The main objective was to apply machine learning on a bigdata infrastructure. The main focus was not on reaching a model that could be used in production, so attention was not given to KDD's primary steps. Therefore, the examples shown do not best contemplate steps such as data visualization, data preprocessing and statistical evaluation of the generated models.
Team:
- Julio Sales (@jsalesba)
- Mácio Arruda (@macio-matheus)
- Victor Outtes (@vmoa)
This repository contains examples of implementations of machine learning models, using BigData tools.
Architecture used in project
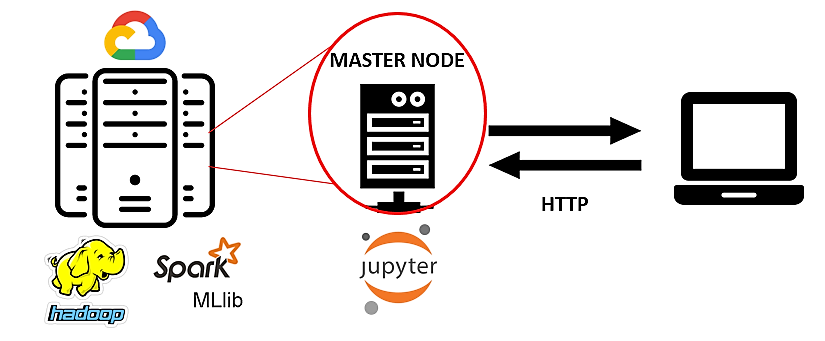
Machine learning models used for bigdata illustrations:
- Clustering (KMeans)
- Classification (RandomForest)
- Regression (LinearRegression)