![]()
-
应用简介:基于DOCA的自适应路由
- 利用NVIDIA BlueField-2 DPU卸载基于主动探测的自适应路由算法,实现VXLAN等Overlay流量的逐流负载均衡;
- DOCA-AR实现了基于全局拥塞感知的负载均衡,通过在端侧发送探测报文获取拥塞状态并帮助流量避开拥塞点从而改善尾时延;
- DOCA-AR部署在DPU,既拥有主机方案易感知全局状态的特点,也拥有交换机方案不修改主机协议栈的优势。
-
性能表现:如下是我们测试的多路径环境拓扑图和尾时延测试结果
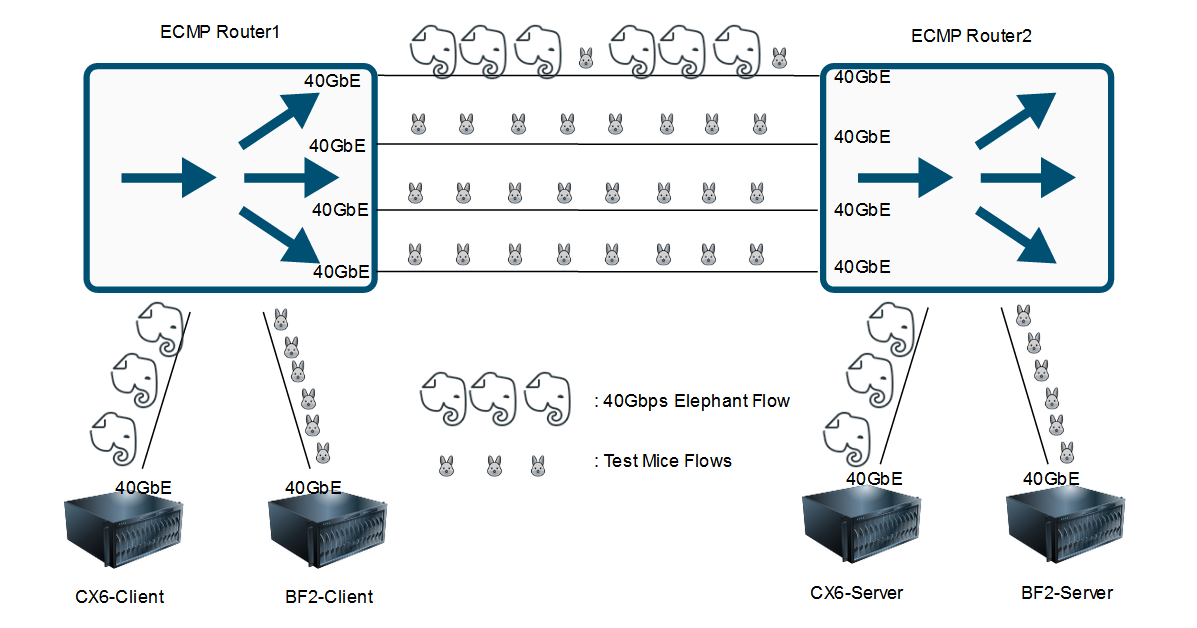
- 第一张表,测试了10条5MB大小的流的最大完成时间(MaxFCT:尾时延);
- 第二张表,测试了50条5MB大小的流的最大完成时间(MaxFCT:尾时延);
- “With an 40Gbps Elephant Flow”代表引入一条40Gbps的大象流致使一条路径产生拥塞;
- 可以看出相对于ECMP,DOCA-AR能够很好的避开拥塞点,改善尾时延,详细测试说明可参看后续内容;

| FlowNum | MessageSize | Test Times | ||
|---|---|---|---|---|
| 10 | 5MB | 30 times | ||
| Network Load | Load Balancing Scheme | MaxFCT-Min[ms] | MaxFCT-Max[ms] | MaxFCT-Avg[ms] |
| With an 40Gbps Elephant Flow | DOCA-AR | 22.74 | 231.29 | 34.21 |
| ECMP | 27.41 | 1709.99 | 920.81 | |
| No Elephant Flow | DOCA-AR | 23.54 | 34.49 | 27.32 |
| ECMP | 20.42 | 35.1 | 26.97 | |
| FlowNum | MessageSize | Test Times | ||
|---|---|---|---|---|
| 50 | 5MB | 30 times | ||
| Network Load | Load Balancing Scheme | MaxFCT-Min[ms] | MaxFCT-Max[ms] | MaxFCT-Avg[ms] |
| With an 40Gbps Elephant Flow | DOCA-AR | 103.45 | 1535.76 | 334.52 |
| ECMP | 1127.96 | 2235.71 | 1857.05 | |
| No Elephant Flow | DOCA-AR | 98.35 | 292.31 | 221.72 |
| ECMP | 100.83 | 289.77 | 236.18 | |
- 使用背景:
- 云计算和AI等技术的蓬勃发展,数据中心东西向流量逐渐增多,带宽跃升至100Gbps甚至400Gbps;
- 数据中心网络通常是Spine-Leaf等包含冗余链路的多路径架构,服务器之间的流量通常会被路由到不同路径来实现网络负载均衡,从而提高链路利用率、提升吞吐并改善流量的传输完成时间(FCT);
- 数据中心的并发场景下,通常大家会更关注长尾时延(类似木桶效应,最坏的情况决定整体表现),网络负载越均衡尾时延通常也会越小;
- DCN(数据中心网络)负载均衡一直是热议话题,几乎每年的网络顶会都会出现相关文章,我们将它们划分成了不同类型:
- 按照是否感知拥塞状态分类:
- 感知拥塞,例如CONGA,能避开拥塞点但开销大;
- 不感知拥塞,例如ECMP,开销小但不能避开拥塞点;
- 按照调度粒度分类:
- 逐流,例如ECMP,PLB,开销最小但是粒度大;
- 逐flowlet,例如CONGA;
- 逐包,例如NVIDIA Spectrum自带的Adaptive Routing(For RDMA),乱序导致开销大但是粒度细;
- 按照实现位置分类:
- 基于交换机,例如NVIDIA Spectrum自带的Adaptive Routing,不易感知全局拥塞状态、实现比端侧难但不需要端侧修改协议栈;
- 基于Host,例如CLOVE,容易感知全局拥塞状态但通常需要修改主机协议栈;
- 基于控制器,例如Fastpass;
- 按照是否感知拥塞状态分类:
- 目前数据中心比较常用的网络层负载均衡机制是ECMP,它采用逐流、无状态的调度,不感知本地的拥塞状态也不感知全局的拥塞状态;
- 应用价值:
- 探索了基于DPU的新型负载均衡方案的可行性和有效性,并提供了有效的源代码和测试数据作为支持;
- 相对于ECMP,极大得改善了长尾时延问题,部署实现简单、不需要修改协议栈且节省调度带来的主机CPU开销。
-
APP架构
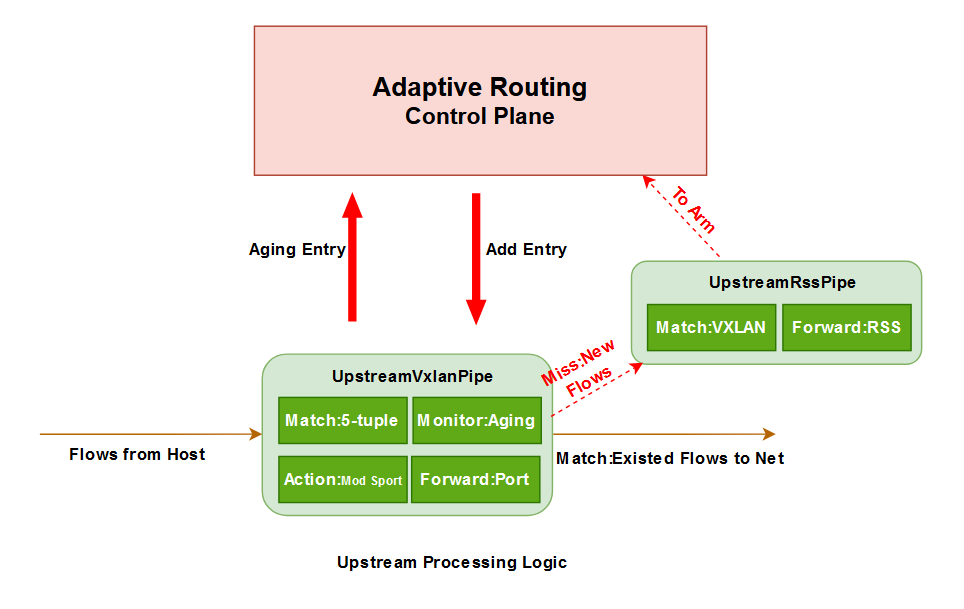
- 上行流量处理:
- 转发vxlan-pipe中存在的流量至网络;
- 转发新流量至控制平面并调用AR算法;
- 为新流量生成Pipe表项并下发;
- 处理老化连接;
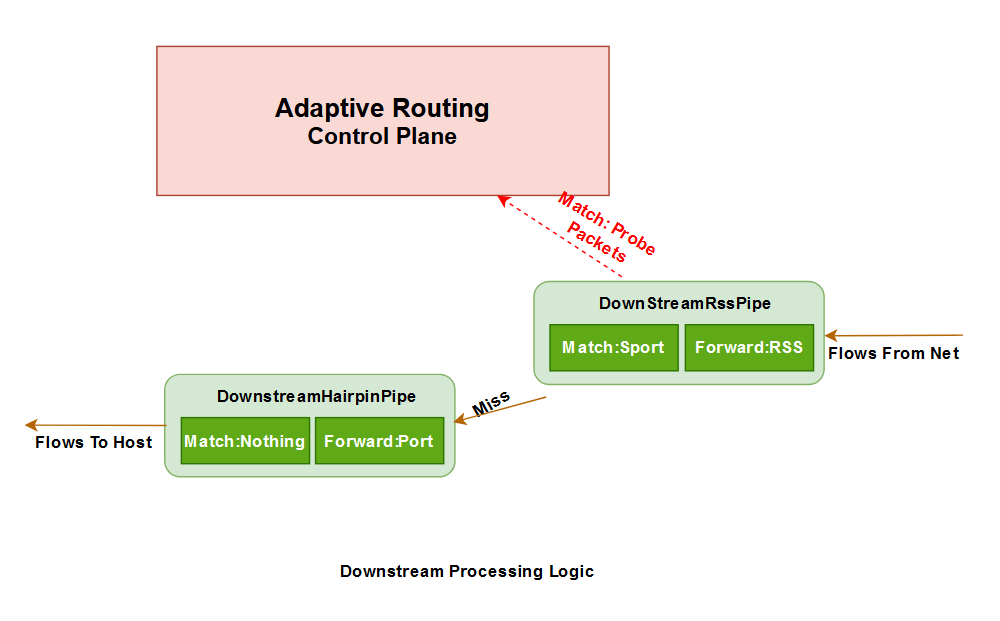
- 下行流量处理:
- 转发回传探测包进入控制平面;
- 转发其余流量至主机;
- 上行流量处理:
-
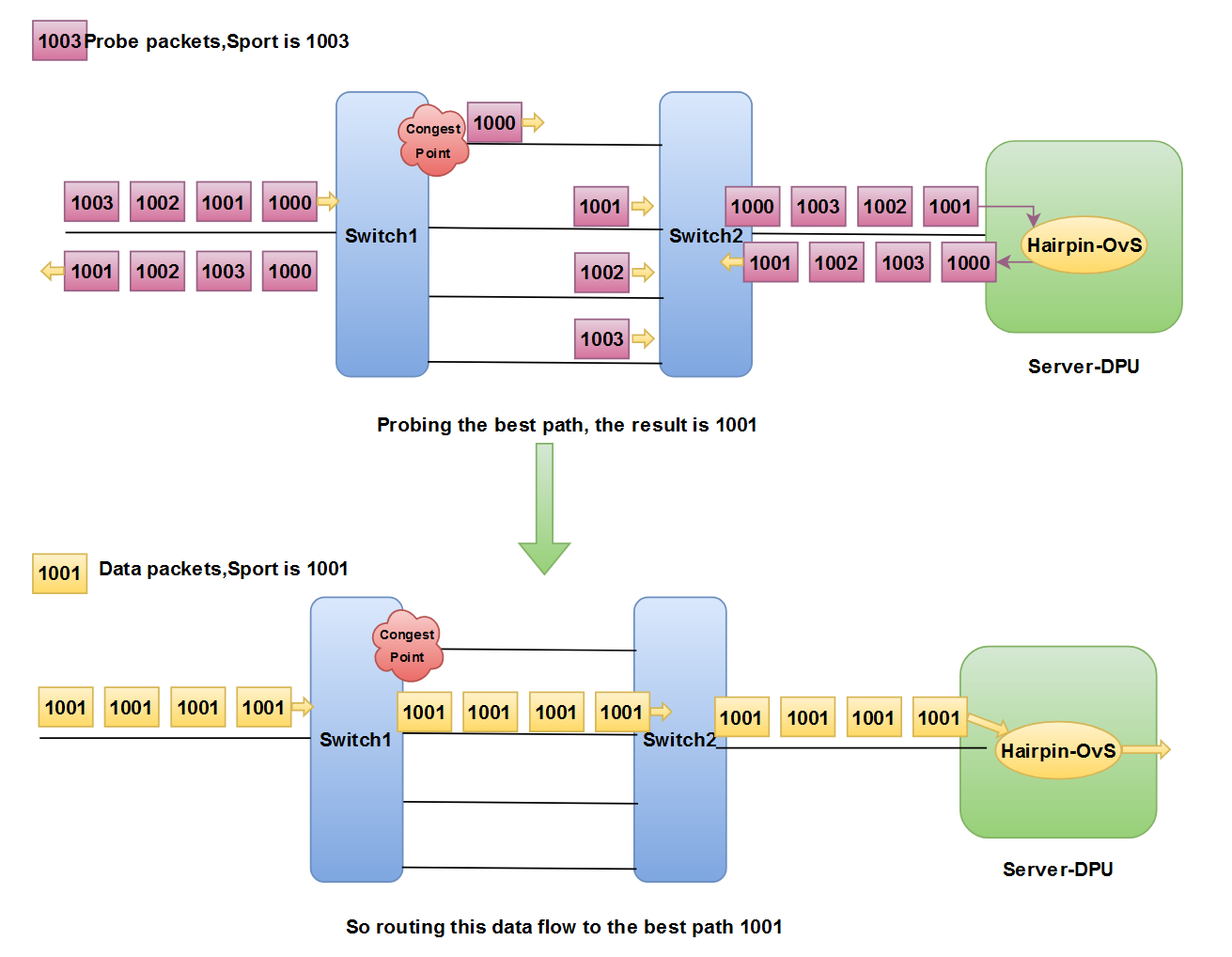
AR算法:
- 控制平面接收到新流量,并提取对应的5元组信息;
- 发送4个探测报文,包头和新流量一致,除了源端口号逐包递增,第一个探测包的源端口号与新流量一致;
- 对端DPU通过Hairpin队列将探测包传回;
- 接收回传探测包获取当前最佳路径,将新流量路由到这条路径上;
- 主体**就是Min-RTT,拥塞会导致路径时延增加,我们选取时延最低路径来避开拥塞。



-
程序编译
- 环境要求
- Client: DPU with DOCA 1.5
- Server: DPU with any version DOCA (CX6应该也可以,做好探测包回传即可)
- Client DPU编译动作:
#下载此仓库源码到Client DPU Arm中
meson build
ninja -C build
- 环境要求
-
接收端配置:
- 在Arm中,下发DPU-OvS 流表,分离探测包并用hairpin卸载回传动作, 我们是在二层环境做的实验,所以不交换IP,修改目的地址即可;
ovs-ofctl del-flows ovsbr1
ovs-ofctl add-flow ovsbr1 "priority=300,in_port=p0,udp,tp_dst=4789,nw_tos=0x20 actions=mod_dl_dst:08:c0:eb:bf:ef:9a,mod_tp_dst:4788,output:IN_PORT"
ovs-ofctl add-flow ovsbr1 "priority=100,in_port=p0 actions=output:pf0hpf"
ovs-ofctl add-flow ovsbr1 "priority=100,in_port=pf0hpf actions=output:p0" - 在Host中,创建VTEP;
ip link add vxlan0 type vxlan id 42 dstport 4789 remote 192.168.200.2 local 192.168.200.1 dev enp1s0f0np0
ifconfig vxlan0 192.168.233.1
- 在Arm中,下发DPU-OvS 流表,分离探测包并用hairpin卸载回传动作, 我们是在二层环境做的实验,所以不交换IP,修改目的地址即可;
-
发送端配置
- 在Arm中,运行如下两个脚本,建立两个SF、修改OvS拓扑并下发OvS流表;
bash scripts/2SF-ON-P0-Build.sh
bash scripts/2SF-ON-P0-INIT.sh - 在Host中,创建VTEP;
ip link add vxlan0 type vxlan id 42 dstport 4789 remote 192.168.200.1 local 192.168.200.2 dev enp1s0f0np0
ifconfig vxlan0 192.168.233.2
- 在Arm中,运行如下两个脚本,建立两个SF、修改OvS拓扑并下发OvS流表;
-
运行程序
- 运行DOCA-AR:
bash doca_ar.sh - 运行ECMP最对比:
bash ecmp.sh - 进入程序控制台后,输入
quit退出,输入conntrack打印当前活跃连接;
- 运行DOCA-AR:
- 测试物理拓扑:和上述多路径环境一致;
- 设备型号:
- DPU: NVIDIA BF2 100GbE
- CX6: NVIDIA CX6 100GbE
- Router: Intel Barefoot P4 Switch 100GbE
- 测试软件:
- 在BF2设备上,使用的是iPerf发送的TCP流量,并运行在Overlay网络上;
- 在CX6设备上,使用的是DPDK-Pktgen产生的一条无状态UDP流,包大小为MTU,无拥塞控制;
- VTEP放在了Host上,没有卸载VTEP至Arm;
- 只根据隧道头部做连接跟踪,不识别隧道内头部,连接较少时,基本一条Overlay连接对应一个不同的隧道五元组;
- 阻塞式的探测,在探测函数未超时或未接收到回传探测包时不发送新连接,容易导致CPS下降;
- AR算法过于粗暴简单。
- 演示视频已上传至百度网盘,点我可前往查看实验过程;
- 点我可查看API文档