Joint Dictionary Learning-based Non-Negative Matrix Factorization for Voice Conversion to Improve Speech Intelligibility After Oral Surgery (TBME 2016)
IEEE Transactions on Biomedical Engineering, 2016
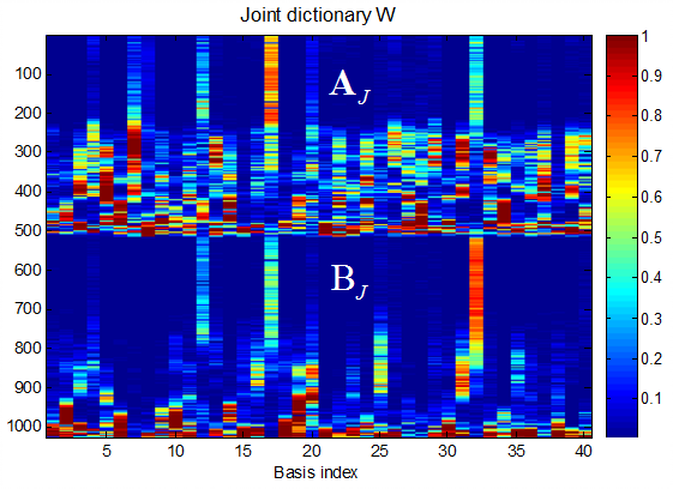
The Joint Dictionary Learning-based Non-Negative Matrix Factorization (JD-NMF) is used for training joint dictionary (source & target) for voice conversion. But this method can also be used in other applications where the two dictionaries have to be aligned. The basic idea is that if two signals are first aligned by some methods (e.g., DTW in speech processing), to reconstruct the coupled training data with shared activation matrix, the learned dictionaries are automatcally forced to couple with each other to minimize the distance (e.g., KL divergence).
For more details and evaluation results, please check out our paper.
Gitsource.list is the list of source speech files used for training JD-NMF.
Gittarget.list is the list of target speech files used for training JD-NMF.
Gitsource_Test.list is the list of source speech files used for testing (conversion).
JDNMF.m: Convert the source speech files listed in Gitsource_Test.list (with spectrogram features) to the Converted_speech folder.
JDNMF_STRAIGHT.m: Convert the source speech files listed in Gitsource_Test.list (with STRAIGHT features) to the Converted_speech_STRAIGHT folder. This may perform better, but you have to ask the STRAIGHT code from here.
If you find the code and datasets useful in your research, please cite:
@article{fu2016joint,
title={Joint Dictionary Learning-based Non-Negative Matrix Factorization for Voice Conversion to Improve Speech Intelligibility After Oral Surgery},
author={Fu, Szu-Wei and Li, Pei-Chun and Lai, Ying-Hui and Yang, Cheng-Chien and Hsieh, Li-Chun and Tsao, Yu},
journal={IEEE Transactions on Biomedical Engineering},
year={2016},
publisher={IEEE}
}
e-mail: jasonfu@iis.sinica.edu.tw or d04922007@ntu.edu.tw