- O conteúdo foi retirado dos módulos e paths do site Microsoft Learn, simulados realizados e outras fontes para fins de estudo.
- Criei o Path de estudo para a certificação DP-900 e vou atualizando conforme necessidade.
- Esse resumo não substitui os módulos completos. Recomendo fortemente estudar através dos módulos do MS Learn.
- Resumo baseado no Study Guide oficial da Microsoft.
- Microsoft Azure training and certifications.
- Façam simulados.
- Agendamento do exame de certificação.
- Fiquem a vontade para ajudar a melhorar o conteúdo.
Icons: ☁️🔸
- Describe core data concepts (25-30%)
- Identify considerations for relational data on Azure (20-25%)
- Describe considerations for working with non-relational data on Azure (15-20%)
- Describe an analytics workload on Azure (25-30%)
Os dados são uma coleção de fatos, como números, descrições e observações usados para registrar informações.
As estruturas de dados representam entidades de uma organização (clientes, produtos, pedidos de vendas, etc).
Cada entidade tem um ou mais atributos ou características (nome, endereço, número de telefone, etc).
Podemos classificar os dados como estruturados, semiestruturados ou não estruturados.
- Dados estruturados obedecem a um esquema fixo, possuem os mesmos campos ou propriedades
- O esquema para entidades de dados estruturados é tabular.
- linhas representam cada instância de uma entidade.
- colunas representam os atributos da entidade.
- Os dados estruturados são armazenados em um banco de dados.
- Várias tabelas podem referenciar umas às outras usando valores de chave em um modelo relacional.
- Dados semiestruturados são informações que têm alguma estrutura.
- Permitem alguma variação entre instâncias da entidade.
- As entidades podem ter um ou mais endereços de email e outras podem não ter nenhum.
- Formatos comuns para dados semiestruturados: JSON e XML.
- Pode conter grandes variações na estrutura dos dados.
O JSON (JavaScript Object Notation) é apenas uma das muitas maneiras pelas quais os dados semiestruturados podem ser representados.
Dados semiestruturados onde cada entidade fornece suas próprias definições de campo são uma descrição de dados de tipo documento e, portanto, um armazenamento de documentos é sua melhor escolha. Os documentos são escritos e recuperados como documentos completos. As definições de campo incorporadas possibilitam consultar documentos para recuperar valores de campo. Normalmente, você usaria uma solução de armazenamento do Azure Cosmos DB.
Nem todos os dados são estruturados ou até mesmo semiestruturados.
Documentos, imagens, dados de áudio e vídeo e arquivos binários podem não ter uma estrutura específica.
Para grandes arquivos de áudio e vídeo que são usados como fonte para conteúdo de streaming, você deve escolher um armazenamento de dados de objeto. Arquivos desse tipo são dados não estruturados e não relacionais. A solução de armazenamento típica para esse tipo de arquivo é um armazenamento de objetos, como o armazenamento de BLOBs do Azure.
Normalmente os dados são armazenados em formato estruturado, semiestruturado ou não estruturado para registrar e podem ser recuperados para análise e relatórios posteriormente:
- Detalhes de entidades (clientes e produtos)
- Eventos específicos (como transações de vendas) ou outras informações em documentos
- Imagens e outros formatos.
Há duas categorias amplas de armazenamento de dados comuns em uso:
- Armazenamentos de arquivos
- São armazenados de maneira centralizada em algum tipo de sistema de compartilhamento de arquivos.
- Bancos de dados
O formato de arquivo específico depende de alguns fatores:
- O tipo de dado que está sendo armazenado (estruturado, semiestruturado ou não estruturado).
- Os aplicativos e serviços que precisarão ler, gravar e processar os dados.
- Legíveis por seres humanos ou otimizados para armazenamento e processamento eficientes.
Os dados são armazenados em formato de texto sem formatação com delimitadores de campo e terminadores de linha específicos.
- CSV (comma-separated values) - O formato mais comum é CSV. Opcionalmente, a primeira linha pode incluir os nomes de campo.
- TSV (tab-separated values) e space-delimited - em que as tabulações ou os espaços são usados para separar campos
- Fixed-width data - Dados de largura fixa em que a cada campo é alocado um número fixo de caracteres. Para dados estruturados que precisam ser acessados por vários aplicativos e serviços em um formato legível.
O JSON possui um esquema de documento hierárquico usado para definir entidades de dados (objetos) e seus atributos. Cada atributo pode ser um objeto (ou uma coleção de objetos), tornando o JSON um formato flexível que é bom para dados estruturados e semiestruturados.
- Os objetos estão entre chaves {..}
- As coleções estão entre colchetes [..].
- Os atributos são representados por pares nome:valor e separados por vírgulas.
{
"customers":
[
{
"firstName": "Joe",
"lastName": "Jones",
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}
]
}O XML é um formato de dados legível que foi popular nos anos 90 e 2000, mas ainda há alguns sistemas que usam XML para representar dados. O XML usa marcas delimitadas por colchetes angulares <../> para definir elementos e atributos.
<Customers>
<Customer name="Joe" lastName="Jones">
<ContactDetails>
<Contact type="home" number="555 123-1234"/>
<Contact type="email" address="joe@litware.com"/>
</ContactDetails>
</Customer>
<Customer name="Samir" lastName="Nadoy">
<ContactDetails>
<Contact type="email" address="samir@northwind.com"/>
</ContactDetails>
</Customer>
</Customers>Todos os arquivos são armazenados como dados binários, mas nos formatos legíveis descritos acima, os bytes de dados binários são mapeados em caracteres imprimíveis (ASCII). Alguns formatos de arquivo de dados não estruturados, armazenam os dados como binários brutos que devem ser interpretados por aplicativos e renderizados.
Para grandes arquivos de áudio e vídeo que são usados como fonte para conteúdo de streaming, você deve escolher um armazenamento de dados de objeto. Arquivos desse tipo são dados não estruturados e não relacionais. A solução de armazenamento para esse tipo de arquivo é um armazenamento de objetos, como o armazenamento de BLOBs do Azure.
Tipos comuns de dados armazenados como binários:
- Imagens
- Vídeo
- Documentos específicos de apps
Os formatos legíveis para dados estruturados e semiestruturados são úteis, mas não são otimizados para espaço de armazenamento ou processamento. Ao longo do tempo, alguns formatos de arquivo que permitem a compactação, a indexação e o armazenamento e o processamento eficientes foram desenvolvidos.
-
Avro - é um formato baseado em linha criado pelo Apache.
- Cada registro contém um cabeçalho que descreve a estrutura dos dados.
- Esse cabeçalho é armazenado como JSON.
- Os dados são armazenados como informações binárias.
- Um aplicativo usa o cabeçalho para analisar os dados binários e extrair os campos contidos neles.
- O Avro é um formato bom para compactar dados e minimizar armazenamento e largura de banda de rede.
-
ORC (Optimized Row Columnar format) - organiza os dados em colunas e foi desenvolvido pela HortonWorks para otimizar as operações de leitura e gravação no Apache Hive (sistema de data warehouse que dá suporte a resumos rápidos de dados e consultas em grandes conjuntos de dados).
- Um arquivo ORC contém faixas de dados.
- Cada faixa contém os dados de uma coluna ou conjunto de colunas.
- Uma faixa contém um índice nas linhas na faixa, os dados de cada linha e um rodapé que contém informações estatísticas (contagem, soma, máximo, mínimo e assim por diante) para cada coluna.
-
Parquet - organiza os dados em colunas e foi criado pela Cloudera e Twitter.
- Um arquivo Parquet contém grupos de linhas.
- Os dados de cada coluna são armazenados juntos no mesmo grupo de linhas.
- Cada grupo de linhas contém uma ou mais partes de dados.
- Um arquivo Parquet inclui metadados que descrevem o conjunto de linhas encontrado em cada parte.
- Um aplicativo pode usar esses metadados para localizar rapidamente a parte correta de um determinado conjunto de linhas e recuperar os dados nas colunas especificadas para essas linhas.
- O Parquet é especialista em armazenar e processar tipos de dados aninhados com eficiência.
- Suporte a esquemas de codificação e compactação muito eficientes.
Um banco de dados é usado para definir um sistema central no qual dados podem ser armazenados e consultados.
-
Bancos de dados relacionais são comumente usados para armazenar e consultar dados estruturados.
- Os dados são armazenados em tabelas que representam entidades (clientes, produtos ou pedidos de venda).
- Cada instância de uma entidade recebe uma chave primária que a identifica de maneira exclusiva.
- Essas chaves são usadas para fazer referência à instância da entidade em outras tabelas.
- Esse uso de chaves permite que um banco de dados relacional seja normalizado (eliminação de valores de dados duplicados.)
- As tabelas são gerenciadas e consultadas usando SQL (linguagem SQL) que é semelhante entre vários sistemas de banco de dados.
-
Bancos de dados não relacionais (NoSQL) - são sistemas de gerenciamento de dados que não aplicam um esquema relacional aos dados.
-
Key-value databases - cada registro consiste em uma chave exclusiva e um valor associado (chave-valor), que pode estar em qualquer formato. Um armazenamento de chave/valor funciona como uma grande tabela de hash e é otimizado para gravações de dados rápidas. Cada linha de dados é referenciada por um único valor de chave. As únicas operações suportadas são operações simples de consulta, inserção e exclusão. As atualizações de dados exigem que o aplicativo reescreva os dados para o valor inteiro. As consultas podem ser executadas por chave ou por um intervalo de chaves.

- Document databases - são uma forma específica de banco de dados de chave-valor na qual o valor é um documento JSON (em que o sistema é otimizado para análise e consulta). Bancos de dados de documentos é um exemplo de armazenamento de dados não relacional. Armazenam dados no formato JSON ou XML e não exigem que todos os documentos tenham a mesma estrutura. Podem ser usados para manter informações de perfil do usuário, possibilitando armazenar todas as informações em um único bloco.

- Column family databases - podem armazenar dados tabulares que abrangem linhas e colunas.
- Você também pode dividir as colunas em grupos conhecidos como famílias de colunas.
- Cada família de colunas contém um conjunto de colunas que estão logicamente relacionadas.

- Graph databases - que armazenam entidades como nós com links para definir relações entre eles. Bancos de dados de grafos são exemplos de armazenamentos de dados não relacional. Armazenam informações na forma de Edges e Nodes. Eles são usados para representar relacionamentos complexos, como interatividade social.

Um sistema transacional registra transações que encapsulam eventos específicos que a organização deseja controlar. Uma transação pode ser financeira, como a movimentação de dinheiro entre contas em um sistema bancário, ou pode fazer parte de um sistema de varejo, controlando pagamentos de bens e serviços de clientes. Pense na transação como uma unidade de trabalho pequena e discreta.
Os sistemas transacionais geralmente são de alto volume, às vezes manipulando muitos milhões de transações em um dia. Os dados que estão sendo processados têm que estar acessíveis com rapidez. O trabalho executado por sistemas transacionais é geralmente conhecido como OLTP (Online Transactional Processing).
Em um sistema OLTP, os dados são altamente normalizados com o esquema fortemente aplicado na gravação. Em um ambiente OLTP, as alterações feitas são revertidas automaticamente se uma transação não for concluída, de modo que nenhuma transação seja deixada em um estado parcialmente concluído.
Uma workload OLTP tem requisitos de gravação pesados com requisitos de leitura mínimos.
As soluções OLTP dependem de um sistema de banco de dados no qual o armazenamento de dados é otimizado para operações de leitura e gravação para dar suporte aos workloads transacionais nas quais os registros de dados são criados, recuperados, atualizados e excluídos (CRUD).
Essas operações são aplicadas de maneira transacional para garantir a integridade dos dados armazenados no banco de dados. Para fazer isso, os sistemas OLTP impõem transações compatíveis com a semântica conhecida como ACID:
-
Atomicity - cada transação é tratada como uma única unidade, que é totalmente bem-sucedida ou que falha completamente.
- Por exemplo, uma transação que envolve o débito de fundos de uma conta e o crédito do mesmo valor em outra conta deve concluir ambas as ações. Se uma das ações não puder ser concluída, a outra ação deverá falhar.
-
Consistency - as transações só podem conduzir os dados do banco de dados de um estado válido para outro estado válido.
- O estado concluído da transação deve refletir na transferência de fundos de uma conta para outra.
-
Isolation - as transações simultâneas não podem interferir entre si e devem resultar em um estado consistente do banco de dados.
- Enquanto a transação para transferir fundos de uma conta para outra está em processo, outra transação que verifica o saldo dessas contas deve retornar resultados consistentes - a transação de verificação de saldo não pode recuperar um valor para uma conta que reflita o saldo antes da transferência e um valor para a outra conta que reflita o saldo após a transferência.
-
Durability - quando uma transação tiver sido confirmada, ela permanecerá confirmada.
- Depois que a transação de transferência entre contas for concluída, os saldos de conta revisados serão persistidos para que, mesmo que o sistema do banco de dados seja desligado, a transação confirmada seja refletida quando ele for ligado novamente.
Os sistemas OLTP (Online Transactional Processing) normalmente são usados para dar suporte a aplicativos dinâmicos que processam dados de negócios, geralmente chamados de aplicativos de LOB (line of business).
OLAP - O processamento de dados analíticos normalmente usa sistemas somente leitura (ou read-mostly) que armazenam grandes volumes de dados históricos ou métricas de negócios. A análise pode ser baseada em um snapshot dos dados em um determinado momento ou em uma série de snapshots.
Uma arquitetura comum de análise de escala empresarial tem esta aparência:

- Os arquivos de dados podem ser armazenados em um data lake central para análise.
- Um processo de ETL (extração, transformação e carregamento) copia dados de arquivos e bancos de dados OLTP para um data warehouse otimizado para atividade de leitura. Normalmente, o esquema de um data warehouse se baseia em tabelas de fatos que contêm valores numéricos que você deseja analisar (por exemplo, valores de vendas), com tabelas de dimensões relacionadas, que representam as entidades pelas quais você deseja medir (por exemplo, cliente ou produto).
- Os dados no data warehouse podem ser agregados e carregados em um modelo OLAP (processamento analítico online) ou cubo. Valores numéricos agregados (medidas) de tabelas de fatos são calculados para interseções de dimensões da tabelas de dimensões. Por exemplo, a receita de vendas pode ser totalizada por data, cliente e produto.
- Os dados no data lake, no data warehouse e no modelo analítico podem ser consultados para produzir relatórios, visualizações e painéis.
Data lakes são comuns em cenários de processamento analítico de dados em grande escala, em que um grande volume de dados baseados em arquivo precisa ser coletado e analisado.
Data warehouses são uma forma estabelecida de armazenar dados em um esquema relacional otimizado para operações de leitura - principalmente consultas para dar suporte a relatórios e à visualização de dados. O esquema do data warehouse pode exigir alguma desnormalização de dados em uma fonte de dados OLTP (apresentando algumas duplicações para fazer com que as consultas sejam executadas mais rapidamente).
Modelo OLAP é um tipo agregado de armazenamento de dados que é otimizado para cargas de trabalho analíticas. As agregações de dados são feitas entre dimensões em diferentes níveis, permitindo que você faça drill up/down para exibir agregações em vários níveis hierárquicos; por exemplo, para localizar o total de vendas por região, por cidade ou por um endereço individual. Como os dados do OLAP são previamente agregados, as consultas para retornar os resumos que ele contém podem ser executadas rapidamente. Os sistemas de processamento analítico online (OLAP) são projetados para realizar análises complexas e fornecer inteligência de negócios. O OLAP é usado para cargas de trabalho analíticas, como:
- Gerando relatórios ad-hoc complexos que incluem várias agregações.
- Executando análise de big data em um banco de dados NoSQL.
- Um aplicativo para realizar mineração de dados em dados históricos coletados de várias fontes relacionais e não relacionais.
- Um aplicativo para fornecer dados sem normalização para dar suporte à geração de relatórios.
Tipos diferentes de usuários podem executar trabalhos de análise de dados em diferentes estágios da arquitetura geral. Por exemplo:
- Os cientistas de dados podem trabalhar diretamente com arquivos de dados em um data lake para explorar e modelar os dados.
- Os Analistas de Dados podem consultar tabelas diretamente no data warehouse para produzir relatórios e visualizações complexos.
- Os usuários empresariais podem consumir dados previamente agregados em um modelo analítico na forma de relatórios ou painéis.
Os profissionais de dados executam funções distintas na criação e no gerenciamento de soluções de software e trabalham com várias tecnologias e serviços para realizar isso.
Há uma ampla variedade de funções que envolvem gerenciamento, controle e uso de dados. Algumas funções são orientadas aos negócios, outras envolvem mais engenharia e as demais focam na pesquisa, já outras são funções híbridas que combinam diferentes aspectos de gerenciamento de dados.
As três funções de trabalho importantes que lidam com os dados na maioria das organizações são:
- Administradores de Banco de Dados, que gerenciam bancos de dados, atribuindo permissões aos usuários, armazenando cópias de backup de dados e restaurando dados em caso de falhas.
- Engenheiros de dados, que gerenciam a infraestrutura e os processos de integração de dados em toda a organização, aplicando rotinas de limpeza de dados, identificando regras de governança de dados e implementando pipelines para transferir e transformar dados entre sistemas.
- Analistas de Dados, que exploram e analisam dados para criar visualizações e gráficos que permitem que as organizações tomem decisões informadas.
Em algumas organizações, a mesma pessoa pode executar várias funções
Um Administrador de Banco de Dados do Azure é responsável pelos aspectos de design, implementação, manutenção e operação de sistemas de bancos de dados.
- Eles são responsáveis pela disponibilidade geral.
- Desempenho e otimizações consistentes dos bancos de dados.
- Eles trabalham com os stakeholders para implementar políticas e ferramentas.
- Processos de backup.
- Planos de recuperação para serem usados após um desastre natural ou erro humano.
- Gerenciar a segurança dos dados nos bancos de dados.
- Conceder privilégios sobre os dados, além de conceder ou negar acesso aos usuários conforme apropriado.
Um Engenheiro de Dados colabora com os stakeholders para projetar e implementar cargas de trabalho relacionadas a dados.
- Pipelines de ingestão de dados.
- Gerenciar e monitorar pipelines de dados para garantir que as cargas de dados tenham o desempenho esperado.
- Atividades de limpeza e transformação e armazenamentos de dados para cargas de trabalho analíticas.
- Usam uma variedade de tecnologias de plataforma de dados, bancos de dados relacionais e não relacionais, repositórios de arquivos e fluxos de dados.
- Garantir a privacidade dos dados.
Um analista de dados permite que as empresas maximizem o valor dos ativos de dados.
- Responsáveis por explorar dados para identificar tendências e relações
- Projetar e criar modelos analíticos
- Favorecer capacidades avançadas de análise por meio de relatórios e visualizações.
- Processa dados brutos e, com base em requisitos empresariais identificados, os transforma para fornecer insights relevantes.
Há outras funções relacionadas a dados não mencionadas aqui, como cientista de dados e arquiteto de dados, e há outros profissionais técnicos que trabalham com os dados, incluindo desenvolvedores de aplicativos e engenheiros de software.
Azure SQL é o nome coletivo de uma família de soluções de banco de dados relacional com base no mecanismo de banco de dados do Microsoft SQL Server.
- Azure SQL Database - um banco de dados de PaaS (plataforma como serviço) totalmente gerenciado hospedado no Azure.
- Azure SQL Managed Instance - uma instância hospedada do SQL Server com manutenção automatizada, que permite uma configuração mais flexível do que o Azure SQL DB, mas com mais responsabilidade administrativa para o proprietário.
- Azure SQL VM - uma máquina virtual com uma instalação do SQL Server, permitindo a máxima capacidade de configuração com total responsabilidade de gerenciamento.
Administradores de banco de dados normalmente provisionam e gerenciam os sistemas de banco de dados Azure SQL para dar suporte a aplicativos de LOB (linha de negócios) que precisam armazenar dados transacionais.
Engenheiros de dados podem usar os sistemas do Azure SQL DB como fontes para pipelines de dados que executam operações de ETL (extração, transformação e carregamento) para ingerir os dados transacionais em um sistema analítico.
Analistas de dados podem consultar os Azure SQL DB diretamente para criar relatórios, no entanto, em grandes organizações, os dados geralmente são combinados com os dados de outras fontes em um armazenamento de dados analíticos para dar suporte às análises empresariais.
O Azure inclui serviços gerenciados para sistemas de banco de dados relacionais populares de código aberto, incluindo:
- Azure Database for MySQL - um sistema de gerenciamento de banco de dados relacional de código aberto fácil de usar que é comumente usado em aplicativos da pilha LAMP (Linux, Apache, MySQL e PHP).
- Azure Database for MariaDB - um sistema de gerenciamento de banco de dados relacional mais recente, criado pelos desenvolvedores originais do MySQL. O MariaDB tem compatibilidade com o Oracle Database.
- Azure Database for PostgreSQL - um banco de dados híbrido relacional-objeto. É possível armazenar dados em tabelas relacionais, também permite que você armazene tipos de dados personalizados, com propriedades não relacionais próprias.
Os bancos de dados relacionais de código aberto são gerenciados por administradores de banco de dados para dar suporte a aplicativos transacionais e fornecem uma fonte de dados para engenheiros de dados, criando pipelines para soluções analíticas e analistas de dados que criam relatórios.
O Azure Cosmos DB é um sistema de banco de dados não relacional (NoSQL) de escala global que dá suporte a várias APIs, permitindo que você armazene e gerencie dados como documentos JSON, pares chave-valor, famílias de colunas e grafos.
Em algumas organizações, instâncias do Cosmos DB podem ser provisionadas e gerenciadas por um administrador de banco de dados, embora os desenvolvedores de software tenham o costume de gerenciar o armazenamento de dados NoSQL como parte da arquitetura geral do aplicativo. Os engenheiros de dados geralmente precisam integrar fontes de dados do Cosmos DB a soluções analíticas corporativas que dão suporte à modelagem e geração de relatórios por analistas de dados.
O Armazenamento do Azure é um serviço principal do Azure que permite armazenar dados em:
- Blob containers - armazenamento escalonável e econômico para arquivos binários.
- File shares - compartilhamentos de arquivos de rede, semelhante ao que normalmente é encontrado nas redes corporativas.
- Tables - armazenamento de chave-valor para aplicativos que precisam ler e gravar valores de dados rapidamente.
Os engenheiros de dados usam o Armazenamento do Azure para hospedar data lakes - armazenamentos de blobs com um namespace hierárquico que permite que os arquivos sejam organizados em pastas em um sistema de arquivos distribuído.
O Azure Data Factory é um serviço do Azure que permite definir e agendar pipelines de dados para transferir e transformar dados. Você pode integrar seus pipelines a outros serviços do Azure, possibilitando a ingestão de dados de armazenamentos de dados na nuvem, o processamento dos dados usando a computação baseada em nuvem e a manutenção dos resultados em outro armazenamento de dados. O Azure Data Factory é usado para ingerir dados de fontes de dados. Você pode ingerir dados de dados relacionais e dados não estruturados de várias fontes.
Pipeline é um agrupamento lógico de atividades que executa uma tarefa. Você pode ter várias atividades em um pipeline. As atividades podem ser executadas sequencialmente ou em paralelo. Uma atividade representa uma etapa em um pipeline.
O Azure Data Factory é usado por engenheiros de dados para criar soluções de ETL (extração, transformação e carregamento) que preenchem os armazenamentos de dados analíticos com os dados de sistemas transacionais na organização.
O Azure Data Factory pode carregar dados do Azure Blob Storage, Azure Data Lake Storage, Azure Cosmos DB e Azure Synapse Analytics. Você pode até carregar dados de serviços fora do Azure, como o Amazon S3.
O Azure Data Factory pode exportar dados para o Azure Data Lake Storage, Azure Synapse Analytics e muitos outros destinos, como Azure SQL Database, Azure Blob Storage e Azure Cosmos DB.
O Azure Data Factory pode executar pacotes do SQL Server Integration Service (SSIS) usando a atividade Executar Pacote SSIS. Para usar a atividade você precisa configurar o tempo de execução (IR) de integração Azure-SSIS.
O Azure Synapse Analytics é uma solução de análise de dados abrangente e unificada que oferece uma interface de serviço única para vários recursos analíticos, incluindo:
- Pipelines - baseado na mesma tecnologia do Azure Data Factory.
- SQL - um mecanismo de banco de dados SQL altamente escalonável, otimizado para cargas de trabalho de data warehouse.
- Realizar consultas e agregações muito complexas em uma grande quantidade de dados relacionais. Você pode provisionar pools do Synapse SQL para executar rapidamente consultas complexas em vários nós de computador, graças ao processamento paralelo massivo (MPP) do Synapse SQL.
- Apache Spark - um sistema de processamento de dados distribuído de código aberto que dá suporte a várias linguagens de programação e APIs, incluindo Java, Scala, Python e SQL.
- Azure Synapse Data Explorer - uma solução de análise de dados de alto desempenho que é otimizada para consultas em tempo real de dados de log e telemetria usando a KQL (Kusto Query Language).
- Workspaces - espaços de trabalho no Synapse Studio.
- Azure Data Lake Storage Gen 2 - É aqui que os dados, scripts e outros itens são armazenados no Azure Synapse Analytics.
Os engenheiros de dados podem usar o Azure Synapse Analytics para criar uma solução de análise de dados unificada que combina pipelines de ingestão de dados, armazenamento de data warehouse e armazenamento do data lake em um único serviço.
Os analistas de dados podem usar pools de SQL e do Spark por meio de notebooks interativos para explorar e analisar dados e aproveitar a integração com serviços como Azure Machine Learning e Microsoft Power BI para criar modelos de dados e extrair insights dos dados.
O Azure Databricks combina a plataforma de processamento de dados Apache Spark com a semântica de banco de dados SQL e uma interface Web de gerenciamento integrada para permitir a análise de dados em larga escala.
Os engenheiros de dados podem usar as habilidades que já têm do Databricks e do Spark para criar armazenamentos de dados analíticos no Azure Databricks.
Os analistas de dados podem usar o suporte nativo ao notebook no Azure Databricks para consultar e visualizar dados em uma interface baseada na Web fácil de usar.
O Azure HDInsight é um serviço do Azure que fornece clusters hospedados no Azure para tecnologias de código aberto de processamento de Big Data do Apache, incluindo:
- Apache Spark - um sistema de processamento de dados distribuído que dá suporte a várias linguagens de programação e APIs, incluindo Java, Scala, Python e SQL.
- Apache Hadoop - um sistema distribuído que usa trabalhos MapReduce para processar grandes volumes de dados com eficiência em vários nós de cluster. Os trabalhos MapReduce podem ser escritos em Java ou abstraídos por interfaces como Apache Hive (API baseada em SQL que é executada no Hadoop).
- Apache HBase - um sistema de código aberto para armazenamento e consulta de dados NoSQL em larga escala.
- Apache Kafka - um agente de mensagens para processamento de fluxo de dados.
- Apache Storm - um sistema de código aberto para processamento de dados em tempo real por meio de uma topologia de spouts e bolts.
Os engenheiros de dados podem usar o Azure HDInsight para dar suporte a cargas de trabalho de análise de Big Data que dependem de várias tecnologias de código aberto.
O Azure Stream Analytics é um mecanismo de processamento de fluxo em tempo real que captura um fluxo de dados de uma entrada, aplica uma consulta para extrair e manipular os dados do fluxo e grava os resultados em uma saída para análise ou processamento adicional.
Os engenheiros de dados podem incorporar o Azure Stream Analytics em arquiteturas de análise de dados que capturam fluxos dados para ingestão em um armazenamento de dados analíticos ou para visualização em tempo real.
O Azure Data Explorer é um serviço autônomo que oferece a mesma consulta de alto desempenho de dados de log e telemetria que o runtime do Azure Synapse Data Explorer no Azure Synapse Analytics.
Os analistas de dados podem usar o Azure Data Explorer para consultar e analisar dados que incluem um atributo de timestamp, como normalmente é encontrado em arquivos de log e dados de telemetria da IoT (Internet das Coisas).
O Microsoft Purview fornece uma solução para governança e descoberta de dados de toda a empresa. Use o Microsoft Purview para criar um mapa de seus dados e acompanhar a linhagem de dados em várias fontes de dados e sistemas, permitindo encontrar dados confiáveis para análise e relatórios.
Os engenheiros de dados podem usar o Microsoft Purview para impor a governança de dados em toda a empresa e garantir a integridade dos dados usados para dar suporte a cargas de trabalho analíticas.
O Microsoft Power BI é uma plataforma para modelagem de dados analíticos e relatórios que os analistas de dados podem usar para criar e compartilhar visualizações de dados interativas. Os relatórios do Power BI podem ser criados por meio do aplicativo Power BI Desktop e, em seguida, publicados e fornecidos por meio de relatórios e aplicativos baseados na Web no serviço do Power BI, bem como no aplicativo móvel do Power BI.
Em um banco de dados relacional, você modelará coleções de entidades do mundo real na forma de tabelas. Uma entidade pode ser qualquer coisa para a qual você deseja registrar informações; geralmente objetos e eventos importantes. Uma tabela contém linhas e cada linha representa uma instância de uma entidade. As tabelas relacionais são um formato para dados estruturados e cada linha de uma tabela tem as mesmas colunas. Cada coluna armazena dados de um tipo de dados específico (texto, datas, números inteiros e decimais).
A normalização é um termo usado por profissionais de banco de dados para um processo de design de esquema que minimiza a duplicação e impõe a integridade dos dados.
- Separar cada entidade em sua própria tabela.
- Separar cada atributo discreto em sua própria coluna.
- Identificar exclusivamente cada instância de entidade (linha) usando uma chave primária.
- Usar colunas de chave estrangeira para vincular entidades relacionadas.
Cada entidade que é representada nos dados (cliente, produto, pedido de venda e item) é armazenada em sua própria tabela e cada atributo discreto dessas entidades está em sua própria coluna.
O registro de cada instância de uma entidade como uma linha em uma tabela específica da entidade remove a duplicação dos dados.
A decomposição de atributos em colunas individuais garante que cada valor seja restrito a um tipo de dados apropriado e fornece um nível útil de granularidade nos dados para consulta.
As instâncias de cada entidade são identificadas exclusivamente por uma ID ou outro valor de chave, conhecido como chave primária; e quando uma entidade faz referência a outra (por exemplo, um pedido tem um cliente associado), a chave primária da entidade relacionada é armazenada como uma chave estrangeira.
Normalmente, um RDBMS (sistema de gerenciamento de banco de dados relacional) pode impor a integridade referencial para garantir que um valor inserido em um campo de chave estrangeira tenha uma chave primária correspondente existente na tabela relacionada, por exemplo, impedindo pedidos de clientes inexistentes.
Em alguns casos, uma chave (primária ou estrangeira) pode ser definida como uma chave composta com base em uma combinação exclusiva de várias colunas.
SQL (Structured Query Language) é usada para se comunicar com um banco de dados relacional. Ela é a linguagem padrão para sistemas de gerenciamento de banco de dados relacional. As instruções SQL são usadas para executar tarefas como atualizar ou recuperar dados de um banco de dados.
O SQL foi originalmente padronizado pelo ANSI (American National Standards Institute) em 1986 e pela ISO (Organização Internacional de Normalização) em 1987. Desde então, o padrão foi estendido várias vezes, pois os fornecedores de banco de dados relacional adicionaram novos recursos aos sistemas que não fazem parte do padrão, o que resultou em uma variedade de dialetos do SQL.
Alguns dialetos populares do SQL incluem:
- T-SQL (Transact-SQL) - Essa versão do SQL é usada pelo Microsoft SQL Server e pelos serviços de SQL do Azure.
- pgSQL - Esse é o dialeto que tem extensões implementadas no PostgreSQL.
- PL/SQL - Esse é o dialeto usado pela Oracle. PL/SQL significa Procedural Language/SQL.
Instruções SQL são agrupadas em três grupos lógicos principais:
-
DDL (linguagem de definição de dados) - Você usa instruções DDL para criar, modificar e remover tabelas e outros objetos em um banco de dados (tabela, procedimentos armazenados, exibições, entre outros). As instruções DDL mais comuns são:
- CREATE - Cria um objeto no banco de dados, como uma tabela ou uma view.
- ALTER - Modifica a estrutura de um objeto. Por exemplo, alterar uma tabela para adicionar uma nova coluna.
- DROP - Remova um objeto do banco de dados.
- RENAME - Renomeia um objeto existente.
-
DCL (linguagem de controle de dados) - Os administradores de banco de dados geralmente usam instruções DCL para gerenciar o acesso a objetos em um banco de dados, concedendo, negando ou revogando permissões a usuários ou grupos específicos. As três instruções DCL principais são:
- GRANT - Conceder permissão para executar ações específicas
- DENY - Negar permissão para executar ações específicas
- REVOKE - Remover uma permissão concedida anteriormente
-
DML (linguagem de manipulação de dados) - Você usa instruções DML para manipular as linhas em tabelas. Essas instruções permitem recuperar (consultar) dados, inserir novas linhas ou modificar linhas existentes. Você também poderá excluir linhas se não precisar mais delas.
- SELECT - Ler linhas de uma tabela
- INSERT - Inserir novas linhas em uma tabela
- UPDATE - Modificar dados em linhas existentes
- DELETE - Excluir linhas existentes
A forma básica de uma instrução INSERT insere uma linha por vez. Por padrão, as instruções SELECT, UPDATE e DELETE são aplicadas a todas as linhas em uma tabela. Normalmente, você aplica uma cláusula WHERE com essas instruções para especificar critérios. Somente as linhas que correspondem a esses critérios serão selecionadas, atualizadas ou excluídas.
Você também pode executar instruções SELECT que recuperam dados de várias tabelas usando uma cláusula JOIN. As junções indicam como as linhas em uma tabela são conectadas com as linhas em outra tabela a fim de determinar quais dados retornar. Uma condição de junção típica corresponde a uma chave estrangeira de uma tabela e a chave primária associada na outra tabela.
A instrução INSERT tem um formato um pouco diferente. Você especifica uma tabela e as colunas em uma cláusula INTO e uma lista de valores a serem armazenados nessas colunas. O SQL Standard dá suporte apenas à inserção de uma linha por vez. Alguns dialetos permitem que você especifique várias cláusulas VALUES para adicionar várias linhas por vez.
Além das tabelas, um banco de dados relacional pode conter outras estruturas que ajudam a otimizar a organização dos dados, encapsular ações programáticas e aprimorar a velocidade de acesso.
É uma tabela virtual com base no conjunto de resultados de uma consulta SELECT. É possível consultar a view e filtrar os dados de maneira muito semelhante à de uma tabela.
Define instruções SQL que podem ser executadas sob comando. Os procedimentos armazenados são usados para encapsular lógica programática de ações em um banco de dados que os aplicativos precisam executar ao trabalhar com os dados. Você pode definir um stored procedure com parâmetros para criar uma solução flexível para ações comuns que talvez precisem ser aplicadas aos dados com base em uma chave ou em critérios específicos. Por exemplo, o procedimento armazenado a seguir pode ser definido para alterar o nome de um produto com base na ID do produto especificada.
CREATE PROCEDURE RenameProduct
@ProductID INT,
@NewName VARCHAR(20)
AS
UPDATE Product
SET Name = @NewName
WHERE ID = @ProductID;Quando um produto precisa ser renomeado, você pode executar o procedimento armazenado, passando a ID do produto e o novo nome a ser atribuído:
EXEC RenameProduct 201, 'Spanner';Um índice ajuda a pesquisar dados em uma tabela. Imagine um índice em uma tabela como um índice no final de um livro. Um índice de livro contém um conjunto classificado de referências, com as páginas nas quais cada referência ocorre. Quando você deseja encontrar uma referência a um item no livro, procura por ela no índice. Você pode usar os números de página no índice para ir diretamente para as páginas corretas no livro. Sem um índice, talvez seja necessário ler todo o livro para localizar as referências que você está procurando.
Quando você cria um índice em um banco de dados, especifica uma coluna da tabela e o índice contém uma cópia desses dados em uma ordem classificada, com ponteiros para as linhas correspondentes na tabela. Quando o usuário executa uma consulta que especifica essa coluna na cláusula WHERE, o sistema de gerenciamento de banco de dados pode usar esse índice para buscar os dados mais rapidamente do que se precisasse examinar toda a tabela, linha por linha.
CREATE INDEX idx_ProductName
ON Product(Name);O índice cria uma estrutura baseada em árvore que o otimizador de consulta do sistema do banco de dados pode usar para localizar rapidamente linhas na tabela.

Em uma tabela que contém poucas linhas, o uso do índice provavelmente não será eficiente. No entanto, quando uma tabela tem muitas linhas, os índices podem melhorar drasticamente o desempenho das consultas.
É possível criar vários índices em uma tabela. No entanto, os índices não são gratuitos. Um índice consome espaço de armazenamento e sempre que você insere, atualiza ou exclui dados em uma tabela, é necessário haver manutenção nos índices dessa tabela. Esse trabalho adicional pode causar lentidão nas operações de inserção, atualização e exclusão. Você precisa ter um equilíbrio entre o uso índices que aceleram suas consultas e o custo de executar outras operações.
O Azure dá suporte a vários serviços de banco de dados, permitindo que você execute sistemas de gerenciamento de banco de dados relacionais populares, como SQL Server, PostgreSQL e MySQL na nuvem.
A maioria dos serviços de banco de dados do Azure é totalmente gerenciada, liberando um tempo valioso que você gastaria gerenciando seu banco de dados.
O desempenho de nível empresarial com alta disponibilidade interna significa que você pode escalar rapidamente e alcançar distribuição global sem se preocupar com o tempo de inatividade dispendioso.
Os desenvolvedores podem aproveitar as inovações líderes do setor, como segurança interna com monitoramento automático e detecção de ameaças, além de ajuste automático para aprimorar o desempenho. Além de todos esses recursos, você tem a disponibilidade garantida.
Azure SQL é um termo coletivo para uma família de serviços de banco de dados baseados no Microsoft SQL Server no Azure. Os serviços específicos de SQL do Azure incluem:
Uma máquina virtual em execução no Azure com uma instalação do SQL Server. Solução IaaS (infraestrutura como serviço) que virtualiza a infraestrutura de hardware para computação, armazenamento e rede no Azure, tornando-a uma ótima opção para migração "lift-and-shift" de instalações locais existentes do SQL Server para a nuvem.
| Azure SQL Server em VMs (Máquinas Virtuais) | |
|---|---|
| Compatibilidade | Totalmente compatível com instalações físicas locais e virtualizadas. |
| Arquitetura | Instâncias do SQL Server são instaladas em uma máquina virtual. Cada instância pode dar suporte a vários bancos de dados. |
| Disponibilidade | 99,99% |
| Gerenciamento | Você deve gerenciar todos os aspectos do servidor, incluindo o sistema operacional e as atualizações, a configuração, os backups e outras tarefas de manutenção do SQL Server. |
| Casos de uso | Use essa opção quando precisar migrar ou estender uma solução de SQL Server local e manter o controle total sobre todos os aspectos da configuração do servidor e do banco de dados. |
Migrar do sistema em execução no local para uma máquina virtual do Azure não é diferente de mover um banco de dados de um servidor local para outro. Essa abordagem é adequada para migrações e aplicativos que exigem acesso a recursos do sistema operacional que podem não ser compatíveis no nível de PaaS.
Preparar o lift-and-shift de aplicativos existentes que exigem migração rápida para a nuvem com poucas ou nenhuma alteração.
Você também pode usar o SQL Server em VMs para estender aplicativos locais existentes para a nuvem em implantações híbridas.
Criar cenários rápidos de desenvolvimento e teste quando você não quiser comprar hardware do SQL Server local que não seja de produção.
Escalar verticalmente a plataforma em que o SQL Server é executado. É possível redimensionar rapidamente uma máquina virtual do Azure sem a necessidade de reinstalar o software que está sendo executado nela.
O SQL Server nas Máquinas Virtuais do Azure oferece uma experiência administrativa semelhante ao seu servidor local, o que aumentará seu esforço administrativo. Essa forma de serviço em nuvem exige a maior responsabilidade do cliente, pois ele precisa gerenciar tudo, exceto os dispositivos físicos usados.
Uma opção de PaaS (plataforma como serviço) que fornece quase 100% de compatibilidade com instâncias de SQL Server locais, abstraindo o hardware e o sistema operacional subjacentes. O serviço inclui gerenciamento automatizado de atualizações de software, backups e outras tarefas de manutenção, reduzindo a carga administrativa do suporte a uma instância de servidor de banco de dados.
| Azure SQL Managed Instance | |
|---|---|
| Compatibilidade | Quase 100% de compatibilidade com SQL Server Enterprise Edition. A maioria dos bancos de dados locais pode ser migrada com alterações mínimas no código, usando o serviço Azure Database Migration (ADM). |
| Arquitetura | Cada instância gerenciada pode dar suporte a vários bancos de dados. Além disso, os pools de instâncias podem ser usados para compartilhar recursos com eficiência em instâncias menores. |
| Disponibilidade | 99,99% |
| Gerenciamento | Backups e recuperação totalmente automatizados, aplicação de patch/atualizações de software e OS, monitoramento de banco de dados e outras tarefas gerais, mas você tem controle total sobre a segurança e a alocação de recursos para os seus bancos de dados. Configuração de alta disponibilidade e de fluxo de dados de monitoramento de desempenho e integridade. Redimensionamento e configuração de instâncias dinâmicas e replicação de banco de dados (incluindo banco de dados do sistema). |
| Casos de uso | Use essa opção para a maioria dos cenários de migração na nuvem, especialmente quando você precisar de alterações mínimas nos aplicativos existentes. |
As instâncias gerenciadas dependem de outros serviços do Azure, como o Azure Storage para backups, o Azure Event Hubs para telemetria, o Azure Active Directory para autenticação, o Azure Key Vault para TDE (Transparent Data Encryption) e alguns serviços da plataforma Azure que fornecem recursos de segurança e compatibilidade.
Todas as comunicações são criptografadas e assinadas usando certificados.
Considere a Azure SQL Managed Instance se você quiser fazer o lift-and-shift de uma instância do SQL Server local e todos os seus bancos de dados para a nuvem, sem incorrer na sobrecarga de gerenciamento da execução do SQL Server em uma máquina virtual.
A Azure SQL Managed Instance é usada para implantação em que você precisa ter paridade de recursos completa com o SQL Server local.
A Azure SQL Managed Instance fornece recursos que não estão disponíveis no do Azure SQL DB. Se o sistema usar recursos como:
- Servidores vinculados
- Service Broker (um sistema de processamento de mensagens que pode ser usado para distribuir o trabalho entre servidores)
- Database Mail (que permite ao seu banco de dados enviar mensagens de email para os usuários)
- SQL Server Agent
Para verificar a compatibilidade com um sistema local existente, instale o AMD (Assistente de Migração de Dados). Essa ferramenta analisa seus bancos de dados no SQL Server e relata problemas que possam bloquear a migração para uma instância gerenciada.
A Azure SQL Managed Instance dá suporte a logons do Mecanismo de banco de dados do SQL Server e logons integrados ao Azure AD (Active Directory).
- Os logons do Mecanismo de banco de dados do SQL Server incluem um nome de usuário e uma senha. Você deve inserir suas credenciais sempre que se conectar ao servidor.
- Os logons do Azure AD usam as credenciais associadas à sua entrada atual do computador e você não precisa fornecê-las sempre que se conectar ao servidor.
Um serviço de banco de dados de PaaS totalmente gerenciado e altamente escalonável. Esse serviço inclui os principais recursos de nível de banco de dados do SQL Server local e é uma boa opção se você precisa criar um aplicativo na nuvem.
| Azure SQL Database | |
|---|---|
| Compatibilidade | Dá suporte à maioria dos principais recursos de nível de banco de dados do SQL Server. Alguns recursos que dependem de um aplicativo local podem não estar disponíveis. |
| Arquitetura | Você pode provisionar um banco de dados individual em um servidor dedicado e gerenciado (lógico) ou você pode usar um pool elástico para compartilhar recursos entre vários bancos de dados para aproveitar a escalabilidade sob demanda. |
| Disponibilidade | 99,995% |
| Gerenciamento | Atualizações, backups e recuperação totalmente automatizados. |
| Casos de uso | Use essa opção para novas soluções de nuvem ou migrar aplicativos que têm dependências mínimas no nível da instância. Aplicativos de nuvem modernos que precisam usar os recursos estáveis de SQL Server mais recentes. Aplicativos que exigem alta disponibilidade. Sistemas com uma carga variável que precisam do servidor de banco de dados para escalar e reduzir verticalmente de modo rápido. |
O Azure SQL Database tem um custo menor em comparação com a Instância Gerenciada de SQL do Azure. Embora a Instância Gerenciada de SQL do Azure também seja um PaaS, o Azure SQL Database elimina mais tarefas administrativas, como remover a necessidade de gerenciar a configuração do SQL Server e maior disponibilidade.
O Servidor do Banco de Dados SQL é um constructo lógico que atua como um ponto administrativo central para um banco de dados individual ou em pool, logons, regras de firewall, regras de auditoria, políticas de detecção de ameaças e grupos de failover.
-
Single Database - Você cria e executa um servidor de banco de dados na nuvem e acessa o banco de dados por meio desse servidor.
- A Microsoft gerencia o servidor, de modo que tudo o que você precisa fazer é configurar o banco de dados, criar suas tabelas e preenchê-las com os seus dados.
- Você pode escalar o banco de dados se precisar de mais recursos. Por padrão, os recursos são alocados previamente e você é cobrado por hora pelos recursos que solicitou.
- Também é possível especificar uma configuração sem servidor. Nessa configuração é criado um servidor próprio, que pode ser compartilhado por bancos de dados pertencentes a outros assinantes do Azure. A Microsoft garante a privacidade do seu banco de dados.
- O banco de dados é dimensionado automaticamente e os recursos são alocados ou desalocados conforme necessário.
-
Elastic Pool - Essa opção é semelhante ao Banco de Dados Individual. No entanto, por padrão, vários bancos de dados podem compartilhar os mesmos recursos por meio de multilocação. Os recursos são chamados de pool. Você cria o pool e somente seus bancos de dados podem usá-lo. Esse modelo será útil se você tiver bancos de dados com requisitos de recursos que variam ao longo do tempo. Além disso, ajuda a economizar. O Pool Elástico permite usar os recursos disponíveis no pool e liberá-los após a conclusão do processamento.
O Azure SQL Database oferece a melhor opção de baixo custo com administração mínima. Não é totalmente compatível com as instalações locais do SQL Server. Geralmente, é usada em novos projetos de nuvem em que o design do aplicativo pode acomodar as alterações necessárias em seus aplicativos.
O Azure SQL Database é compatível com a restauração pontual, recuperação de um DB para o estado em que estava em qualquer ponto no passado. É possível replicar bancos de dados para regiões diferentes fornecendo mais resiliência e recuperação de desastre.
A proteção avançada contra ameaças (Advanced threat protection) fornece recursos de segurança avançados:
- Avaliações de vulnerabilidade, para ajudar a detectar e corrigir possíveis problemas de segurança com seus bancos de dados.
- Proteção contra ameaças detecta atividades anômalas que indicam tentativas incomuns e potencialmente prejudiciais de acessar ou explorar seu banco de dados.
- Monitora continuamente o banco de dados com relação a atividades suspeitas e fornece alertas de segurança imediatos sobre possíveis vulnerabilidades, ataques de injeção de SQL e padrões de acesso anormal do banco de dados.
- Os alertas da proteção contra ameaças fornecem detalhes de atividades suspeitas e recomendam ações para investigar e atenuar a ameaça.
A auditoria rastreia eventos de banco de dados e os grava em um log de auditoria na Azure storage account. Pode ajudar a manter uma conformidade regulatória, a entender a atividade do banco de dados e a obter informações sobre discrepâncias e anomalias que poderiam indicar preocupações de negócios ou suspeitas de violações de segurança.
O Banco de Dados SQL ajuda a proteger seus dados, fornecendo criptografia que protege os dados armazenados no banco de dados (em repouso) e enquanto está sendo transferido pela rede (em movimento).
O Azure SQL Database oferece um único banco de dados na nuvem com custo e administração mínimos. O Azure gerencia tarefas administrativas, como backup e recuperação. No entanto, não implementa recursos como SQL Server Agent e Database Mail. O Azure SQL Database não é totalmente compatível com instalações locais do SQL Server. Alguns recursos estão disponíveis no SQL Server local que não estão disponíveis no Azure SQL Database. O Azure SQL Database não dá suporte ao Database Mail. Esse recurso, que permite que o banco de dados envie mensagens de email aos usuários, não está disponível. No entanto, é oferecido na Azure SQL Managed Instance e no SQL Server em Máquinas Virtuais do Azure.
O Azure SQL Database tem um custo menor em comparação com a Azure SQL Managed Instance. Não permite controle total sobre o mecanismo do SQL Server.
Um mecanismo SQL que é otimizado para cenários de IoT (Internet das Coisas) que precisam trabalhar com transmissão de dados de séries temporais.
Além dos serviços de SQL do Azure, há serviços disponíveis para outros sistemas de DB relacionais populares, incluindo MySQL, MariaDB e PostgreSQL. O propósito desses serviços é permitir que as organizações que os usam em aplicativos locais migrem para o Azure rapidamente, sem fazer alterações significativas em seus aplicativos.
MySQL, MariaDB e PostgreSQL são sistemas de gerenciamento de banco de dados relacionais personalizados para diferentes especializações.
O Banco de Dados do Azure para MySQL é uma implementação de PaaS do MySQL na nuvem do Azure baseada na Community Edition do MySQL.
O serviço inclui alta disponibilidade sem custo adicional e escalabilidade de acordo com a necessidade. Você paga apenas pelo que usa. É possível fazer backups automáticos com restauração pontual.
O servidor fornece segurança de conexão para impor regras de firewall e, opcionalmente, exigir conexões SSL. Permite definir configurações do servidor, como modos de bloqueio, número máximo de conexões e tempos limite.
Determinadas operações não estão disponíveis no Banco de Dados do Azure para MySQL. Essas funções se encarregam principalmente da segurança e da administração. O Azure gerencia esses aspectos do próprio servidor de banco de dados.
O Banco de Dados do Azure para MySQL tem duas opções de implantação:
- Azure Database for MySQL Flexible Server - é uma oferta de banco de dados como serviço totalmente gerenciado com desempenho previsível e escalabilidade dinâmica. O servidor flexível oferece controle mais granular e maior flexibilidade para configuração e funções de gerenciamento de banco de dados. O servidor flexível é a opção de implantação recomendada para todos os novos desenvolvimentos ou migrações.
- Azure Database for MySQL Single Server - Servidores únicos são mais adequados para aplicativos existentes que já utilizam um servidor único.
Os seguintes recursos estão disponíveis no Banco de Dados do Azure para MySQL:
- Recursos internos de alta disponibilidade.
- Desempenho previsível.
- Dimensionamento fácil que responde rapidamente à demanda.
- Proteção dos dados, em repouso e em movimento.
- Backups automáticos e restauração pontual dos últimos 35 dias.
- Segurança de nível empresarial e conformidade com a legislação.
O sistema usa o pay-as-you-go para que você pague apenas pelo que usar.
Os servidores do Banco de Dados do Azure para MySQL oferecem recursos de monitoramento para adicionar alertas e ver métricas e logs.
É uma implementação do sistema de gerenciamento de banco de dados MariaDB adaptado para execução no Azure. Baseia-se na Community Edition do MariaDB.
O banco de dados é totalmente gerenciado e controlado pelo Azure. Depois de provisionar o serviço e transferir seus dados, o sistema não requer quase nenhuma administração adicional.
O Banco de Dados do Azure para MariaDB oferece:
- Alta disponibilidade interna sem nenhum custo adicional.
- Desempenho previsível, com preços pré-pagos inclusivos.
- Dimensionamento em segundos, conforme o necessário.
- Proteção para dados confidenciais em repouso e em movimento.
- Backups automáticos e restauração pontual por até 35 dias.
- Segurança e conformidade de nível empresarial.
Você poderá escolher Banco de Dados do Azure para PostgreSQL para executar uma implementação de PaaS do PostgreSQL na nuvem do Azure. Esse serviço fornece os mesmos benefícios de disponibilidade, desempenho, dimensionamento, segurança e administração que o MySQL.
Alguns recursos dos bancos de dados PostgreSQL locais não estão disponíveis Azure PostgreSQL, extensões que os usuários podem adicionar a um banco de dados, escrever stored procedures em várias linguagens de programação (além de pgsql, que está disponível) e interagir diretamente com o sistema operacional. Há compatibilidade com um conjunto básico de extensões usadas com mais frequência e a lista de extensões disponíveis está sob análise contínua.
O Banco de Dados do Azure para PostgreSQL tem três opções de implantação:
-
Azure Database for PostgreSQL Single Server - Você escolhe entre três tipos de preço: Básico, Uso Geral e Otimizado para Memória. Cada tipo é compatível com diferentes números de CPUs, memória e tamanhos de armazenamento – você seleciona uma com base na carga que espera processar.
-
Azure Database for PostgreSQL Flexible Server - A opção de implantação de servidor flexível para PostgreSQL é um serviço de banco de dados totalmente gerenciado. Ele fornece mais controle e personalizações de configuração do servidor e tem melhores controles de otimização de custo.
-
Azure Database for PostgreSQL Hyperscale (Citus) - é uma opção de implantação que dimensiona consultas em vários nós de servidor (cluster) para processar grandes cargas de banco de dados. Seu banco de dados é dividido horizontalmente entre nós. Os dados são divididos em partes com base no valor de uma partition key ou sharding key. Considere usar essa opção de implantação para as maiores implantações de banco de dados do PostgreSQL na nuvem do Azure.
O Banco de Dados do Azure para PostgreSQL é um serviço altamente disponível. Ele contém mecanismos internos de detecção de falha e failover.
Os usuários do PostgreSQL conhecerão a ferramenta pgAdmin, que você pode usar para gerenciar e monitorar um banco de dados PostgreSQL. No entanto, alguns recursos voltados para o servidor, como executar backup e restauração do servidor, não estão disponíveis porque o servidor é gerenciado e mantido pela Microsoft.
O Banco de Dados do Azure para PostgreSQL registra informações sobre as consultas executadas e as salva em um banco de dados chamado azure_sys. Consulte a view query_store.qs_view para para monitorar as consultas que os usuários estão executando e verificar se precisa ajustar as consultas executadas por seus aplicativos.
O Banco de Dados do Azure para PostgreSQL impõe conexões TLS por padrão, melhora a segurança criptografando a conexão entre o cliente e o servidor de banco de dados.
O Banco de Dados do Azure para PostgreSQL dá suporte à autenticação do Azure AD.
Azure Blob Storage é um serviço que permite armazenar grandes quantidades de dados não estruturados como objetos grandes binários, ou blobs, na nuvem. Os blobs são uma maneira eficiente de armazenar arquivos de dados em um formato otimizado para armazenamento baseado em nuvem, e os aplicativos podem lê-los e gravá-los usando a Azure blob storage API.

Em uma Azure storage account você armazena blobs em contêineres. Um contêiner oferece uma maneira prática de agrupar blobs relacionados. Você controlar quem pode ler e gravar blobs dentro de um contêiner no nível do contêiner.
Dentro de um contêiner, você pode organizar blobs em uma hierarquia de pastas virtuais. Você não pode executar operações no nível da pasta para controlar o acesso ou executar operações em massa.
Para implementar a segurança de nível de pasta e diretório no Azure Storage, você precisa habilitar o namespace hierárquico. A habilitação do namespace hierárquico permite que você organize seus contêineres de blob em pastas e diretórios, permitindo definir permissões compatíveis com POSIX e controle de acesso baseado em função (RBAC) em seu contêiner.
O Azure Blob storage é compatível com três tipos diferentes de blob:
-
Block blobs - Um blob de blocos é tratado como um conjunto de blocos. Cada bloco pode variar em tamanho, até 100 MB. Um blob de blocos pode conter até 50 mil blocos, fornecendo um tamanho máximo de mais de 4,7 TB. O bloco é a menor quantidade de dados que podem ser lidos ou gravados como uma unidade individual. Os blobs de blocos são mais bem usados para armazenar objetos binários, grandes e discretos que são alterados com pouca frequência.
-
Page blobs - Um blob de páginas é organizado como uma coleção de páginas de tamanho fixo de 512 bytes. Um blob de páginas é otimizado para dar suporte a operações de leitura e gravação aleatórias; você pode buscar e armazenar dados para uma página, se necessário. Um blob de páginas pode conter até 8 TB de dados. O Azure usa blobs de páginas para implementar o armazenamento em disco virtual para máquinas virtuais.
-
Append blobs - Um blob de acréscimo é um blob de blocos otimizado para dar suporte a operações de acréscimo. Você só pode adicionar blocos ao final de um blob de acréscimo; não há suporte à atualização ou à exclusão de blocos existentes. Cada bloco pode variar em tamanho, até 4 MB. O tamanho máximo de um blob de acréscimo é de mais de 195 GB.
Blob storage fornece três camadas de acesso, que ajudam a balancear a latência de acesso e o custo de armazenamento:
-
Hot tier - é a padrão. Você usa essa camada para blobs que são acessados com frequência. Os dados de blob são armazenados em mídia de alto desempenho.
-
Cool tier - A camada de acesso esporádico tem desempenho inferior e incorre em custos de armazenamento reduzidos em comparação a camada Hot. Use a camada Fria para dados que são acessados com pouca frequência. Você pode migrar um blob da camada Fria de volta para a camada Quente.
-
Archive - oferece o menor custo de armazenamento, mas com maior latência. A camada Arquivos se destina a dados históricos que não devem ser perdidos, mas é necessária apenas raramente. Os blobs na camada Arquivos são efetivamente armazenados em um estado offline. A latência de leitura pode levar horas para que os dados fiquem disponíveis. Para recuperar um blob da camada Arquivos, você precisa alterar a camada de acesso para Quente ou Fria. Em seguida, o blob será reidratado.
Uma política de gerenciamento do ciclo de vida pode migrar automaticamente um blob da camada Quente para a Fria e para a camada Arquivos e também pode ser organizada para excluir blobs desatualizados.
O Azure Data Lake Store (Gen1) é um serviço separado de armazenamento de dados hierárquicos para data lakes analíticos criado com base no armazenamento de BLOBs do Azure, geralmente usado pelas chamadas soluções analíticas de big data que funcionam com dados estruturados, semiestruturados e não estruturados armazenados em arquivos.
O Azure Data Lake Storage Gen2 é uma versão mais recente desse serviço integrado ao Azure Storage, o que permite que você aproveite a escalabilidade do armazenamento de blobs e o controle de custos das camadas de armazenamento. Isso tudo combinado com os recursos do sistema de arquivos hierárquicos e a compatibilidade com os principais sistemas de análise do Azure Data Lake Store.
Sistemas como o Hadoop no Azure HDInsight, Azure Databricks e Azure Synapse Analytics podem montar uma rede de arquivos distribuídos hospedada no Azure Data Lake Store Gen2 e usá-lo para processar grandes volumes de dados.
Para criar um sistema de arquivos do Azure Data Lake Store Gen2, você deve habilitar a opção Namespace Hierárquico (Hierarchical Namespace) de uma Storage account. No entanto, esteja ciente de que a atualização é um processo unidirecional – depois de atualizar uma Storage account para dar suporte a um namespace hierárquico para armazenamento de blobs, você não pode revertê-lo para um namespace simples.
- O Azure Data Lake Storage permite namespace hierárquico compatível com o Hadoop Distributed File System (HDFS). O Azure Data Lake Storage fornece uma camada para acessar os dados do Azure Blob Storage como um armazenamento HDFS, incluindo suporte para organizar arquivos em diretórios e subdiretórios.
Você pode reduzir ainda mais o custo de armazenamento usando recursos como o ciclo de vida do armazenamento para arquivar ou mover dados que não são usados com frequência para camadas de armazenamento mais baratas.
O Azure File storage é essencialmente uma maneira de criar compartilhamentos de rede baseados em nuvem, como normalmente você encontra em organizações locais para disponibilizar documentos e outros arquivos para vários usuários. Ao hospedar Azure File storage, as organizações podem eliminar custos de hardware e sobrecarga de manutenção e se beneficiar de alta disponibilidade e armazenamento em nuvem escalonável para arquivos.

O Azure File storage permite que você compartilhe até 100 TB de dados em uma conta de armazenamento. Esses dados podem ser distribuídos em qualquer número de file shares na conta. O tamanho máximo de um arquivo é 1 TB, mas você pode definir cotas para limitar o tamanho de cada compartilhamento embaixo desta figura. No momento, o Azure File storage dá suporte a até duas mil conexões simultâneas por arquivo compartilhado.
Depois de criar uma Storage Account, você poderá carregar arquivos para o Azure File storage usando o portal do Azure ou ferramentas como o utilitário AzCopy. Você também pode usar o serviço Azure File Sync para sincronizar cópias armazenadas em cache localmente de arquivos compartilhados com os dados no Azure File storage.
O Azure File storage oferece dois níveis de desempenho.
- Standard tier - usa um hardware baseado em disco rígido (HDD) em um datacenter.
- Premium tier - usa discos de estado sólido (SSD). A camada Premium oferece maior taxa de transferência, mas é cobrada a uma taxa mais alta.
O Azure File storage dão suporte a dois protocolos de rede comuns de compartilhamento de arquivos:
- SMB (Server Message Block) é comumente usado em vários sistemas operacionais (Windows, Linux, macOS).
- Network File System (NFS) são usados por algumas versões do Linux e do macOS. Para criar um compartilhamento NFS, você deve usar uma Storage Account de camada premium e criar e configurar uma rede virtual por meio da qual o acesso ao compartilhamento possa ser controlado.
O Azure Table storage é uma solução de armazenamento NoSQL que utiliza tabelas contendo itens de dados de chave/valor. Cada item é representado por uma linha que contém colunas para os campos de dados que precisam ser armazenados.
Uma Tabela do Azure permite que você armazene dados semiestruturados.
Todas as linhas de uma tabela devem ter uma chave exclusiva (composta por uma partition key e uma row key) e, quando você modifica dados em uma tabela, uma coluna de timestamp registra a data e hora em que a modificação foi feita; mas fora isso, as colunas em cada linha podem variar. As tabelas do Azure Table storage não têm conceito de chaves estrangeiras, relacionamentos, stored procedures, views ou outros objetos que você pode encontrar em um banco de dados relacional.
Os dados no Azure Table storage geralmente são desnormalizados, com cada linha contendo todos os dados de uma entidade lógica. Por exemplo, uma tabela que contém informações do cliente pode armazenar o nome, o sobrenome, um ou mais números de telefone e um ou mais endereços para cada cliente. O número de campos em cada linha pode ser diferente, dependendo da quantidade de números de telefone e endereços para cada cliente e dos detalhes registrados para cada endereço.
Para ajudar a garantir o acesso rápido, o Azure Table storage divide uma tabela em partições. O particionamento é um mecanismo para agrupar linhas relacionadas, com base em uma propriedade comum ou chave de partição. O particionamento não apenas ajuda a organizar os dados, mas também pode melhorar a escalabilidade e o desempenho das seguintes maneiras:
- As partições são independentes umas das outras e podem aumentar ou diminuir à medida que as linhas são adicionadas a uma partição ou removidas delas. Uma tabela pode conter qualquer número de partições.
- Ao pesquisar dados, você pode incluir a chave de partição nos critérios de pesquisa. Isso ajuda a diminuir o volume de dados a serem examinados e melhora o desempenho reduzindo a quantidade de E/S (operações de entrada e saída ou leituras e gravações) necessária para localizar os dados.
A chave em uma tabela do Azure Table storage compreende dois elementos: a chave de partição, que identifica a partição contendo a linha; e uma row key exclusiva para cada linha na mesma partição. Os itens na mesma partição são armazenados em ordem de row key. Se um aplicativo adicionar uma nova linha a uma tabela, o Azure verificará se a linha foi colocada na posição correta na tabela. Esse esquema permite que um aplicativo execute rapidamente point queries que identifiquem uma linha e range queries que busquem um bloco contíguo de linhas em uma partição.
O Azure Table storage dá suporte apenas a réplicas de leituras de várias regiões. Você pode configurar réplicas de leitura no Azure Table storage configurando a conta de armazenamento para usar a redundância de armazenamento com redundância geográfica de acesso de leitura (RA-GRS). Isso habilita uma réplica legível em uma região secundária. No entanto, você não pode gravar dados na região secundária.
O Azure Cosmos DB é um sistema de banco de dados não relacional (NoSQL) de escala global que dá suporte a várias APIs, permitindo que você armazene e gerencie dados como documentos JSON, pares chave-valor, famílias de colunas e grafos com baixa latência para escrita e leitura.
O Azure Cosmos DB dá suporte a várias APIs que permitem aos desenvolvedores usar a semântica de programação de muitos tipos comuns de armazenamento de dados para trabalhar com os dados no Cosmos DB. A estrutura de dados interna é abstrata, permitindo que os desenvolvedores usem o Cosmos DB para armazenar e consultar dados usando APIs com as quais já estão familiarizados.
O Azure Cosmos DB dá suporte à desnormalização de dados, o que aumenta a necessidade de duplicação de dados, mas também reduz a complexidade do esquema e, portanto, as consultas necessárias para manipulá-lo.
O Cosmos DB usa índices e particionamento para fornecer desempenho rápido de leitura e gravação e pode ser dimensionado para grandes volumes de dados.
O Cosmos DB é um sistema de gerenciamento de banco de dados altamente escalonável. O Cosmos DB aloca automaticamente espaço em um contêiner para suas partições, e cada partição pode crescer até 10 GB em tamanho. Os índices são criados e mantidos automaticamente. Praticamente, não há nenhuma sobrecarga administrativa.
A Table API do Cosmos DB dá suporte a gravações em várias regiões e réplicas de leitura.
Uma Azure Cosmos Account está no topo da hierarquia de recursos. Você deve ter isso antes de criar uma instância de banco de dados do Azure Cosmos DB. Você pode então criar contêineres específicos de API, como tabelas, coleções ou grafos. Você cria itens, as entidades para as quais está armazenando dados, dentro de um contêiner. Os exemplos incluem documentos, nós, edges ou linhas.
- Azure Cosmos Account
- Database
- Container
- Item
- Container
- Database
O Cosmos DB é altamente adequado para os seguintes cenários:
-
IoT e telemática. Normalmente, esses sistemas ingerem grandes quantidades de dados em picos de atividade frequentes. O Cosmos DB pode aceitar e armazenar essas informações rapidamente. Os dados podem ser usados pelos serviços de análise, como o Azure Machine Learning, o Azure HDInsight e o Microsoft Power BI. Além disso, é possível processar os dados em tempo real usando o Azure Functions, disparado à medida que os dados chegam ao banco de dados.
-
Varejo e marketing. A Microsoft usa o Cosmos DB para as próprias plataformas de comércio eletrônico que são executadas como parte da Microsoft Store e do Xbox Live. Ele também é usado no setor de varejo para armazenar dados de catálogo e para fornecimento de eventos em pipelines de processamento de pedidos.
-
Jogos. Os jogos modernos executam o processamento gráfico em clientes móveis/console, mas dependem da nuvem para fornecer conteúdo personalizado, como estatísticas de jogos, integração em mídia social e tabelas com as melhores pontuações. Os jogos geralmente exigem latências de um milissegundo para leituras e gravações a fim de fornecer uma experiência envolvente no jogo. Um banco de dados de jogo deve ser rápido e ser capaz de lidar com grandes picos de taxas de solicitação durante novos lançamentos de jogos e atualizações de recursos.
-
Aplicativos Web e móveis. O Azure Cosmos DB é normalmente usado em aplicativos Web e móveis e é bastante adequado para modelagem de interações sociais, integração com serviços de terceiros e desenvolvimento de experiências personalizadas avançadas. Os SDKs do Cosmos DB podem ser usados para criar aplicativos iOS e Android avançados usando a estrutura popular do Xamarin.
O Azure Cosmos DB dá suporte a várias APIs, permitindo que os desenvolvedores migrem facilmente os dados de repositórios NoSQL usados com frequência e apliquem as próprias habilidades de programação existentes. Ao provisionar uma nova instância do Cosmos DB, você seleciona a API que deseja usar. A escolha da API depende de vários fatores, incluindo o tipo de dados a ser armazenado, a necessidade de oferecer suporte a aplicativos existentes e as habilidades de API dos desenvolvedores que trabalharão com o armazenamento de dados.
-
Core (SQL) API - A API nativa no Cosmos DB gerencia dados no formato de documento JSON e, apesar de ser uma solução de armazenamento de dados NoSQL, usa a sintaxe SQL para trabalhar com os dados. Isso inclui aplicativos com dados de chave/valor. Esse tipo de aplicativo também é suportado pela Table API, mas a API Core (SQL) é recomendada como a melhor solução, pois fornece indexação aprimorada e uma experiência de consulta mais rica. A Microsoft recomenda que qualquer novo projeto de dados criado do zero use a API Core (SQL).
-
MongoDB API - O MongoDB é um banco de dados de software livre conhecido no qual são armazenados no formato JSON binário (BSON). A API do Azure Cosmos DB para MongoDB permite que os desenvolvedores usem bibliotecas de cliente do MongoDB e código para trabalhar com os dados no Azure Cosmos DB. A MQL (linguagem de consulta do MongoDB) usa uma sintaxe compacta orientada a objeto na qual os desenvolvedores usam objetos para chamar métodos. Por exemplo, a seguinte consulta usa o método find para consultar a coleção products no objeto db:
db.products.find({id: 123})
# resultado
{
"id": 123,
"name": "Hammer",
"price": 2.99
}
- Table API - é usada para trabalhar com os dados em tabelas de chave-valor, semelhante ao Azure Table Storage. A Azure Cosmos DB Table API oferece maior escalabilidade e desempenho do que o Azure Table Storage. O Azure Table Storage dá suporte apenas a réplicas de leituras de várias regiões configurando a conta de armazenamento para usar a redundância geográfica de acesso de leitura (RA-GRS). No entanto, você não pode gravar dados na região secundária. Abaixo uma consulta ao endpoint da tabela Customer.
https://endpoint/Customers(PartitionKey='1',RowKey='124')-
Cassandra API - O API do Cassandra é compatível com o Apache Cassandra, que é um banco de dados de software livre que usa uma estrutura de armazenamento de famílias de colunas. As famílias de colunas são tabelas, semelhantes àquelas em um banco de dados relacional, com a exceção de que não é obrigatório que cada linha tenha as mesmas colunas. O Cassandra dá suporte a uma sintaxe baseada em SQL.
-
Gremlin API - A API do Gremlin é usada com os dados em uma estrutura de grafo, na qual as entidades são definidas como vértices que formam nós (nodes) no grafo conectado. Os nós são conectados por bordas (edges) que representam relações, desta forma:
- Os nodes representam instâncias de entidades de dados, como pessoas individuais. Os nós são análogos a linhas em uma tabela em um banco de dados relacional.
- As Edges representam os relacionamentos entre os nós; eles também são chamados de grafos ou relacionamentos. As Edges podem ser direcionadas ou não direcionadas, dependendo da estrutura do banco de dados individual.
- Propriedades representam atributos de dados em relação a um nó. As propriedades são análogas às colunas em uma tabela em um banco de dados relacional. No entanto, lembre-se de que os bancos de dados NoSQL permitem flexibilidade nos atributos armazenados em um nó. Por exemplo, um nó pode ter muitas instâncias de um único atributo ou pode estar ausente.
- As directions são uma propriedade de uma Edge. As Edges podem ser direcionadas ou não direcionadas. As Edges direcionadas armazenam duas informações relacionadas a cada um dos nós que conectam. Por exemplo, uma Edge direcionada pai/filho armazenaria qual nó pessoa representa o pai e qual o filho. As Edges não direcionadas unem os nós, onde a direção do relacionamento não importa; por exemplo, uma amizade entre duas pessoas.

A sintaxe do Gremlin inclui funções para operar em vértices e bordas, permitindo que você insira, atualize, exclua e consulte dados no grafo. Por exemplo, você pode usar o código a seguir para adicionar um novo funcionário chamado Alice que relata ao funcionário com a ID 1 (Suzana).
g.addV('employee').property('id', '3').property('firstName', 'Alice')
g.V('3').addE('reports to').to(g.V('1'))
# resultado
g.V().hasLabel('employee').order().by('id')
Ao criar um novo aplicativo que analisa informações detalhadas de relacionamento para dados não relacionais, você deve usar a API Gremlin. Este é um dos poucos casos em que a API Core (SQL) não é recomendada como a melhor solução.
As soluções de processamento de Big Data, são usadas com grandes volumes de dados em vários formatos, que são carregados em lote ou capturados em fluxos em tempo real e armazenados em um data lake a partir do qual mecanismos de processamento distribuído, como o Apache Spark, são usados para processá-lo.
A arquitetura de data warehousing em larga escala pode variar, assim como as tecnologias específicas usadas para implementá-la; mas, em geral, os seguintes elementos estão incluídos:

-
Ingestão e processamento de dados – os dados de várias fontes são carregados em um data lake ou um data warehouse. A operação de carregamento geralmente envolve um processo de ETL (extração, transformação e carregamento) ou ELT (extração, carregamento e transformação) no qual os dados são limpos, filtrados e reestruturados para análise. A estrutura de dados resultante é otimizada para consultas analíticas. O processamento de dados geralmente é executado por sistemas distribuídos que podem processar grandes volumes de dados em paralelo usando clusters de vários nós. A ingestão de dados inclui o processamento em lote de dados estáticos e o processamento em tempo real de dados de streaming.
-
Analytical data store – os armazenamentos de dados para análise em grande escala incluem data warehouses relacionais, data lakes baseados em sistema de arquivos e arquiteturas híbridas que combinam recursos de data warehouses e data lakes (data lakehouses ou lake databases).
-
Analytical data model - embora possamamos trabalhar com os dados diretamente no armazenamento de dados analíticos, é comum criar um ou mais modelos de dados que agregam previamente os dados para facilitar a produção de relatórios, dashboards e visualizações interativas. Geralmente, são descritos como cubos, nos quais valores de dados numéricos são agregados em uma ou mais dimensões. O modelo encapsula as relações entre valores de dados e entidades dimensionais para dar suporte à análise de "drill up/drill down".
-
Visualização de dados – os analistas de dados consomem dados de modelos analíticos e diretamente de repositórios analíticos para criar relatórios, dashboards e outras visualizações. Outros usuários podem executar relatórios e análise de dados por autoatendimento. As visualizações dos dados mostram tendências, comparações e KPIs para uma empresa ou outra organização e podem assumir a forma de relatórios impressos, grafos e gráficos em documentos ou apresentações de PowerPoint, dashboards baseados na Web.
No Azure, a ingestão de dados em larga escala é melhor implementada criando pipelines que orquestram processos de ETL. Você poderá criar e executar pipelines usando o Azure Data Factory ou poderá usar o mesmo mecanismo de pipeline no Azure Synapse Analytics se desejar gerenciar todos os componentes da sua solução de data warehousing em um workspace unificado.
Em ambos os casos, os pipelines consistem em uma ou mais atividades que operam nos dados. Um conjunto de dados de entrada fornece os dados de origem, e as atividades podem ser definidas como um fluxo de dados que manipula os dados de maneira incremental até que um conjunto de dados de saída seja produzido.
Os pipelines usam serviços vinculados para carregar e processar dados, permitindo que você use a tecnologia certa para cada etapa do fluxo de trabalho. Por exemplo, você pode usar um serviço vinculado do Azure Blob Storage para ingerir o conjunto de dados de entrada e, em seguida, usar serviços como o Azure SQL Database para executar um procedimento armazenado que pesquisa os valores de dados relacionados, antes de executar uma tarefa de processamento de dados no Azure Databricks ou no Azure HDInsight, ou aplicar lógica personalizada usando uma Azure Function. Por fim, você pode salvar o conjunto de dados de saída em um serviço vinculado, como o Azure Synapse Analytics. Os pipelines também podem incluir algumas atividades internas, que não exigem um serviço vinculado.
Há dois tipos comuns de armazenamento de dados analíticos.
-
Data warehouses - é um banco de dados relacional no qual os dados são armazenados em um esquema otimizado para análise de dados em vez de cargas de trabalho transacionais. Normalmente, os dados de um armazenamento transacional são transformados em um esquema no qual os valores numéricos são armazenados em tabelas de fatos centrais, que estão relacionadas a uma ou mais tabelas de dimensões que representam entidades pelas quais os dados podem ser agregados. Esse tipo de esquema de tabela de fatos e dimensões é chamado de esquema em estrela; embora geralmente seja estendido para um esquema floco de neve adicionando outras tabelas relacionadas às tabelas de dimensões para representar hierarquias dimensionais.
- Um data warehouse é uma ótima opção quando você tem dados transacionais que podem ser organizados em um esquema estruturado de tabelas e deseja usar o SQL para consultá-los.
-
Data lakes - Um data lake é um armazenamento de arquivos, geralmente em um sistema de arquivos distribuído para acesso a dados de alto desempenho. Tecnologias como Spark ou Hadoop geralmente são usadas para processar consultas nos arquivos armazenados e retornar dados para relatórios e análises. Esses sistemas geralmente aplicam uma abordagem de esquema no ato da leitura para definir esquemas tabulares em arquivos de dados semiestruturados no ponto em que os dados são lidos para análise, sem aplicar restrições quando eles são armazenados.
- Os data lakes são ótimos para dar suporte a uma combinação de dados estruturados, semiestruturados e até mesmo não estruturados que você deseja analisar sem a necessidade de imposição de esquema quando os dados são gravados no repositório.
- O Azure Data Lake Storage é usado para armazenar dados brutos e não estruturados, como arquivos de texto, logs e imagens, para permitir que sejam processados rapidamente em um estágio posterior.
-
Abordagens híbridas - Você pode usar uma abordagem híbrida que combina recursos de data lakes e data warehouses em um banco de dados de lake ou data lakehouse. Os dados brutos são armazenados como arquivos em um data lake e uma camada de armazenamento relacional abstrai os arquivos subjacentes e os expõe como tabelas, que podem ser consultadas usando SQL. Os pools de SQL no Azure Synapse Analytics incluem o PolyBase, que permite que você defina tabelas externas com base em arquivos em um datalake (e outras fontes) e consulte-os usando SQL. O Synapse Analytics também dá suporte a uma abordagem de banco de dados de lake na qual você pode usar modelos de banco de dados para definir o esquema relacional do seu data warehouse, enquanto armazena os dados subjacentes no armazenamento do data lake - separando o armazenamento e a computação para sua solução de data warehousing. Os data lakehouses são uma abordagem relativamente nova em sistemas baseados em Spark e são habilitados por meio de tecnologias como o Delta Lake; que adiciona recursos de armazenamento relacional ao Spark, para que você possa definir tabelas que impõem esquemas e consistência transacional, dão suporte a fontes de dados carregadas em lote e streaming e fornecem uma API de SQL para consulta.
Describe Azure services for data warehousing, including Azure Synapse Analytics, Azure Databricks, Azure HDInsight, and Azure Data Factory
-
Azure Synapse Analytics - é uma solução unificada e de ponta a ponta para análise de dados em grande escala. Ele reúne várias tecnologias e funcionalidades, permitindo que você combine a integridade e a confiabilidade de dados de um data warehouse relacional escalonável e de alto desempenho baseado no SQL Server com a flexibilidade de um data lake e de um Apache Spark de código aberto.
- Inclui suporte nativo para análise de log e telemetria com pools do Azure Synapse Data Explorer
- Pipelines de dados integrados para ingestão e transformação de dados.
- Azure Synapse Studio - interface única e interativa para gerenciamento de todos os Azure Synapse Analytics, capacidade de criar notebooks interativos nos quais o código Spark e o conteúdo de markdown podem ser combinados.
- É usado para modelar e fornecer dados. Você pode carregar dados relacionais ingeridos do Azure Data Factory usando o pool Synapse SQL e também pode ler dados não estruturados armazenados no Azure Data Lake Storage usando o Polybase.
-
Azure Databricks - é uma solução abrangente de análise de dados criada com base no Apache Spark e que oferece funcionalidades nativas de SQL, bem como clusters Spark otimizados para carga de trabalho para análise de dados e ciência de dados.
- fornece uma interface interativa do usuário por meio da qual o sistema pode ser gerenciado e os dados podem ser explorados em notebooks interativos e data visualizations.
- Devido ao seu uso comum em várias plataformas de nuvem, talvez você queira considerar o uso dele como seu repositório analítico ou se precisar operar em um ambiente de várias nuvens ou dar suporte a uma solução portátil em nuvem.
- Azure Databricks pode lidar com processamento batch e stream. Você também pode executar processamento de dados em tempo real e streaming de eventos do Azure Event Hub.
-
Azure HDInsight - é um serviço do Azure que dá suporte a vários tipos de cluster de análise de dados de código aberto. Embora não seja tão amigável quanto o Azure Synapse Analytics e o Azure Databricks, ele poderá ser uma opção adequada se sua solução de análise se basear em várias estruturas de código-fonte aberto ou se você precisar migrar uma solução local existente baseada em Hadoop para a nuvem.
-
Azure Data Factory - é um serviço do Azure que permite definir e agendar pipelines de dados para transferir e transformar dados. Você pode integrar seus pipelines a outros serviços do Azure. A ingestão de dados é o processo de combinar seus dados estruturados, semiestruturados e não estruturados em um armazenamento de dados comum. O Azure Data Factory foi projetado especificamente para fornecer suporte de ponta a ponta para operações de extraction-transform-load (ETL) para carregamento de dados do data warehouse. Frequentemente, mover dados para um data warehouse requer limpeza e transformação mais agressivas do que as suportadas pelo Data Factory.
Cada um desses serviços pode ser pensado como um armazenamento de dados analíticos, no sentido de que eles fornecem um esquema e uma interface por meio dos quais os dados podem ser consultados. No entanto, em muitos casos, os dados são armazenados em um data lake e o serviço é usado para processar os dados e executar consultas. Algumas soluções podem até combinar o uso desses serviços.
Grande parte desses dados pode ser processada em tempo real (ou pelo menos quase em tempo real) como um fluxo perpétuo de dados, permitindo a criação de sistemas que revelam insights e tendências instantâneas, ou toma ações imediatas de resposta aos eventos à medida que eles ocorrem.
O processamento de dados é simplesmente a conversão de dados brutos em informações relevantes por meio de um processo. Há duas maneiras gerais de processar dados:
No processamento em lotes, os elementos de dados que chegam recentemente são coletados e armazenados e o grupo inteiro é processado juntos como um lote.
Há várias maneiras de determinar o momento exato em que cada grupo é processado. Por exemplo, você pode processar dados com base em um intervalo de tempo agendado (por exemplo, a cada hora), ou o processamento pode ser disparado quando determinada quantidade de dados tiver chegado ou ainda como resultado de algum outro evento.
As vantagens do processamento em lotes incluem:
- Grandes volumes de dados podem ser processados em um momento conveniente.
- Ele pode ser agendado para execução em momentos em que os computadores ou os sistemas estão ociosos, como durante a noite ou fora do horário de pico.
As desvantagens do processamento em lotes incluem:
- O intervalo de tempo existente entre a ingestão dos dados e a obtenção dos resultados.
- Todos os dados de entrada de um trabalho em lotes devem estar prontos para que o lote seja processado. Isso significa que os dados devem ser cuidadosamente verificados. Eventuais problemas com erros, dados e falhas do programa durante os jobs em lotes levam todo o processo a uma parada. Os dados de entrada devem ser cuidadosamente verificados para que o job possa ser executado novamente. Mesmo pequenos erros de dados podem impedir a execução de um trabalho em lotes.
No processamento de streaming, cada parte dos dados é processada ao chegar. Ao contrário do processamento em lotes, não há espera até o próximo intervalo de processamento de lotes — os dados são processados como unidades individuais em tempo real, em vez de serem processados um lote por vez. O processamento de dados de streaming é benéfico nos cenários em que dados dinâmicos são gerados de maneira contínua.
Exemplos do mundo real de dados de streaming incluem:
- Uma instituição financeira controla as alterações do mercado de ações em tempo real, computa o valor em risco e reequilibra automaticamente os portfólios com base nos movimentos de preço das ações.
- Uma empresa de jogos online coleta dados em tempo real sobre as interações do jogador com os jogos e alimenta os dados na plataforma de jogos. Então, a empresa analisa os dados em tempo real e oferece incentivos e experiências dinâmicas para envolver os jogadores.
- Um site de imóveis que acompanha um subconjunto de dados dos dispositivos móveis e faz recomendações em tempo real sobre propriedades a serem visitadas com base na localização geográfica do consumidor.
Diferenças entre dados de lote e dados de streaming:
- Escopo de dados: o processamento em lotes pode processar todos os dados no conjunto de dados. O processamento de streaming normalmente só tem acesso aos dados mais recentes recebidos ou aos dados que estão dentro de uma janela de tempo contínua (os últimos 30 segundos, por exemplo).
- Tamanho dos dados: o processamento em lotes é adequado para lidar de maneira eficiente com grandes conjuntos de dados. O processamento de streaming destina-se a registros individuais ou micro lotes, formados por poucos registros.
- Desempenho: a latência é o tempo necessário para que os dados sejam recebidos e processados. A latência do processamento em lotes normalmente é de algumas horas. O processamento de streaming normalmente ocorre imediatamente, com latência na ordem de segundos ou milissegundos.
- Análise: normalmente você usa o processamento em lotes para executar análises complexas. O processamento de streaming é usado para funções de resposta simples, agregações ou cálculos como médias móveis.
Muitas soluções de análise em larga escala incluem uma combinação de processamento em lotes e de stream, permitindo a análise de dados históricos e em tempo real. É comum para soluções de processamento de fluxo capturar dados em tempo real, processá-los filtrando ou agregando-os, e apresentá-los por meio de painéis e visualizações em tempo real, enquanto também persiste os resultados processados em um armazenamento de dados para análise histórica junto com os dados processados em lote.
Describe technologies for real-time analytics including Azure Stream Analytics, Azure Synapse Data Explorer, and Spark structured streaming
Análise em tempo real no Azure:
-
Azure Stream Analytics: uma solução de plataforma como serviço (PaaS) que você pode usar para definir trabalhos de streaming que ingerem dados de uma fonte de streaming, aplicam uma consulta perpétua e gravam os resultados em uma saída.
-
Spark Structured Streaming: uma biblioteca de código aberto que permite desenvolver soluções de streaming complexas em serviços baseados no Apache Spark, incluindo o Azure Synapse Analytics, o Azure Databricks e o Azure HDInsight.
-
Azure Data Explorer: um serviço de análise e banco de dados de alto desempenho otimizado para ingestão e consulta de dados em lote ou streaming com um elemento de série temporal e que pode ser usado como um serviço autônomo do Azure ou como um tempo de execução do Azure Synapse Data Explorer em um espaço de trabalho do Azure Synapse Analytics.
Fontes para processamento de stream:
-
Azure Event Hubs: um serviço de ingestão de dados que você pode usar para gerenciar filas de dados de eventos, garantindo que cada evento seja processado em ordem, exatamente uma vez.
-
Azure IoT Hub: um serviço de ingestão de dados semelhante aos Hubs de Eventos do Azure, mas otimizado para gerenciar dados de eventos de dispositivos da Internet das Coisas (IoT).
-
Azure Data Lake Store Gen 2: um serviço de armazenamento altamente escalonável que é frequentemente usado em cenários de processamento em lotes, mas que também pode ser usado como fonte de dados de streaming.
-
Apache Kafka: uma solução de ingestão de dados de código aberto que é comumente usada em conjunto com o Apache Spark. Você pode usar o Azure HDInsight para criar um cluster Kafka.
Coletores (sinks) para processamento de fluxo:
A saída do processamento de fluxo geralmente é enviada para os seguintes serviços:
-
Azure Event Hubs: usados para enfileirar os dados processados para processamento posterior.
-
Azure Data Lake Store Gen 2 ou Azure blob storage: usados para manter os resultados processados como um arquivo.
-
Azure SQL Database ou Azure Synapse Analytics, ou Azure Databricks: usados para manter os resultados processados em uma tabela de banco de dados para consulta e análise.
-
Microsoft Power BI: usado para gerar visualizações de dados em tempo real em relatórios e painéis.
O Azure Stream Analytics é um serviço para processamento de eventos complexos e análise de dados de streaming. O Stream Analytics é usado para:
- Ingerir dados de uma entrada, como um Azure event hub, Azure IoT Hub ou contêiner de Azure Storage blob.
- Processar os dados usando uma consulta para selecionar, projetar e agregar valores de dados.
- Gravar os resultados em uma saída, como Azure Data Lake Gen 2, Azure SQL Database, Azure Synapse Analytics, Azure Functions, Azure event hub, Microsoft Power BI ou outros.
Uma vez iniciada, uma consulta do Stream Analytics será executada perpetuamente, processando novos dados à medida que chegam na entrada e armazenando os resultados na saída.
O Azure Stream Analytics é uma ótima opção para quem precisa capturar dados continuamente de uma fonte de streaming, filtrá-los ou agregá-los e enviar os resultados para um armazenamento de dados ou processo downstream para análise e geração de relatórios.
A maneira mais fácil de usar o Azure Stream Analytics é criar um job do Stream Analytics em uma assinatura do Azure, configurar suas entradas e saídas e definir a consulta que o job usará para processar os dados. A consulta é expressa usando SQL e pode incorporar dados de referência estática de várias fontes para fornecer valores de pesquisa que podem ser combinados com os dados de streaming ingeridos de uma entrada.
Se os requisitos do processo de fluxo forem complexos ou consumirem muitos recursos, você poderá criar um cluster do Stream Analysis, que usa o mesmo mecanismo de processamento subjacente de um job do Stream Analytics, mas em um locatário dedicado (para que seu processamento não seja afetado por outros clientes) e com escalabilidade configurável que permite definir o equilíbrio certo de taxa de transferência (throughput) e custo para seu cenário específico.
Apache Spark é uma estrutura de processamento distribuído para análise de dados em larga escala. Você pode usar o Spark no Microsoft Azure nos seguintes serviços:
- Azure Synapse Analytics
- Azure Databricks
- Azure HDInsight
O Spark pode ser usado para executar código (geralmente escrito em Python, Scala ou Java) em paralelo em vários nós de cluster, permitindo que ele processe volumes muito grandes de dados com eficiência. O Spark pode ser usado para processamento em lotes e de fluxo.
Para processar dados de streaming no Spark, você pode usar a biblioteca Spark Structured Streaming, que fornece uma API para ingestão, processamento e saída de resultados de fluxos perpétuos de dados.
Spark Structured Streaming é criado em uma estrutura no Spark chamada dataframe, que encapsula uma tabela de dados. Você usa a API do Spark Structured Streaming para ler dados de uma fonte de dados em tempo real, como um hub Kafka, um armazenamento de arquivos ou uma porta de rede, em um dataframe "sem limites" que é continuamente preenchido com novos dados do fluxo. Você define uma consulta no dataframe que seleciona, projeta ou agrega os dados - geralmente em janelas temporais. Os resultados da consulta geram outro dataframe, que pode ser persistido para análise ou processamento adicional.
O Spark Structured Streaming é uma ótima opção para análise em tempo real quando você precisa incorporar dados de streaming em um repositório de dados analíticos ou data lake baseado no Spark.
Delta Lake é uma camada de armazenamento de código aberto que adiciona suporte para consistência transacional, aplicação de esquema e outros recursos comuns de data warehouse ao armazenamento de data lake.
Ele também unifica o armazenamento para dados em lote e streaming e pode ser usado no Spark para definir tabelas relacionais para processamento em lotes e em stream. Quando usada para processamento de fluxo, uma tabela Delta Lake pode ser usada como fonte de streaming para consultas em dados em tempo real ou como um coletor no qual um fluxo de dados é gravado.
Os tempos de execução do Spark no Azure Synapse Analytics e Azure Databricks incluem suporte para Delta Lake.
O Delta Lake combinado com o Spark Structured Streaming é uma boa solução quando você precisa abstrair processos batch e stream em um data lake por um esquema relacional para análise e consulta baseada em SQL.
O Azure Data Explorer é um serviço autônomo do Azure de análise de dados com eficiência. Você pode usar o serviço como saída para analisar grandes volumes de diversas fontes de dados, como sites, aplicativos, dispositivos IoT e muito mais.
Por exemplo, ao gerar logs do Azure Stream Analytics para o Azure Data Explorer, você pode complementar o tratamento de alertas de baixa latência do Stream Analytics com os recursos de investigação profunda do Data Explorer.
O serviço também é encapsulado como um runtime no Azure Synapse Analytics, onde é referido como Azure Synapse Data Explorer, permitindo que você crie e gerencie soluções analíticas que combinam análises do SQL, do Spark e do Data Explorer em um único workspace.
Os dados são ingeridos no Data Explorer por meio de conectores ou escrevendo uma quantidade mínima de código. Isso permite que haja a ingestão rápida de dados de uma ampla variedade de fontes de dados, incluindo fontes estáticas e de streaming.
O Data Explorer oferece suporte a lotes e streaming quase em tempo real para otimizar a ingestão de dados. Os dados ingeridos são armazenados em tabelas em um banco de dados do Data Explorer, onde a indexação automática permite consultas de alto desempenho.
O Azure Data Explorer é uma ótima opção de tecnologia quando você precisa:
- Colete e analise dados em tempo real ou em lote que incluam um elemento de série temporal, como telemetria de log ou valores emitidos por dispositivos IoT (Internet das Coisas).
- Explore, filtre e agregue dados rapidamente usando avançada e intuitiva KQL (Linguagem de Consulta Kusto).
Uma linguagem especificamente otimizada para desempenho de leitura rápida – principalmente com dados de telemetria que incluem atributos de timestamp.
A consulta a seguir retorna as colunas StartTime, EventType e Message da tabela LogEvents de erros registrados após 31 de dezembro de 2021.
LogEvents
| where StartTime > datetime(2021-12-31)
| where EventType == 'Error'
| project StartTime, EventType , MessageA modelagem e a visualização de dados são aspectos centrais das cargas de trabalho de BI (business intelligence) com suporte de soluções de análise de dados de grande escala. Basicamente, a visualização de dados capacita relatórios e tomada de decisões que ajudam a garantir o sucesso das organizações.
O Microsoft Power BI é um conjunto de ferramentas e serviços que os analistas de dados podem usar para criar visualizações de dados interativas para os usuários empresariais consumirem.
-
Power BI Desktop, um aplicativo no qual você pode importar dados de uma ampla variedade de fontes de dados, combinar e organizar os dados dessas fontes em um modelo de dados de análise e criar relatórios contendo visualizações interativas dos dados.
-
Power BI service - um serviço de nuvem no qual os relatórios podem ser publicados e usados por usuários empresariais.
- Você também pode fazer modelagem de dados e edição de relatório de nível básico diretamente no serviço usando um navegador da Web, mas limitado em comparação com a ferramenta Power BI Desktop.
- Você pode usar o serviço para agendar atualizações das fontes de dados nas quais os relatórios se baseiam e compartilhar relatórios com outros usuários.
- Você também pode definir dashboards e aplicativos que combinam relatórios relacionados em um workspace de fácil consumo.
- Você pode aplicar segurança baseada em função aos dados.
- O Power BI service é um SaaS que permite que os usuários compartilhem e colaborem em relatórios e painéis do Power BI.
- Os dashboards são compostos por Tiles, que podem ser criados fixando visuais de relatórios e widgets do Power BI.
- Também permite que os administradores atribuam usuários a funções para um relatório específico. Essas funções são criadas pelo autor do relatório no Power BI Desktop durante a modelagem de dados, permitindo que você filtre dados nos visuais que usuários específicos podem acessar e interagir.
- Os dashboards podem ser criados no Power BI Service, o componente SaaS do Power BI.
- Os dashboards são uma única tela (single canvas). Eles têm apenas uma página, ao contrário dos relatórios do Power BI, que podem ter várias páginas.
Os usuários podem consumir relatórios, dashboards e aplicativos no serviço do Power BI por meio de um navegador da Web ou em dispositivos móveis usando o aplicativo Power BI para telefone.
Os modelos analíticos permitem estruturar dados para dar suporte à análise. Os modelos são baseados em tabelas de dados relacionadas e definem os valores numéricos que você deseja analisar ou relatar (medidas ou measures) e as entidades que serão usadas para fazer a agregação (dimensões ou dimensions).
Por exemplo, um modelo pode incluir uma tabela contendo medidas numéricas para vendas (como receita ou quantidade) e dimensões para produtos, clientes e tempo. Isso permite agregar medidas de venda em uma ou mais dimensões (por exemplo, para identificar a receita total por cliente ou o total de itens vendidos por produto, por mês).
Conceitualmente, o modelo forma uma estrutura multidimensional, que normalmente é conhecida como cubo, no qual qualquer ponto em que as dimensões se cruzam representa uma medida agregada para essas dimensões.
As tabelas de dimensões representam as entidades pelas quais as medidas numéricas são agregadas. Por exemplo, produto ou cliente.
Cada entidade é representada por uma linha com um valor de chave exclusivo. As colunas restantes representam atributos de uma entidade. É comum que os modelos analíticos incluam uma dimensão de tempo para agregar medidas numéricas associadas a eventos ao longo do tempo.
As medidas numéricas que serão agregadas pelas várias dimensões no modelo são armazenadas em tabelas de fatos. Cada linha em uma tabela de fatos representa um evento gravado com medidas numéricas associadas. Por exemplo, a tabela Vendas no esquema abaixo representa as transações de vendas de itens individuais e inclui valores numéricos para quantidade vendida e receita.

Esse tipo de esquema, em que uma tabela de fatos está relacionada a uma ou mais tabelas de dimensões, é chamado de esquema em estrela.
Você também pode definir um esquema mais complexo, no qual as tabelas de dimensões estão relacionadas a tabelas adicionais que contêm mais detalhes e é chamado de esquema floco de neve.
Mais uma coisa que vale a pena considerar sobre os modelos analíticos é a criação de hierarquias de atributo que permitem fazer drill up ou drill down rapidamente para encontrar valores agregados em diferentes níveis em uma dimensão hierárquica.
O modelo pode ser criado com valores pré-agregados para cada nível de uma hierarquia, o que permite alterar rapidamente o escopo da análise, por exemplo, exibindo o total de vendas por ano e depois fazendo drill down para ver um detalhamento maior do total de vendas por mês.

Você pode usar o Power BI para definir um modelo analítico usando tabelas de dados, que podem ser importadas de uma ou mais fontes de dados. Depois, você pode usar a interface de modelagem de dados na guia Modelo do Power BI Desktop para definir o modelo analítico criando relações entre tabelas de fatos e de dimensões, definindo hierarquias, configurando tipos de dados e formatos de exibição para campos nas tabelas e gerenciando outras propriedades dos dados que ajudam a definir um modelo rico para análise.
Power Query Editor - é uma ferramenta do Power BI Desktop que permite interagir com os dados aplicando uma série de transformações que são registradas para você como etapas, que podem ser desfeitas, se necessário.
Report View - Esta é a tela onde você pode arrastar seus visuais para criar seu relatório usando dados que você já importou, transformou e modelou.

Depois de criar um modelo, é possível usá-lo para gerar visualizações de dados que podem ser incluídas em um relatório.
Há muitos tipos de visualização de dados, alguns comumente usados e outros mais especializados. O Power BI inclui um extenso conjunto de visualizações internas, que podem ser estendidas com visualizações personalizadas e de terceiros.
Tabelas e texto geralmente são a maneira mais simples de comunicar dados. As tabelas são úteis quando vários valores relacionados devem ser exibidos, e valores de texto individuais em cartões podem ser uma maneira útil de mostrar números ou métricas importantes.
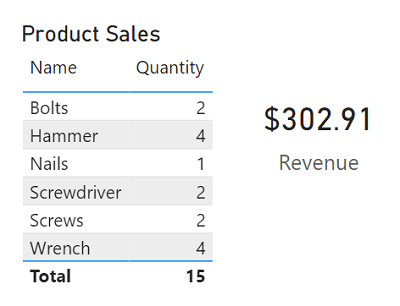
Os gráficos de barras e colunas são uma boa maneira de comparar visualmente valores numéricos para categorias discretas.
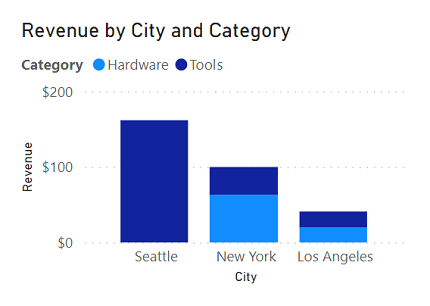
Os gráficos de linhas também podem ser usados para comparar valores categorizados e são úteis quando você precisa examinar tendências, geralmente ao longo do tempo.
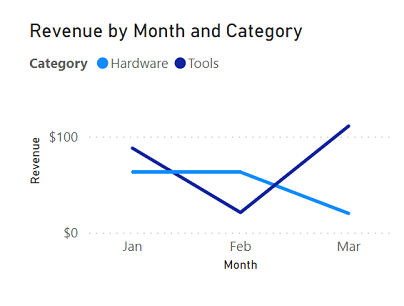
Os gráficos de pizza geralmente são usados em relatórios de negócios para comparar visualmente valores categorizados como proporções de um total.
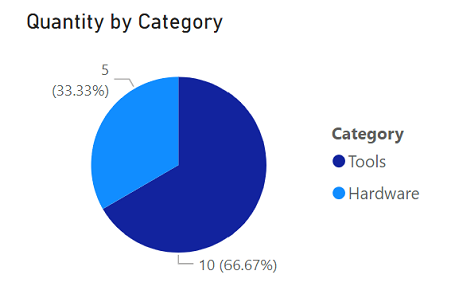
Os gráficos de dispersão são úteis quando você deseja comparar duas medidas numéricas e identificar uma relação ou correlação entre elas.
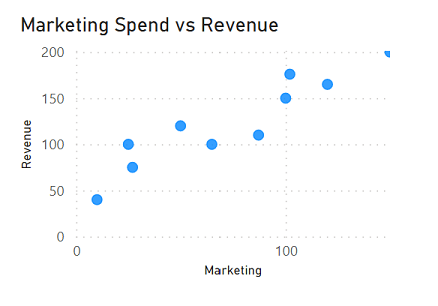
Os mapas são uma ótima maneira de comparar visualmente valores para diferentes áreas geográficas ou locais.
No Power BI, os elementos visuais para dados relacionados em um relatório são vinculados automaticamente uns aos outros e fornecem interatividade. Por exemplo, selecionar uma categoria individual em uma visualização filtrará e destacará automaticamente essa categoria em outras visualizações relacionadas no relatório.
O visual de perguntas e respostas oferece aos usuários uma caixa de perguntas (entrada de texto) que eles podem usar para fazer perguntas em linguagem natural, bem como uma lista pré-preenchida de perguntas sugeridas e receber respostas visuais.