This repo provides a set of different benchmarks for memplusplus memory allocator. Each test benchmarks a wide range of functionality starting from simple allocation/deallocation speed and ending with some complex things (such as speed of data access after heap compacting/relayouting).
- Clone this repo:
git clone https://github.com/m4drat/memplusplus-benchmarks --recurse-submodules - Run all benchmarks
cd memplusplus-benchmarks && ./compile_all_and_run.sh.sh
-
benchmark_alloc.cpp- Sequence of allocations from the same size bucketTime spent to allocate 4096 objects of random size in us:

-
benchmark_alloc_dealloc.cpp- Allocations and immediate deallocations -
benchmark_dealloc.cpp- Sequence of chunks deallocations from the same size bucketTime spent to deallocate 4096 objects of random size in us:
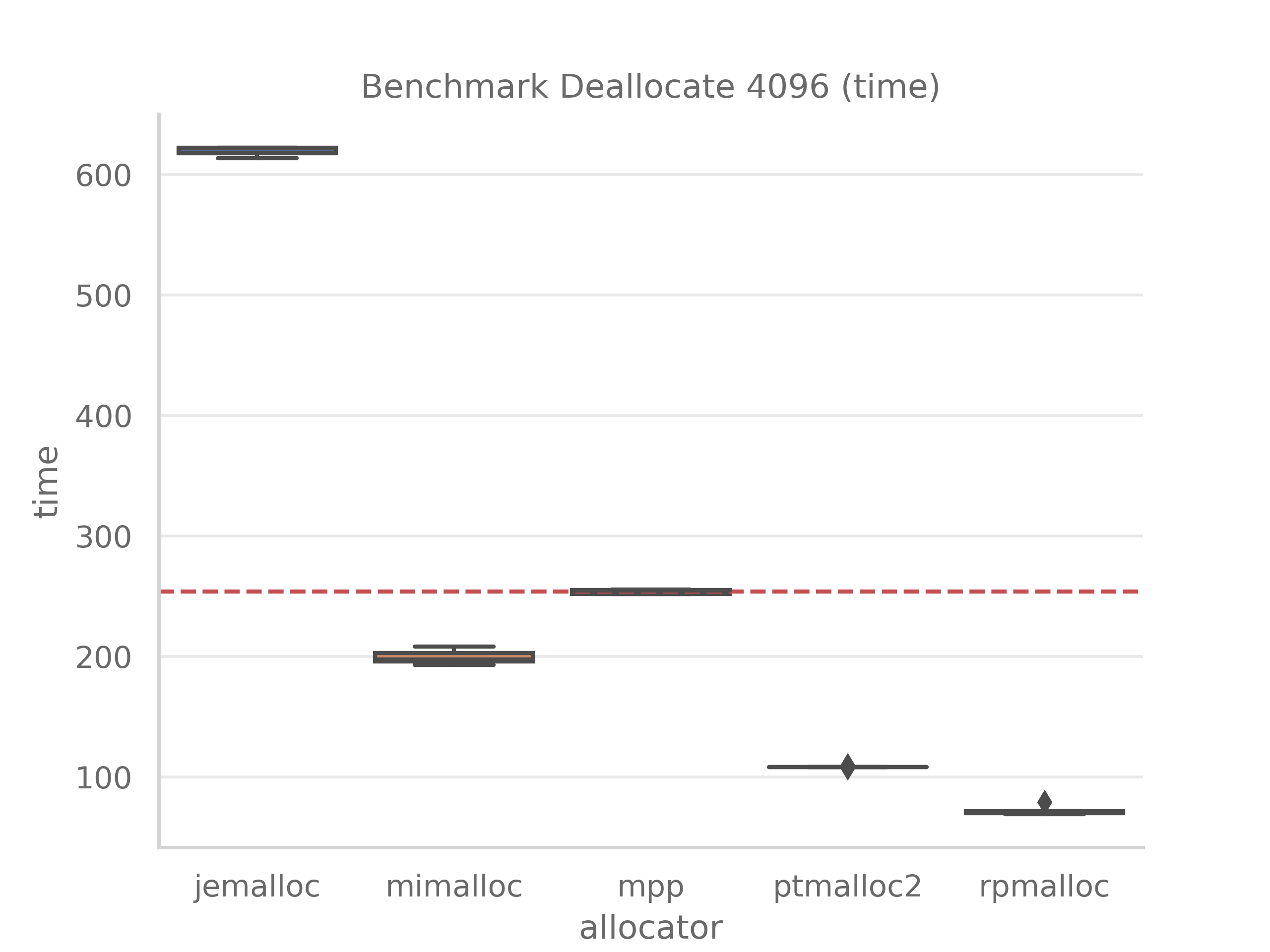
-
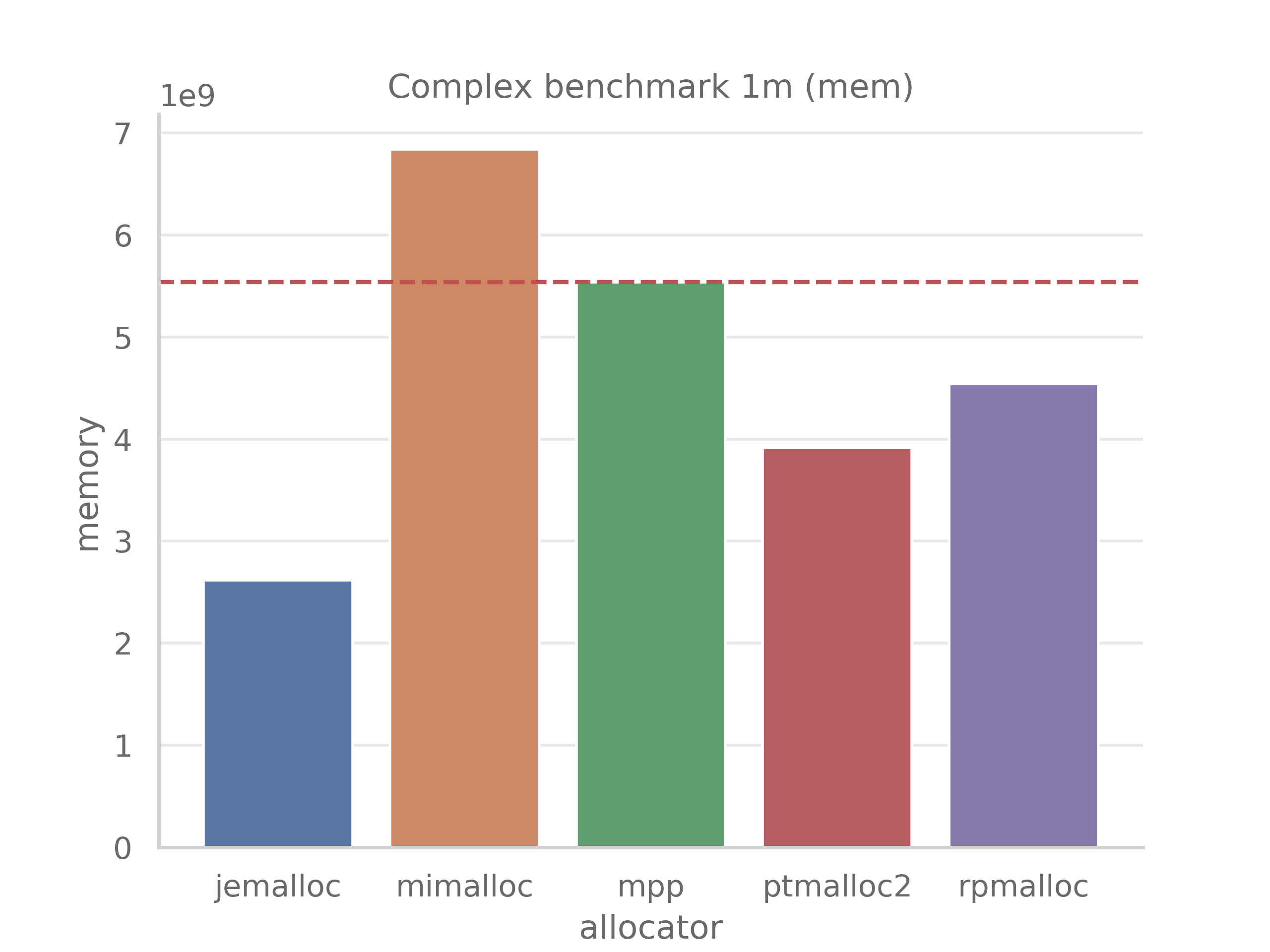
benchmark_complex.cpp- Emulates a complex workload with allocations, deallocations and data access. This test is the most complex one and it is the most representative of real-world workloads. Benchmark inspired by rpmalloc-benchmarkTime spent to perform 1m operations (approx. 0.5m allocations, 0.5m deallocations) in ms:

Peak memory usage
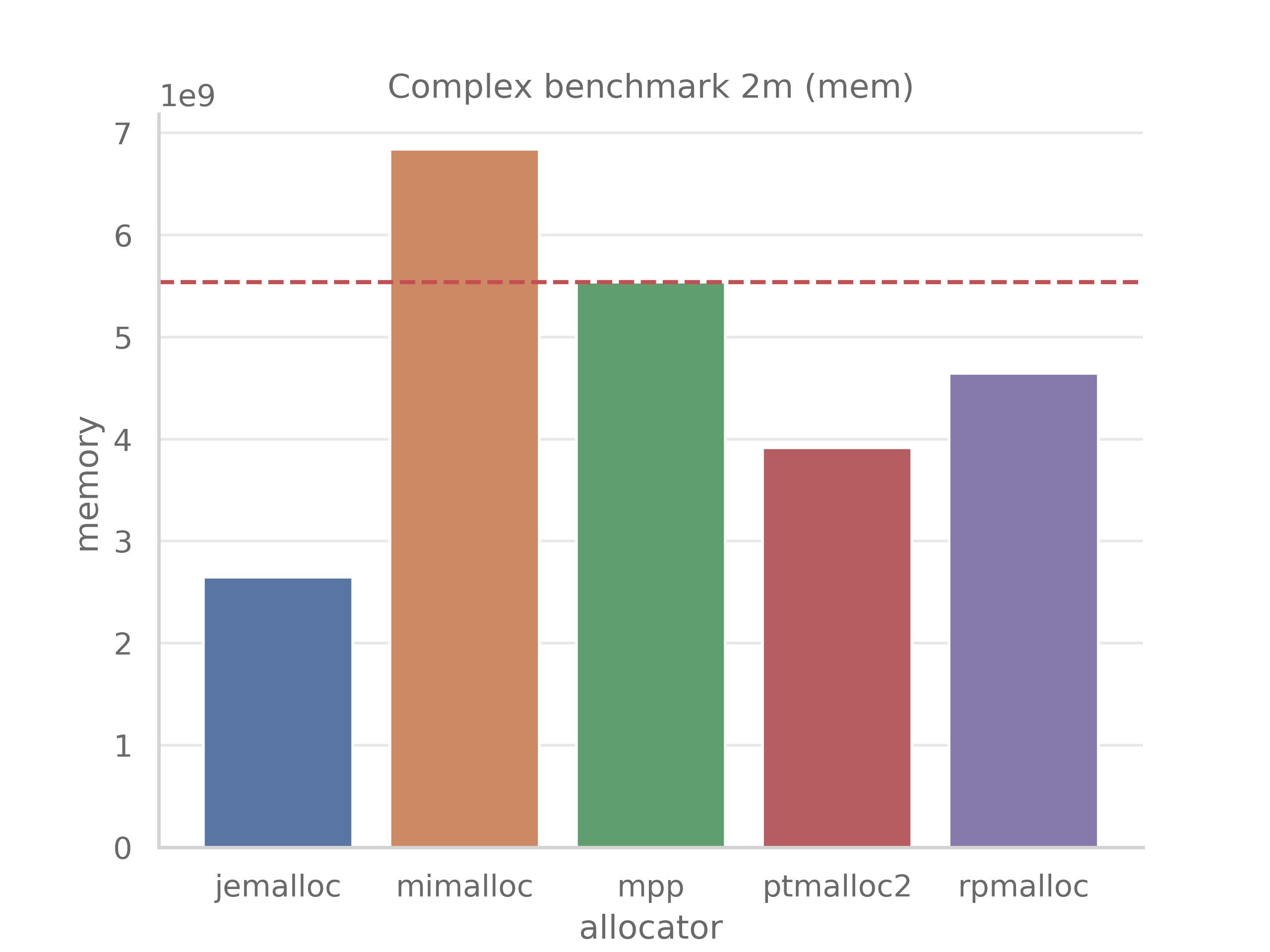
Time spent to perform 2m operations (approx. 1m allocations, 1m deallocations) in ms:

Peak memory usage
-
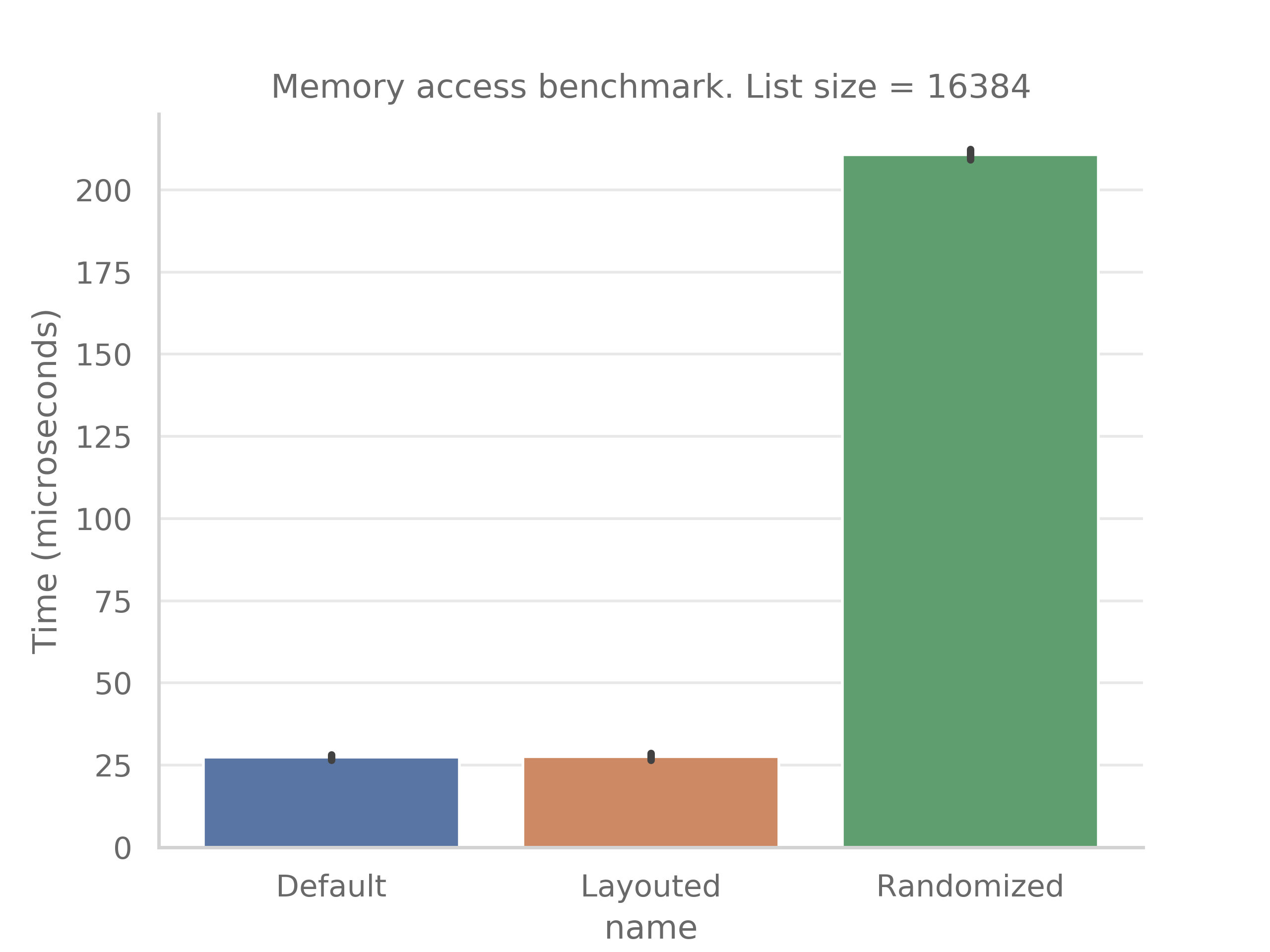
benchmark_memory_access.cpp- Data access speed before/after compacting (only formemplusplus)First column - optimally layouted and accessed linked list
second column - randomized linked list, but after layouting
third column - randomized linked listTime spent to iterate over linked list of size 8192 in us:
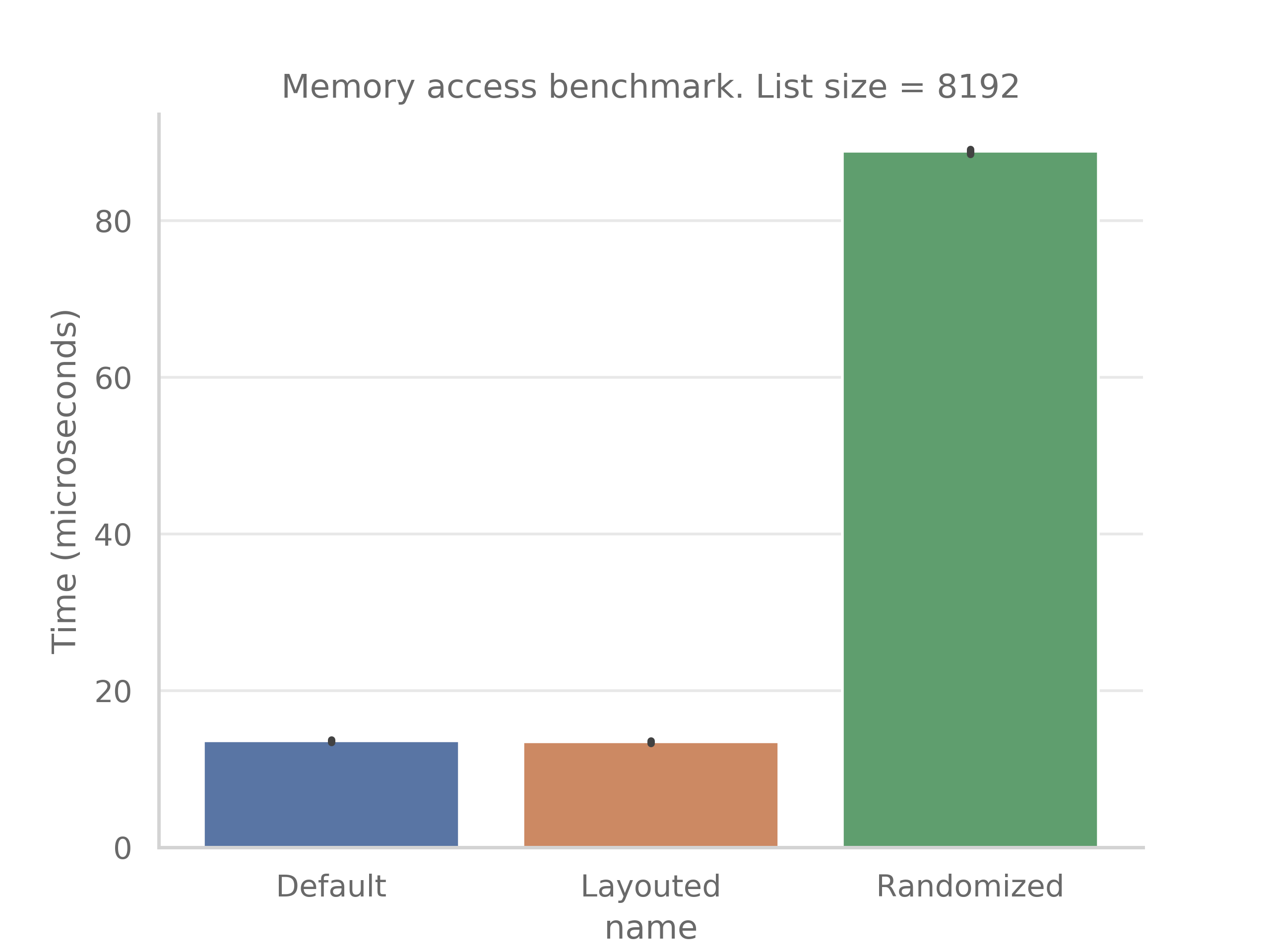
Time spent to iterate over linked list of size 16384 in us:








- gcpp
- jemalloc
- mempp
- mimalloc
- [?] ptmalloc2 - latest (glibc 2.36), currently uses
libc 2.31 (from my machine) - ptmalloc3
- rpmalloc