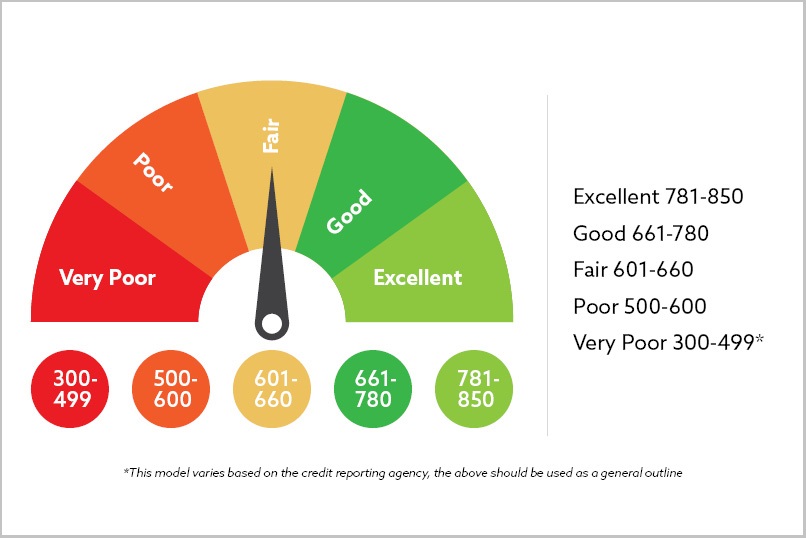
Figure 1: Credit Score Illustration (Source).
In this project, we developed a credit score model leveraging Logistic Regression and Weight of Evidence techniques. The scoring methodology is based on the "point to double the odds" approach, utilizing Logistic Regression parameters, Weight of Evidence, and specific user-defined constraints to assign credit points for based on each predictor variable. Tools that will be used is optbinning which is a library for credit scorecard development.
The main objective is to create a reliable credit score model and develop a comprehensive credit scorecard.
The project is built using Python 3.12.4, with the following libraries and tools:
pandasandnumpyfor data manipulation.matplotlibandseabornfor data visualization.optbinningfor credit scorecard development (weight of evidence and information Value calculation).scikit-learn, andoptbinningfor training and evaluation credit score model.
To run this project locally, you can use Anaconda. Ensure your Python version is 3.12.4. Recommended using linux environment for setting up environment. Then, install the required libraries from the requirements.txt file:
make create_environment # create conda environment
conda activate credit-scorecard-modelling-with-optbinning # access the environment
make requirements # install all libraries from the requirements.txt file
make create_ipykernel # create ipykernelWith this you can use run the code using the exact same dependencies that I used for this project.
For a detailed explanation of the project, please visit my Medium blog post.