A simple docker container that runs PostGIS
Visit our page on the docker hub at: https://hub.docker.com/r/kartoza/postgis/
There are a number of other docker postgis containers out there. This one differentiates itself by:
- provides ssl support out of the box
- connections are restricted to the docker subnet
- template_postgis database template is created for you
- a default database 'gis' is created for you so you can use this container 'out of the box' when it runs with e.g. QGIS
- replication support included
We will work to add more security features to this container in the future with the aim of making a PostGIS image that is ready to be used in a production environment (though probably not for heavy load databases).
There is a nice 'from scratch' tutorial on using this docker image on Alex Urquhart's blog here - if you are just getting started with docker, PostGIS and QGIS, we really recommend that you use it.
The following convention is used for tagging the images we build:
kartoza/postgis:[postgres_version]-[postgis-version]
So for example:
kartoza/postgis:9.6-2.4 Provides PostgreSQL 9.6, PostGIS 2.4
Note: We highly recommend that you use tagged versions because successive minor versions of PostgreSQL write their database clusters into different database directories - which will cause your database to appear to be empty if you are using persistent volumes for your database storage.
There are various ways to get the image onto your system:
The preferred way (but using most bandwidth for the initial image) is to get our docker trusted build like this:
docker pull kartoza/postgis
To build the image yourself without apt-cacher (also consumes more bandwidth since deb packages need to be refetched each time you build) do:
docker build -t kartoza/postgis git://github.com/kartoza/docker-postgis
To build with apt-cacher (and minimise download requirements) you need to clone this repo locally first and modify the contents of 71-apt-cacher-ng to match your cacher host. Then build using a local url instead of directly from github.
git clone git://github.com/kartoza/docker-postgis
Now edit 71-apt-cacher-ng then do:
docker build -t kartoza/postgis .
To create a running container do:
sudo docker run --name "postgis" -p 25432:5432 -d -t kartoza/postgis
You can also use the following environment variables to pass a user name, password and/or default database name.
- -e POSTGRES_USER=
- -e POSTGRES_PASS=
- -e POSTGRES_DBNAME=
These will be used to create a new superuser with your preferred credentials. If these are not specified then the postgresql user is set to 'docker' with password 'docker'.
You can open up the PG port by using the following environment variable. By default the container will allow connections only from the docker private subnet.
- -e ALLOW_IP_RANGE=<0.0.0.0/0> By default t
Postgres conf is setup to listen to all connections and if a user needs to restrict which IP address PostgreSQL listens to you can define it with the following environment variable. The default is set to listen to all connections.
- -e IP_LIST=<*>
For convenience we have provided a docker-compose.yml that will run a
copy of the database image and also our related database backup image (see
https://github.com/kartoza/docker-pg-backup).
The docker compose recipe will expose PostgreSQL on port 25432 (to prevent potential conflicts with any local database instance you may have).
Example usage:
docker-compose up -d
Note: The docker-compose recipe above will not persist your data on your local disk, only in a docker volume.
Connect with psql (make sure you first install postgresql client tools on your host / client):
psql -h localhost -U docker -p 25432 -l
Note: Default postgresql user is 'docker' with password 'docker'.
You can then go on to use any normal postgresql commands against the container.
Under ubuntu 16.04 the postgresql client can be installed like this:
sudo apt-get install postgresql-client-9.6
Docker volumes can be used to persist your data.
mkdir -p ~/postgres_data
docker run -d -v $HOME/postgres_data:/var/lib/postgresql kartoza/postgis`
You need to ensure the postgres_data directory has sufficient permissions
for the docker process to read / write it.
Replication allows you to maintain two or more synchronised copies of a database, with a single master copy and one or more replicant copies. The animation below illustrates this - the layer with the red boundary is accessed from the master database and the layer with the green fill is accessed from the replicant database. When edits to the master layer are saved, they are automatically propagated to the replicant. Note also that the replicant is read-only.
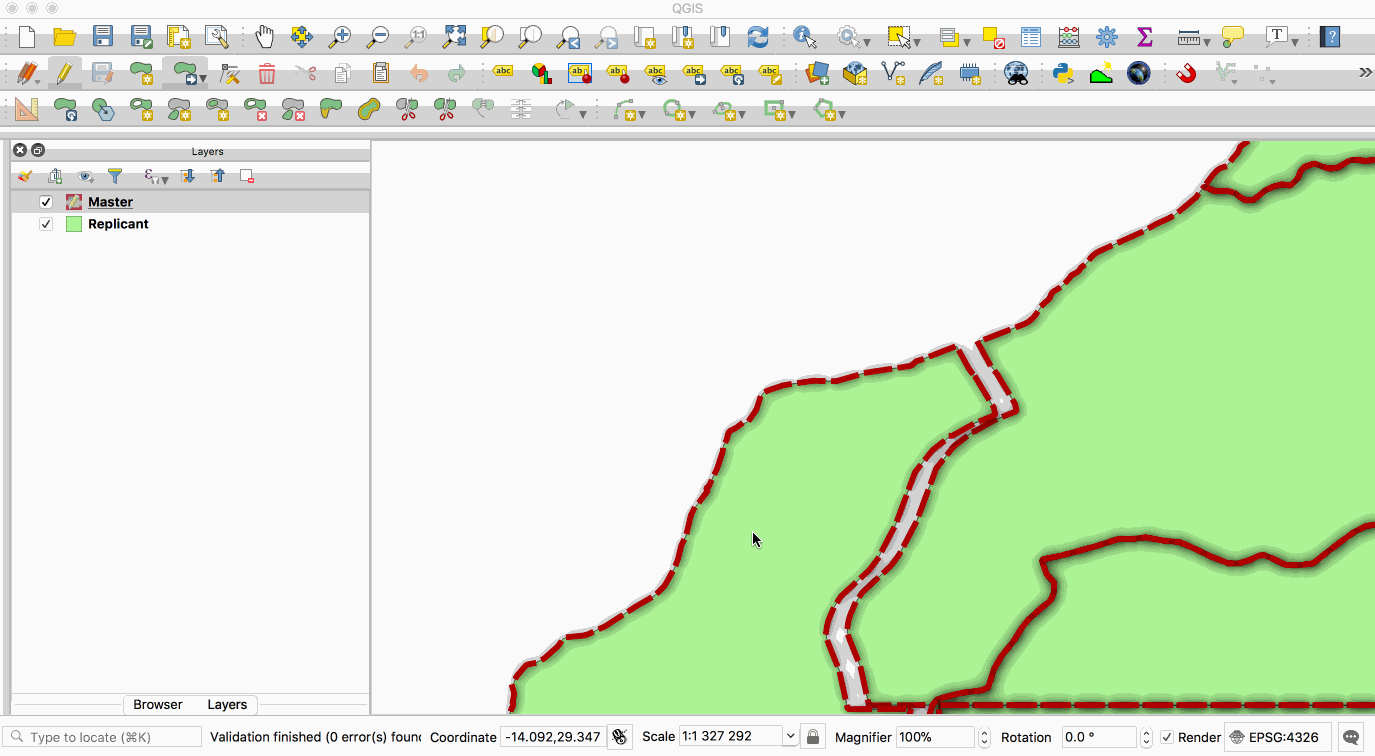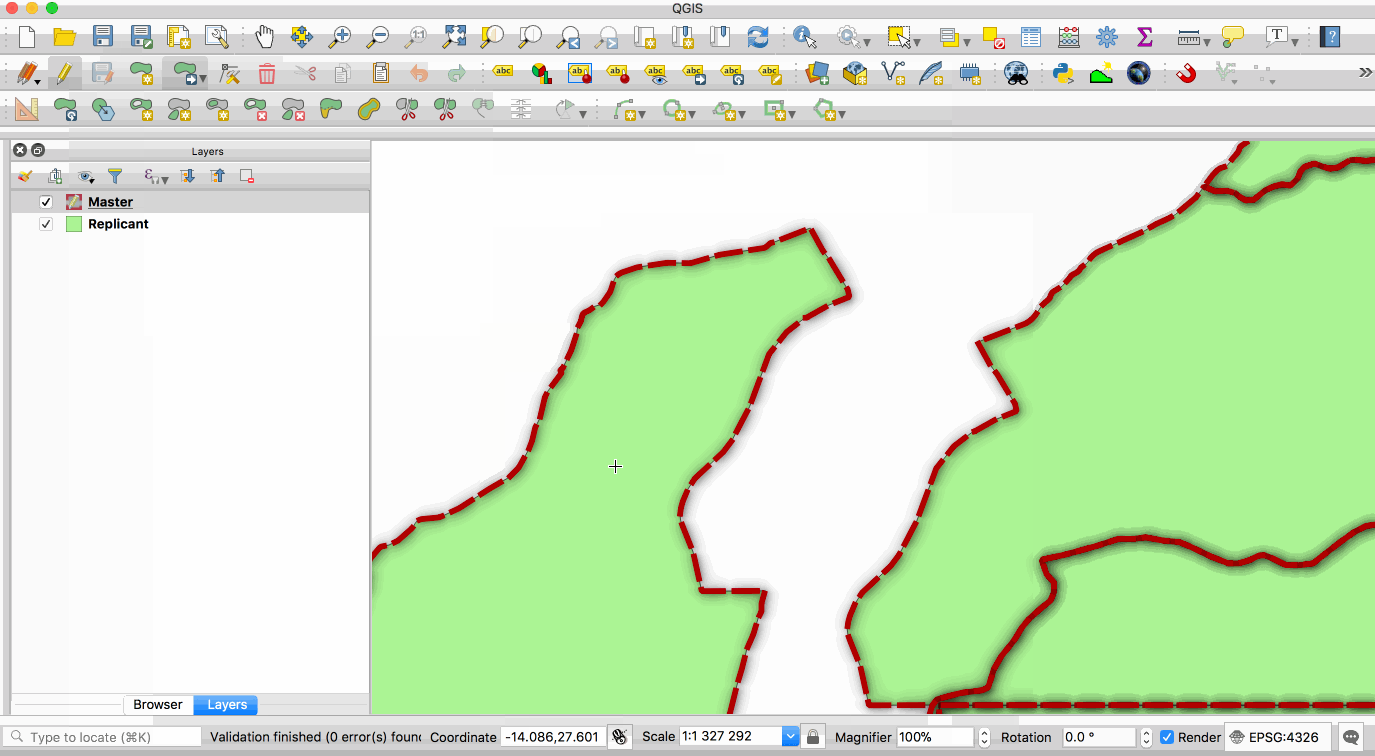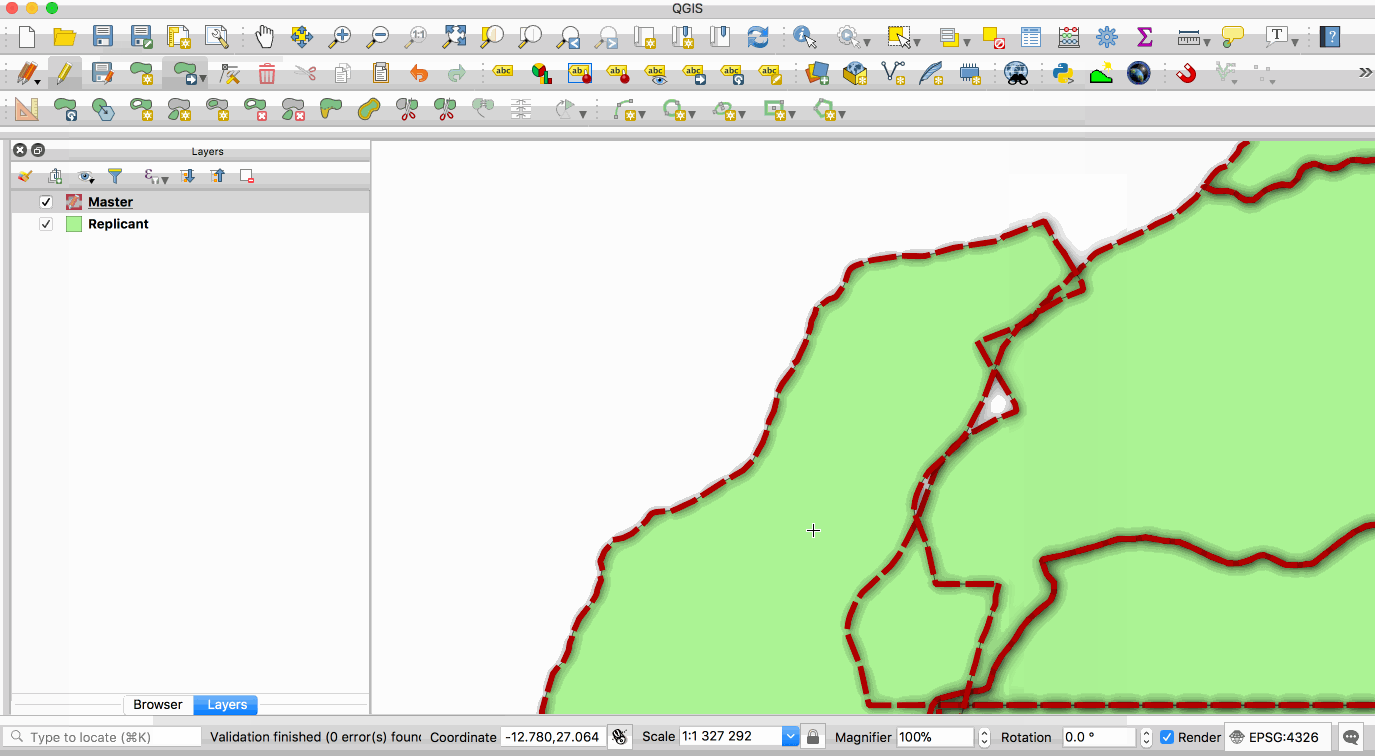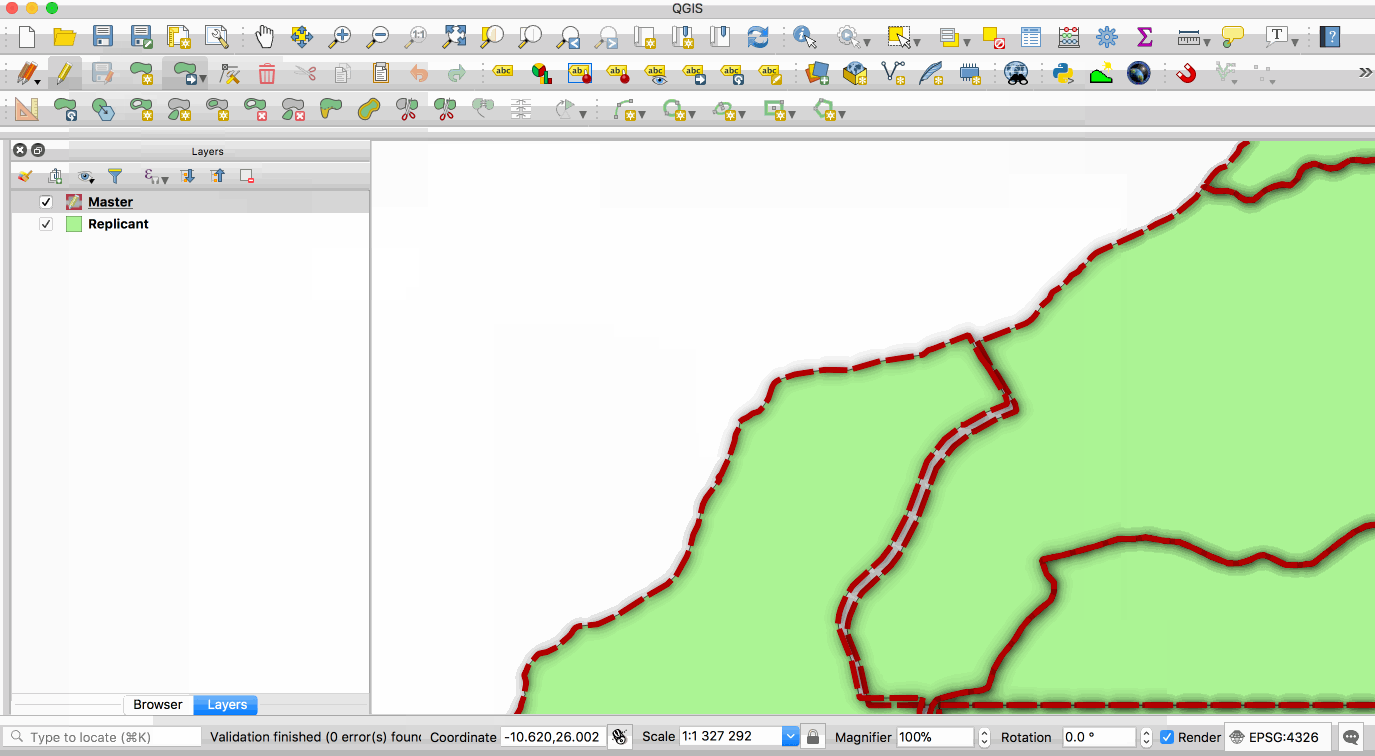
This image is provided with replication abilities. We can
categorize an instance of the container as master or replicant. A master
instance means that a particular container has a role as a single point of
database write. A replicant instance means that a particular container will
mirror database content from a designated master. This replication scheme allows
us to sync databases. However a replicant is only for read-only transaction, thus
we can't write new data to it. The whole database cluster will be replicated.
To experiment with the replication abilities, you can see a (docker-compose.yml)[sample/replication/docker-compose.yml] sample. There are several environment variables that you can set, such as:
Master settings:
- ALLOW_IP_RANGE: A pg_hba.conf domain format which will allow specified host(s)
to connect into the container. This is needed to allow the
slaveto connect intomaster, so specifically this settings should allowslaveaddress. It is also needed to allow clients on other hosts to connect to either the slave or the master. - Both POSTGRES_USER and POSTGRES_PASS will be used as credentials for the slave to connect, so make sure you change this into something secure.
Slave settings:
- REPLICATE_FROM: This should be the domain name or IP address of the
masterinstance. It can be anything from the docker resolved name like that written in the sample, or the IP address of the actual machine where you exposemaster. This is useful to create cross machine replication, or cross stack/server. - REPLICATE_PORT: This should be the port number of
masterpostgres instance. Will default to 5432 (default postgres port), if not specified. - DESTROY_DATABASE_ON_RESTART: Default is
True. Set to 'False' to prevent this behaviour. A replicant will always destroy its current database on restart, because it will try to sync again frommasterand avoid inconsistencies. - PROMOTE_MASTER: Default none. If set to any value then the current replicant
will be promoted to master.
In some cases when the
mastercontainer has failed, we might want to use ourreplicantasmasterfor a while. However, the promoted replicant will break consistencies and is not able to revert to replicant anymore, unless it is destroyed and resynced with the new master.
To run the sample replication, follow these instructions:
Do a manual image build by executing the build.sh script
./build.sh
Go into the sample/replication directory and experiment with the following Make
command to run both master and slave services.
make up
To shutdown services, execute:
make down
To view logs for master and slave respectively, use the following command:
make master-log
make slave-log
You can try experiment with several scenarios to see how replication works
You can use any postgres database tools to create new tables in master, by connecting using POSTGRES_USER and POSTGRES_PASS credentials using exposed port. In the sample, the master database was exposed on port 7777. Or you can do it via command line, by entering the shell:
make master-shell
Then made any database changes using psql.
After that, you can see that the replicant follows the changes by inspecting the slave database. You can, again, use database management tools using connection credentials, hostname, and ports for replicant. Or you can do it via command line, by entering the shell:
make slave-shell
Then view your changes using psql.
You will notice that you cannot make changes in replicant, because it is read-only.
If somehow you want to promote it to master, you can specify PROMOTE_MASTER: 'True'
into slave environment and set DESTROY_DATABASE_ON_RESTART: 'False'.
After this, you can make changes to your replicant, but master and replicant will not be in sync anymore. This is useful if the replicant needs to take over a failover master. However it is recommended to take additional action, such as creating a backup from the slave so a dedicated master can be created again.
You can optionally set DESTROY_DATABASE_ON_RESTART: 'False' after successful sync
to prevent the database from being destroyed on restart. With this setting you can
shut down your replicant and restart it later and it will continue to sync using the existing
database (as long as there are no consistencies conflicts).
However, you should note that this option doesn't mean anything if you didn't persist your database volume. Because if it is not persisted, then it will be lost on restart because docker will recreate the container.
Tim Sutton (tim@kartoza.com) Gavin Fleming (gavin@kartoza.com) Risky Maulana (rizky@kartoza.com) Admire Nyakudya (admire@kartoza.com) December 2018