By: Mácio Matheus Santos de Arruda
Multilabel classification using convolutional networks. This project uses the dataset Caltech 101, a famous database for computer vision applications.
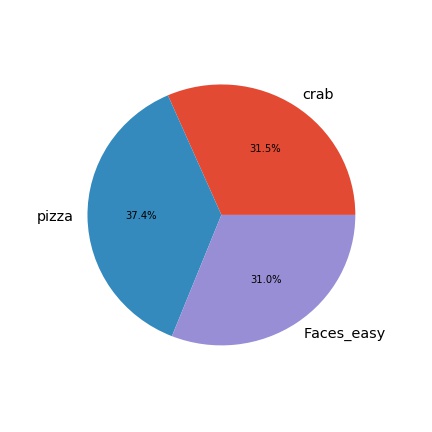
Three different classes were selected of the dataset caltech101: Crab; Faces_Easy and Pizza. Below is a graph indicating the percentage of each:
An increase of database was done, to work better with convolutional network.
Five images were generated for each image in the dataset. Below is an example of an increase made for an instance of each class.

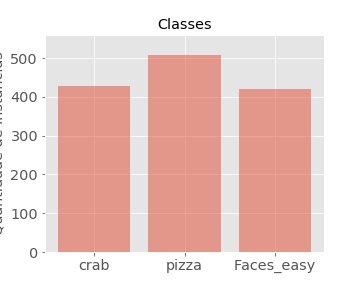
Instance quantity per class after data augmentation
Using Keras, the neural network below was assembled to solve the presented classification problem:

Parameterization used in the model
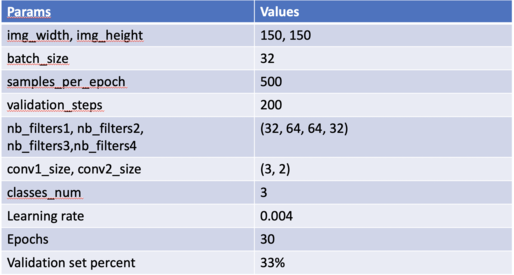
As in the image, for the validation set that compose the metrics measured in the training, a percentage of 33% of the data in the training images folder is defined in the Keras generator by the parameter validation_split.
Note: The Live Test is performed with a set of images that do not participate in the training.

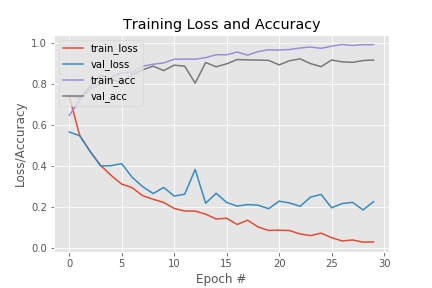
Below is the graph of loss and accuracy in training and validation sets during training
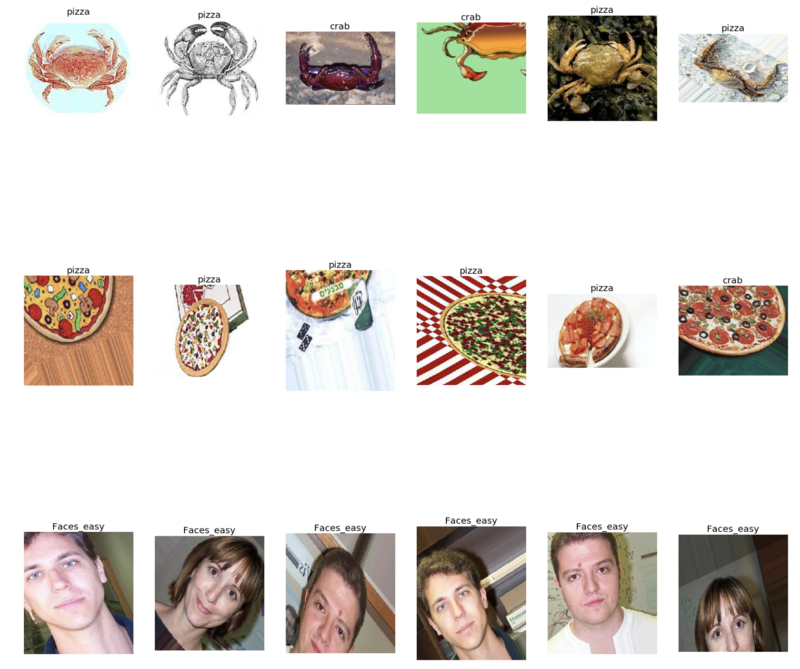
Prediction performed on images that were outside the training set and validation. The crabs were intentionally pointed in circle format to cause error in the model:
First of all, build the container using docker-compose and then you can access the Jupyter that is ready to be used.
cd computer-vision-caltech101
docker-compose up -dhttp://<your-ip>:8111/tree - 8888 => Jupyter
- 6011 => Tensorboard
- 5011 => Apphttps://hub.docker.com/r/maciomatheus/jupyter_notebook_data_science/