Material and links:
In this project, as part of the Udacity ML Devops Nanodegree, the goal was to develop and deploy a simple ML application to serve a simple ML model with a REST API by FastAPI and served as a dyno on Heroku.
In this project, the overall project focus was to develop the wrapping around the ML model, including the API and CI/CD pipeline. The model and its performance was not important.
The following tools create the stack for the pipeline:
- [Github] as code base repository, including the versioning of code and used for continous integration (CI) testing via Github Actions
- [Data Version Control (DVC)] a framework to track ML artifacts (data, models) on remote storage (S3, GDrive, etc.)
- [Heroku] as platform as a service (PaaS), to enable continous deployment (CD) for this repo
- [Scikit-learn] a modeling framework for machine learning models
- [pytest] a python test module, to do python tests
- [flake8] a python test module, to ensure clean code
in the following a simplified version of the code base structure is described:
.
├── README.md: this readme
├── .dvc: includes the configuration for the DVC remote storage
├── .github: includes the CI defition for Github Actions
├── Procfile: a file that specifies the CD deployment on heroku
├── data: contains the DVC tracked data files
├── doc: contains instructions and screenshots
├── live_post.py: a test file, to test a running deployment on heroku
├── main.py: the main file for the REST API
├── model: contains model files (model, encoder, binarizer) and test performances
├── model_card_template.md: a model description according to the 'Model Card Paper' (https://arxiv.org/pdf/1810.03993.pdf)
├── notebooks: contains JupyterLab notebooks used during development
├── predictor: contains the code for model training
│ └── ml
│ ├── data.py: data methods used
│ ├── model.py: the model specification and methods
│ └── train_model.py: the main training file
├── requirements.txt: specifies application requirements for pip
└── tests: contains test for API and training methodsThis project is not intended to run locally, since it was developed to run in CD. However, if you want to run it locally, follow these steps:
-
You need pip installed, preferably in Linux, or in WSL on Windows
-
Install the project requirements:
> pip install -r requirements.txt
You can now run local test and formatting checks with pytest and flake8
> pytest -vv
> flake8 .To initiate a training, pull the data from DVC (login required, ask me for access) and run the provided FastAPI app locally:
> dvc pull
> uvicorn main:app --reloadThis serves the endpoints "/" and "/invoke" on http://localhost:8000.
Check out the docs on http://localhost:8000/docs.
The following images are required to fulfill the project requirements:
-
DVC: 4 files (data, data cleaned, model and encoder) are tracked with DVC
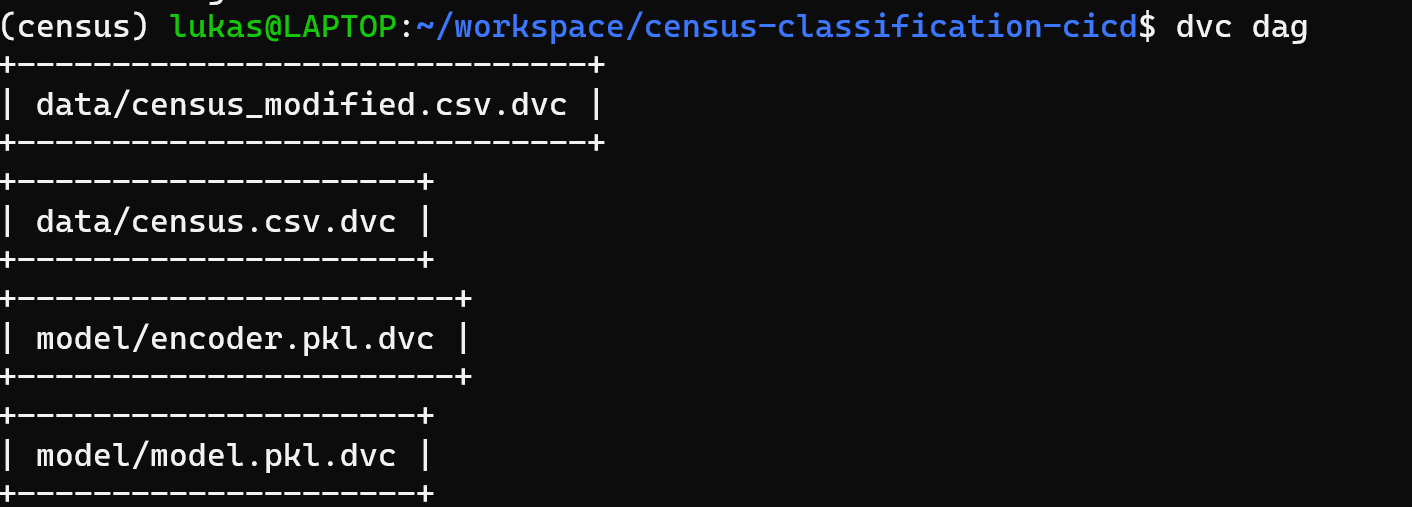
-
CI: A Github action specification was added to the repo and run successfully
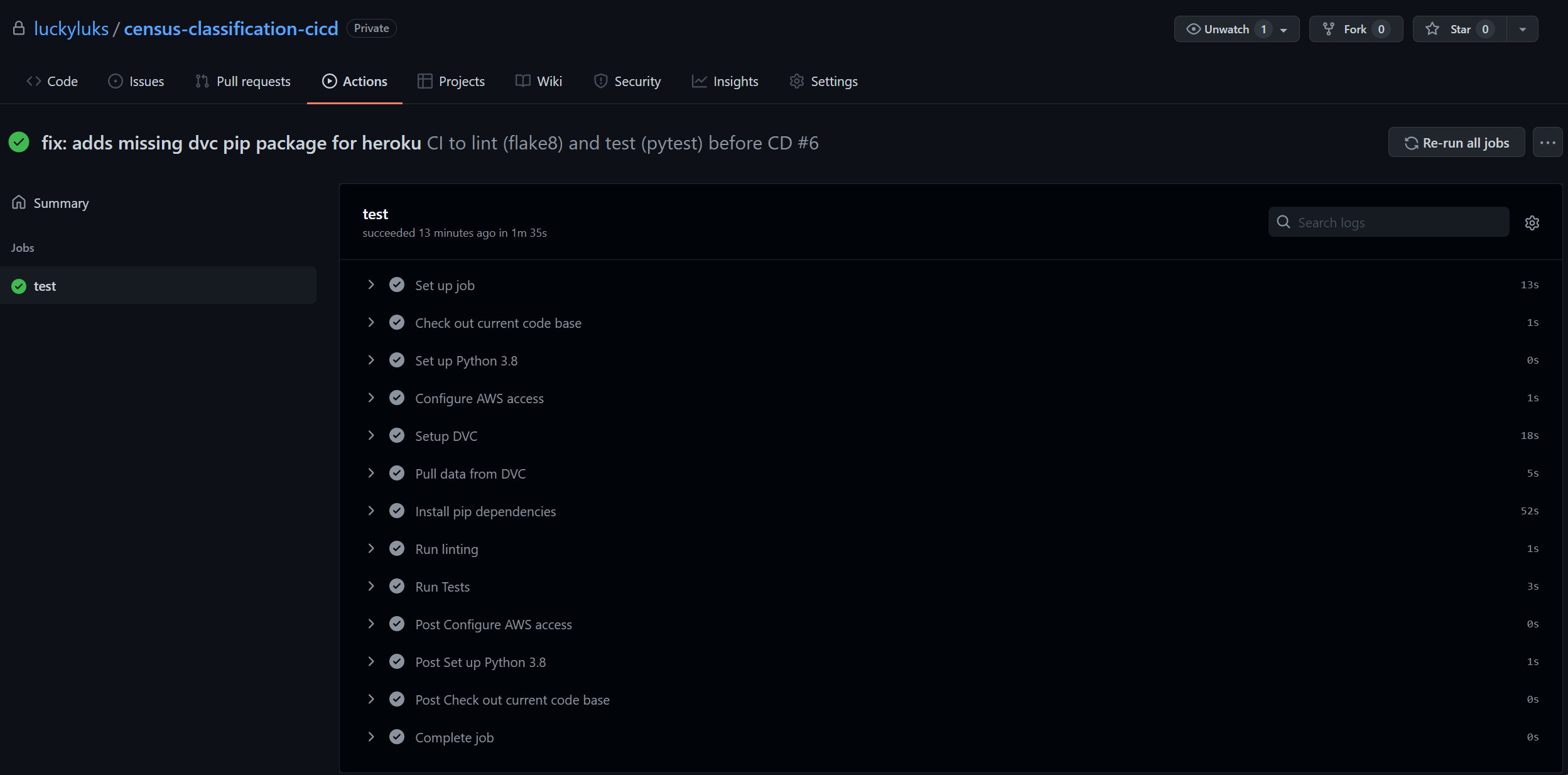
-
CD: A Heroku app was created and connected to the github repo, including successful CI runs. The app is available here
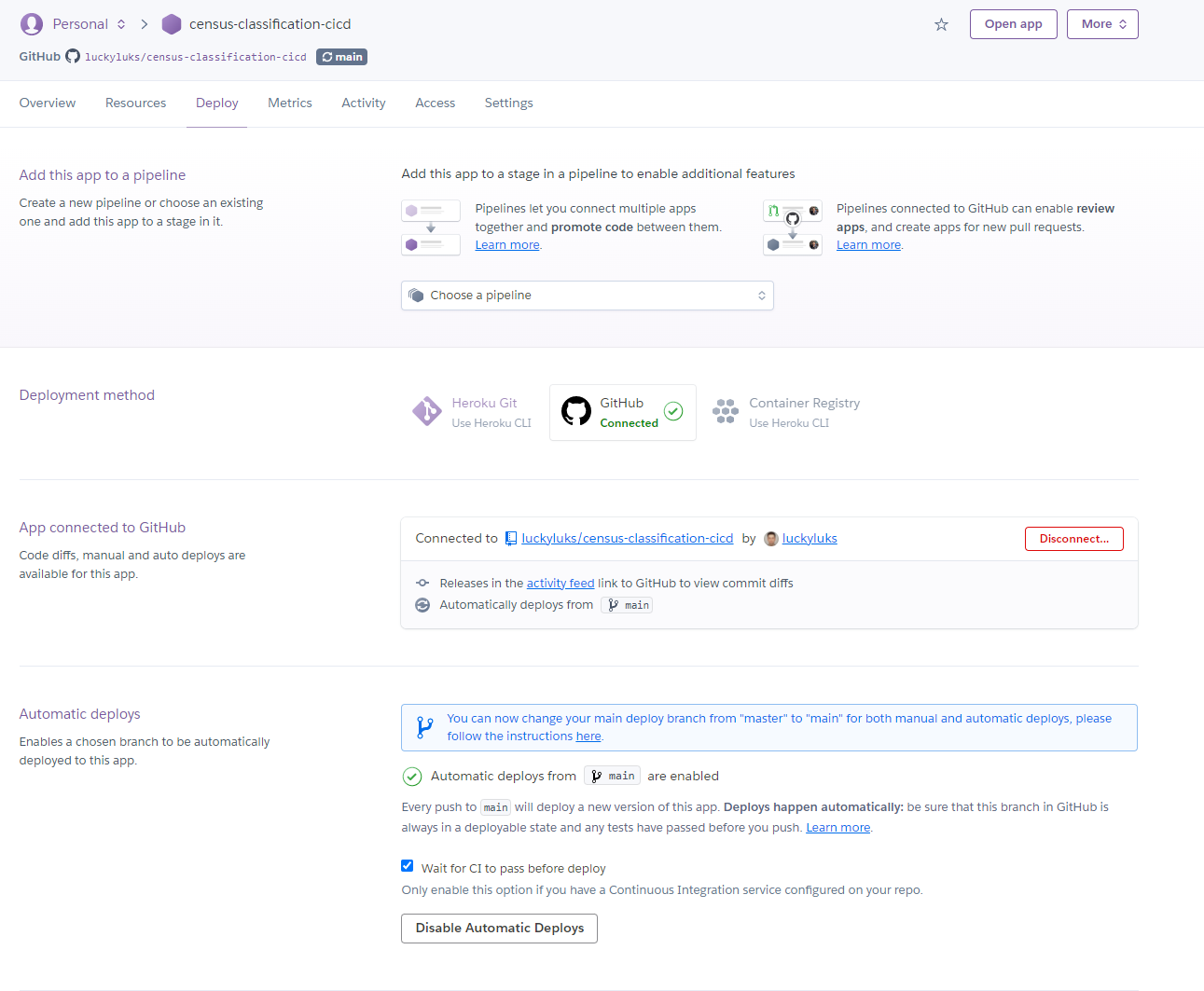
-
FastAPI: The created and served fastAPI app has an integrated API documentation under
/docswhere an example can be found, via python type hints and pydantic model classes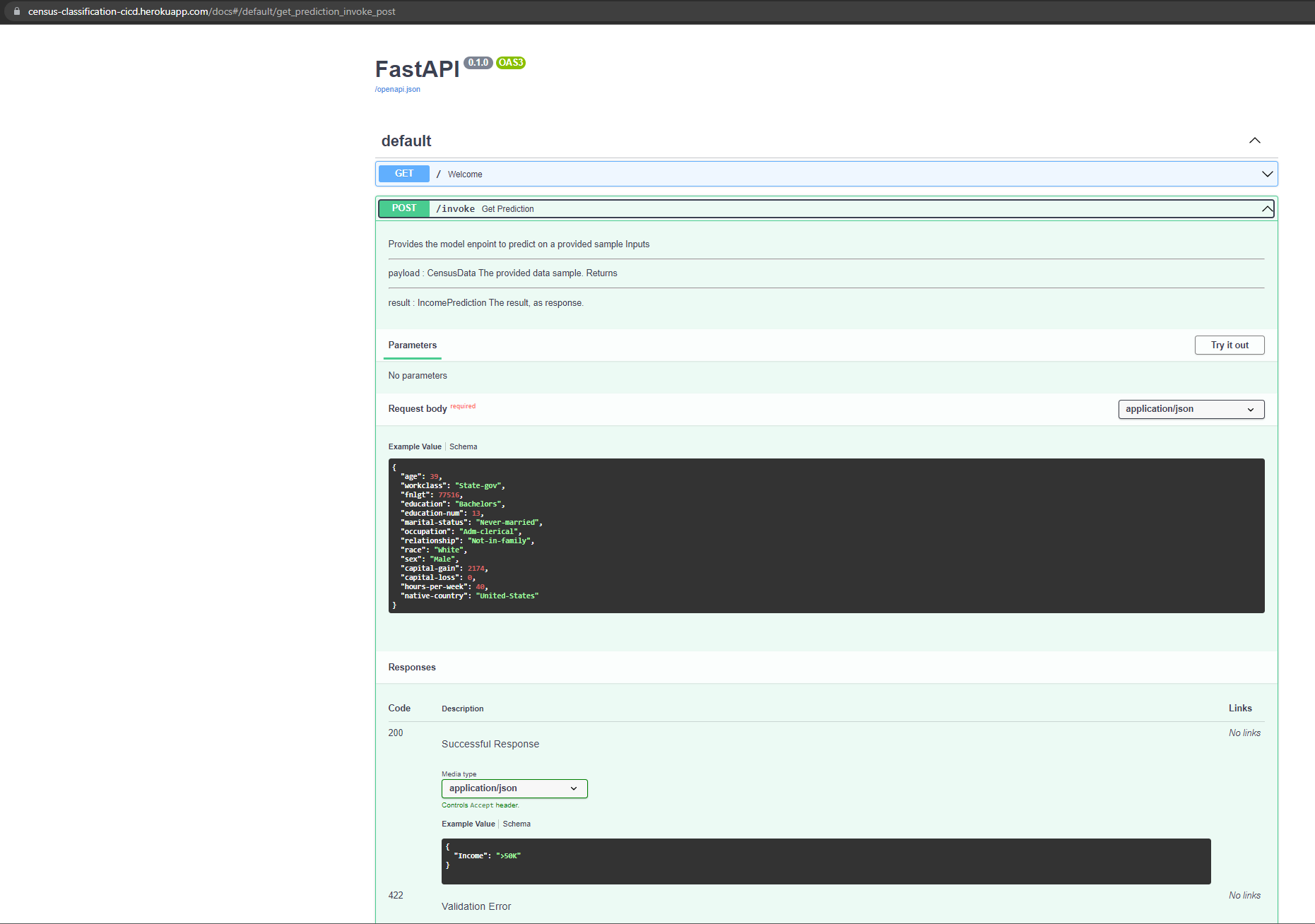
-
LIVE (GET): The created fastAPI app is served successfully and displays the welcome greeting on the root endpoint

-
LIVE (POST): The created fastAPI app is served successfully, the defined enpoint
/invokeinvokes a call to the served ML model, in order to pass provided JSON data as input and returns the prediction with a status code of200






The ML application including training and serving a ML model was developed. Once trained, the repo is tested with CI of Github actions and runs with CD on heroku. The app is available here
As the focus on this project was to develop the CI/CD around a ML model for the given problem, the explorative part could be improved as the following, to improve the overall performance of the models on the problem:
- Do an EDA, with graphs, deeper insight in distributions, construct features
- Test out other models or even other ML/DL frameworks