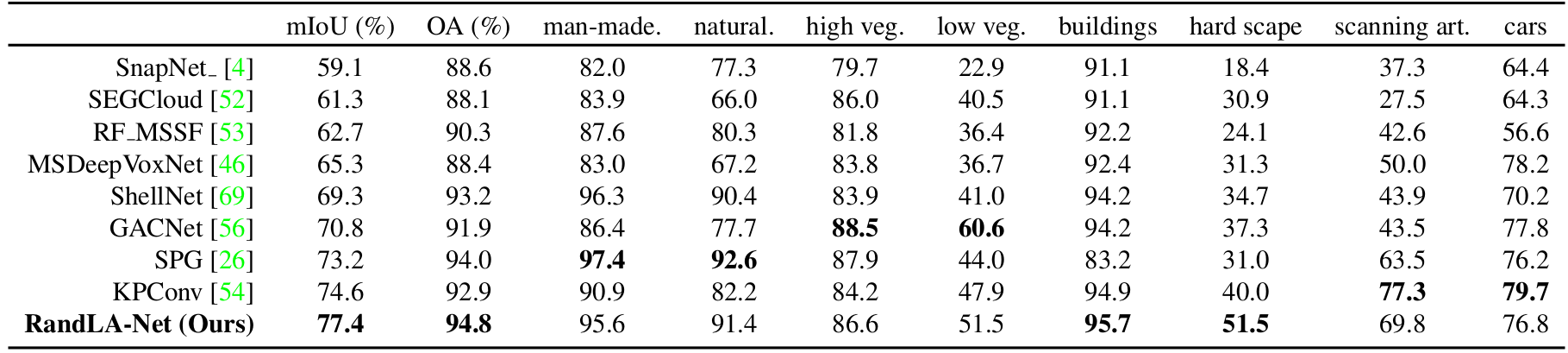
Quantitative results of different approaches on Semantic3D (reduced-8):
Qualitative results of our RandLA-Net:
 |
 |
|---|---|
 |
 |
Note:
- Preferably with more than 64G RAM to process this dataset due to the large volume of point cloud
SemanticKITTI dataset can be found here. Download the files
related to semantic segmentation and extract everything into the same folder. Uncompress the folder and move it to
/data/semantic_kitti/dataset.
- Preparing the dataset:
python utils/data_prepare_semantickitti.py
- Start training:
python main_SemanticKITTI.py --mode train --gpu 0
- Evaluation:
sh jobs_test_semantickitti.sh
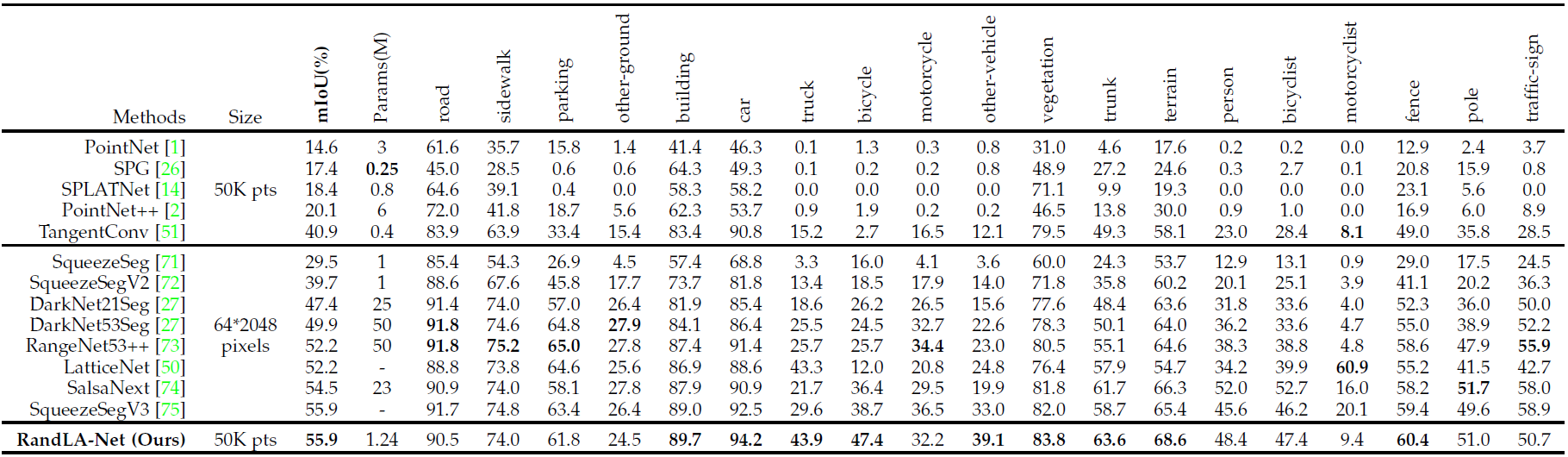
Quantitative results of different approaches on SemanticKITTI dataset:
Qualitative results of our RandLA-Net:


If you find our work useful in your research, please consider citing:
@article{hu2019randla,
title={RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds},
author={Hu, Qingyong and Yang, Bo and Xie, Linhai and Rosa, Stefano and Guo, Yulan and Wang, Zhihua and Trigoni, Niki and Markham, Andrew},
journal={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2020}
}
@article{hu2021learning,
title={Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling},
author={Hu, Qingyong and Yang, Bo and Xie, Linhai and Rosa, Stefano and Guo, Yulan and Wang, Zhihua and Trigoni, Niki and Markham, Andrew},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2021},
publisher={IEEE}
}
- Part of our code refers to nanoflann library and the the recent work KPConv.
- We use blender to make the video demo.
Licensed under the CC BY-NC-SA 4.0 license, see LICENSE.
- 21/03/2020: Updating all experimental results
- 21/03/2020: Adding pretrained models and results
- 02/03/2020: Code available!
- 15/11/2019: Initial release!
- SoTA-Point-Cloud: Deep Learning for 3D Point Clouds: A Survey
- SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds
- 3D-BoNet: Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds
- SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration
- SQN: Weakly-Supervised Semantic Segmentation of Large-Scale 3D Point Clouds with 1000x Fewer Labels




