Deeplabv3_Pytorch
- 基于矿区无人机影像的地物提取实验
1. 实验数据介绍
- 一副无人机拍摄的高分辨率矿区影像图
- 实验室进行标注的对应label
- v0219版本:进行裁剪后的640 x 640的图像与label数据
- v0225&v0301版本及之后:进行裁剪后的320 x 320的图像与label数据,并更换测试集
2. 实验环境介绍
- GPU等服务器资源不加介绍
- Python3.6、Pytorch、OpenCV、torchvision、numpy等必备环境
- 图像切割工具包GDAL:仅在win系统下可运行
3. 实验流程介绍
- 原图数据和标注好的label数据,label是灰度的图像,且每个像素属于该类(0-3)共四类
- 切割原图和相应的label数据为640 x 640的图像,后期改为320大小进行实验
- 将切割好的原图和label对应好,使用代码进行可视化(因为标注的label是灰度,直观上看是黑色一片)
- 对数据进行数据增强,切割完成才有对应的几百张数据,增强至几千张
- 增强后的数据也要一对一对应好,建议一开始就取两者相同的图像名,使用可视化进行测试
- 数据划分,分为训练集、验证集、测试集;按照6:2:2的比例
- 搭建网络代码,使用Pytorch搭建deeplabv3网络(基于ResNet),后期加入多种trick进行测试
- 编写train.py训练代码,写好训练流程、保存模型、保存loss等信息
- 训练完成之后,使用保存的模型进行预测,对预测出的图片进行涂色,使之可视化
- 根据预测结果进行kappa系数、mIoU指标的计算
4. 实验部分代码简介
- 数据简介:以一张大图和对应的label为例,可视化label以便查看原始数据
- 数据切割:介绍有关tif文件的切割,以及转换tif格式为png格式
- 灰度label可视化:由于label是1通道的图像,直观上是黑色图像,写代码使得同类别像素一个颜色进行可视化
- 数据增强_Data_Augmentation.py:离线数据增强,对图像进行随机旋转、颜色抖动、高斯噪声处理;
- 数据载入及数据划分:v0304版本之前的数据载入方式,使用简单留出法划分训练集、验证集
- 基于k折交叉验证方式的数据载入及数据划分:基于k折交叉验证,避免了因偶然因素引起的验证集的不同(验证集随机划分,每次实验结果都会有影响)
- deeplabv3.py:基于pytorch的deeplab_v3网络搭建代码
- deeplabv3论文笔记:论文Rethinking Atrous Convolution for Semantic Image Segmentation的阅读笔记
- train.py:v0304版本之前训练程序的代码,基于简单留出验证
- train_kfold.py:基于交叉验证方式的训练程序的代码
- predictv0217.py:使用生成的训练模型来预测,并给预测图片进行涂色显示
- MIoU指标计算:使用PyTorch基于混淆矩阵计算MIoU、Acc、类别Acc等指标
- Kappa系数计算:使用PyTorch基于混淆矩阵计算Kappa系数评价指标
5. 实验版本数据记录
- 本实验有多个版本,具体实验详情如下:
- 使用图像增强进行训练集的生成,640大小的图像:训练集1944张、验证集648张、测试集162张
- v0225版本&v0301版本,320大小的图像:训练集9072张、验证集2268张、测试集378张
- 图像的预处理:无标准化、只进行了归一化
- 损失函数:CrossEntropyLoss
- 优化器:SGD、lr=1e-3、动量=0.9; v0219版本测试Adam优化器、lr=1e-3
- v0225版本&v0301版本:Adam优化器、lr=1e-3
- v0225版本:deeplabv3-resnet152
- v0301版本:deeplabv3-resnet50
- v0304版本:deeplabv3-resnet152,将简单留出验证改为5折交叉验证
- V3p-101: deeplabv3+-resnet101 + 5折交叉验证
- V3p-152: deeplabv3+-resnet152 + 5折交叉验证
- DANet_res:danet-resnet152 + 5折交叉验证
- Deeplabv3_dan:deeplabv3-dan-resnet152 + 5折交叉验证
- CCNet0403:ccnet-resnet152 + 5折交叉验证
- CCNet0509:deeplabv3-ccnet-resnet152 +5折交叉验证
5.1 一些有关实验改进的新想法
- Pytorch求出所以训练图像的mean和std值,加入实验
- 存在疑问:见到的标准化都是采用的在线数据增强,离线增强数据该如何使用该tips
- 数据增强加入随机裁剪操作,并双线性插值pad至320大小(不能pad,标签pad就不是真实值),投入训练
- 随机裁剪数据至192大小,没有pad,和320大小的数据一起当做训练集,出现错误提示:一个batch的数据,[B,C,H,W]必须一致,由于320和192大小的数据掺杂,所以报错。因为实验使用离线的数据增强
- 因数据集中,地面样本占比最大,而道路占比较少,想测试使用Focal-Loss替换Cross Entropy-Loss
- 使用CCNet单独训练
- v0403版本:只使用了ccnet注意力模块的输出上采样,结果为不收敛,但是使用epoch-8.pth测试有点效果
- 后期测试:将x与x_dsn特征融合,进行测试,测试结果如下,可以看出较danet单独训练结果稍好,车辆acc例外
- CCNet与deeplabv3共同使用,将注意力模块加入deeplabv3
- v0509版本:将ccnet模块与aspp模块并行,cat两个结果,最后进行分割。整体Acc、MIoU、Kappa都达到了最高
- v0509版本:只有道路和车辆的准确率低于以往的实验
- DAN网络单独训练
- danet_drn_v0408版本:output包括feat_sum、pam_out、cam_out,采用辅助loss训练,结果一塌糊涂
- danet_v0408版本:更换backbone网络为resnet-152,替换deeplabv3的aspp模块,不使用辅助loss,使用feat_sum进行结果的分割,结果详见下表Danet0408
- DAN模块并行加入deeplabv3网络中,实验数据如下所示
- 将deeplabv3的backbone网络Resnet换为ResNeSt,目前测试版本:resnest-v0518
- 此版本:根据代码修改,去除aspp后的层,模仿deeplabv3-resnet进行修改,效果一般,仅仅提升了道路的识别
- 根据@张航作者的代码进行更改得出,deeplabv3-resnest,未测试
- 目前的实验目标:提高车辙的识别率(道路的标注中,有一部分是车轮轧过的车辙),最怀疑是数据量不够
5.2 test测试数据集-v0219
5.2.1 SGD与Adam整体平均像素acc及miou对比-下为Adam
| acc | MIoU |
|---|---|
| 0.9263767325704164 | 0.4807448577750288 |
| 0.9337385405707201 | 0.47286513489126114 |
5.2.2 类别平均像素acc-v0219
| 类别 | SGD | Adam |
|---|---|---|
| 地面 | 0.9280041488314654 | 0.9393157770328366 |
| 房屋 | 0.8031034186590591 | 0.8322606620969475 |
| 道路 | 0.522966884580534 | 0.7378283121400184 |
| 车辆 | 0.6060759535374916 | 0.7527768185633605 |
5.2 test测试数据集-各版本结果对比
| 版本&指标 | Acc | MIoU | Kappa | 地面 | 房屋 | 道路 | 车辆 |
|---|---|---|---|---|---|---|---|
| V0225 | 0.9562 | 0.7864 | 0.8477 | 0.9847 | 0.8531 | 0.8898 | 0.7269 |
| V0301 | 0.9545 | 0.7740 | 0.8429 | 0.9815 | 0.8849 | 0.9037 | 0.6313 |
| V0304 | 0.9555 | 0.7777 | 0.8470 | 0.9816 | 0.8529 | 0.9086 | 0.7151 |
| V3p-101 | 0.9544 | 0.7706 | 0.8427 | 0.9785 | 0.8704 | 0.9165 | 0.5758 |
| V3p-152 | 0.9525 | 0.7582 | 0.8317 | 0.9860 | 0.8235 | 0.9111 | 0.6009 |
| Danet0408 | 0.9294 | 0.6762 | 0.7347 | 0.9818 | 0.5991 | 0.8409 | 0.4458 |
| Danet0420 | 0.9497 | 0.7611 | 0.8276 | 0.9732 | 0.8232 | 0.9101 | 0.6559 |
| CCnet0403 | 0.9412 | 0.6846 | 0.7845 | 0.9876 | 0.7803 | 0.9252 | 0.4353 |
| CCnet0509 | 0.9593 | 0.7947 | 0.8593 | 0.9863 | 0.8818 | 0.8856 | 0.6740 |
| ResNeSt0518 | 0.9437 | 0.7143 | 0.8057 | 0.9765 | 0.8315 | 0.9184 | 0.4154 |
6. 实验分割结果展示
-
v0304版本实验结果:原图、label、预测;三者对比如下:
-
Danet0420版本实验结果:原图、label、预测;三者对比如下:
-
CCNet版本实验结果:原图、label、预测;三者对比如下:

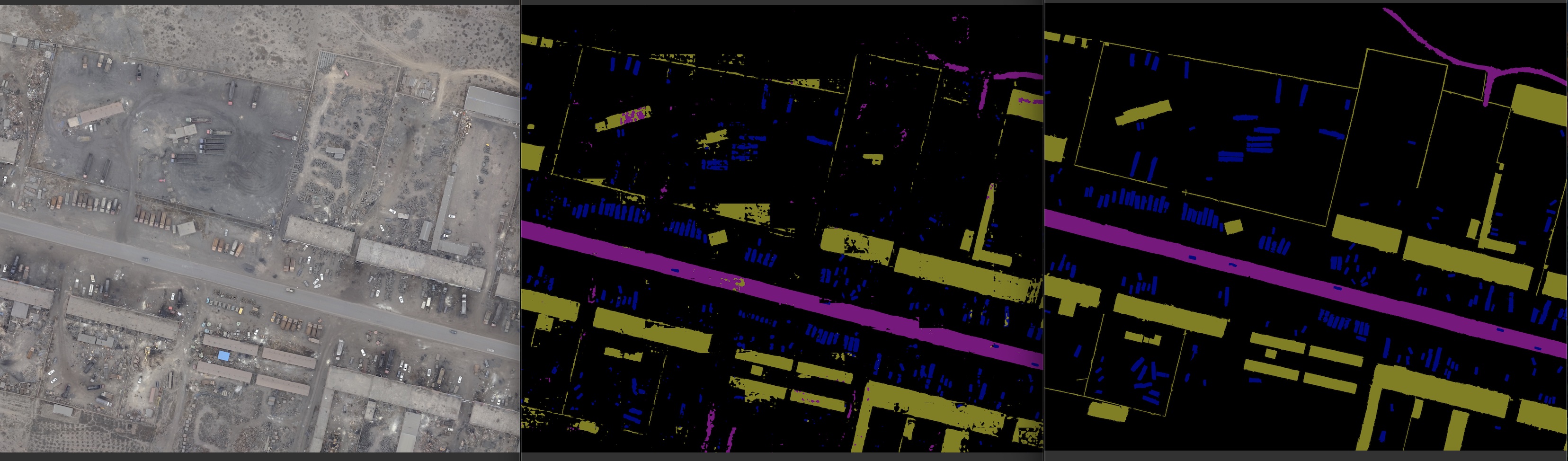
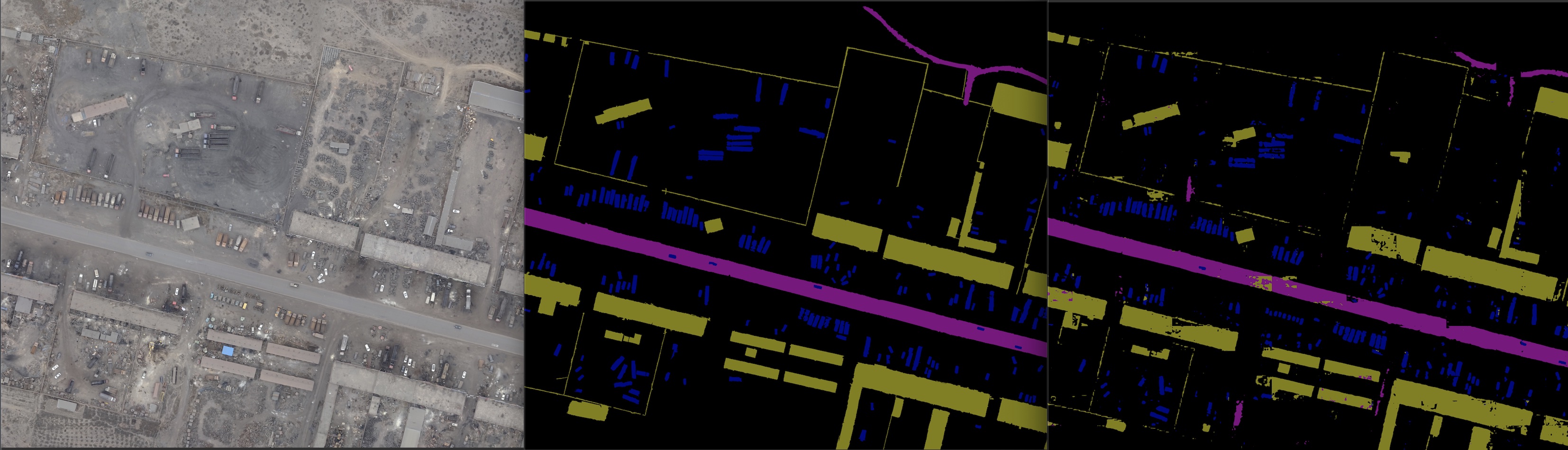
7. 实验优化问题记录
7.1 实验优化问题解决记录-MIoU-v0217
- MIoU数据:MIoUData.py:读取label和predict图像,以tensor形式,batch_size=4传入----v0210
- MIoU的计算:testMIoU.py:将传入的tensor转为np的array,再执行flatten()进行一维化,每4个图像进行计算miou,最后求平均的miou
- 问题:计算得到的MIoU都为1.0,怀疑原因,中间的float强转int,最后得到的数值都为1
- 解决v0217:修改读入方式,使用CV2直接读入,不变为tensor,详见MIoUCalv0217.py,MIoUDatav0217.py
7.2 实验待优化问题-预处理
- MyData_v0211版本,cv2以BGR模式读入训练集,先改为RGB图像,再进行nomalize初始化,使用的mean和std数值都为Imagenet数据集预训练得到的,但是训练完成之后,预测结果有偏差,如下:


7.3 预测问题-已解决v0217
- v0217版本:修改预测方法,以一张一张读入进行预测,解决之前的大部分涂色失败问题。效果如下:


7.4 SGD与Adam优化器预测效果对比
- v0219:仅仅改动优化器为Adam,lr=1e-3


