- pandas
- numpy
- flask
- sqlalchemy
- plotly
- NLTK
- sklearn
- joblib
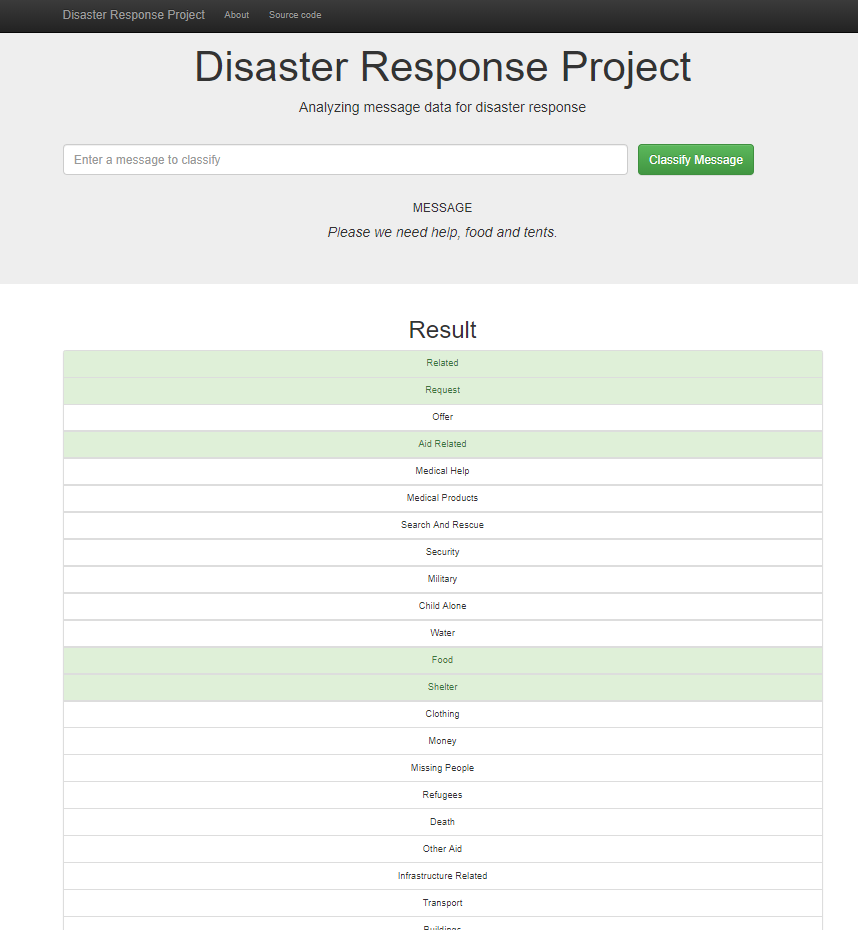
The main goal of this project is to build a web app that can help emergency workers analyze incoming messages and classify them into specific categories like Medical Help/Water/Search And Rescue.
-** ETL pipeline (data directory):** *Merges messages and categories datasets *Cleans the data and save it into a SQLite database
-** Natural Language Processing and Machine Learning Pipeline (models directory):** *Split the dataset into training and test sets *Build a ML pipeline *Train the dataset using GridSearchCV *Save the model as a *.pickle file
-** Flask Web app (app directory):
-
Clone the repository: git clone https://github.com/m0hamdan/Disaster-Response-Pipelines.git
-
Run the following commands in the project's root directory to set up your database and model.
- To run ETL pipeline that cleans data and stores in database 'python data/process_data.py data/disaster_messages.csv data/disaster_categories.csv data/DisasterResponse.db'
- To run ML pipeline that trains classifier and saves 'python models/train_classifier.py data/DisasterResponse.db models/classifier.pkl'
-
Run the following command in the app's directory to run your web app. 'python run.py'
-
Go to http://0.0.0.0:3001/
![License: GNU GENERAL PUBLIC LICENSE]
- Figure Eight for providing the messages and categories datasets used to train the model